Как сформировать из xml файла
Как создать XML файл: 3 простых способа
XML-формат предназначен для хранения данных, которые могут пригодиться в работе некоторых программ, сайтов и поддержки определённых языков разметки. Создать и открыть файл с таким форматом не сложно. Это вполне можно сделать, даже если на компьютере не установлено какое-либо специализированное программное обеспечение.
Немного об XML
Сам по себе XML — это язык разметки, чем-то похожий на HTML, который используется на веб-страницах. Но если последний применяется только для вывода информации и её правильной разметки, то XML позволяет её структурировать определённым образом, что делает этот язык чем-то похожим на аналог базы данных, который не требует наличия СУБД.
Создавать XML-файлы можно как при помощи специализированных программ, так и встроенным в Windows текстовым редактором. От вида используемого ПО зависит удобство написания кода и уровень его функциональности.
Способ 1: Visual Studio
Вместо этого редактора кода от Microsoft можно использовать любой его аналог от других разработчиков. По факту Visual Studio является более расширенной версией обычного «Блокнота». Код теперь имеет специальную подсветку, ошибки выделяются или исправляются автоматически, также в программу уже загружены специальные шаблоны, которые позволяют упростить создание XML-файлов больших объёмов.
Для начала работы вам нужно создать файл. Нажмите по пункту «Файл» в верхней панели и из выпадающего меню выберите «Создать…». Откроется список, где указывается пункт «Файл».
В только что созданном файле уже будет первая строка с кодировкой и версией. По умолчанию прописана первая версия и кодировка UTF-8, которые вы можете поменять в любое время. Дальше для создания полноценного XML-файла вам нужно прописать всё то, что было в предыдущей инструкции.
По завершении работы снова выберите в верхней панели «Файл», а там из выпадающего меню пункт «Сохранить всё».
Способ 2: Microsoft Excel
Можно создать XML-файл и не прописывая код, например, при помощи современных версий Microsoft Excel, который позволяет сохранять таблицы с данным расширением. Однако нужно понимать, что в этом случае создать что-то более функциональное обычной таблицы не получится.
Такой способ больше подойдёт тем, кто не хочет или не умеет работать с кодом. Однако в этом случае пользователь может столкнуться с определёнными проблемами при перезаписи файла в XML-формат. К сожалению, проделать операцию преобразования обычной таблицы в XML можно только на самых новых версиях MS Excel. Чтобы это сделать, используйте следующую пошаговую инструкцию:
- Заполните таблицу каким-либо контентом.
- Нажмите на кнопку «Файл», что в верхнем меню.
- Откроется специальное окно, где нужно нажать на «Сохранить как…». Этот пункт можно найти в левом меню.
- Укажите папку, куда необходимо сохранить файл. Папка указывается в центральной части экрана.
- Теперь вам нужно указать название файла, а в разделе «Тип файла» из выпадающего меню выбрать
«XML-данные». - Нажмите на кнопку «Сохранить».
Способ 3: Блокнот
Для работы с XML вполне подойдёт даже обычный «Блокнот», однако пользователю, который не знаком с синтаксисом языка, придётся трудно, так как в нём нужно прописывать различные команды и теги. Несколько проще и значительно продуктивнее процесс будет идти в специализированных программах для редактирования кода, например, в Microsoft Visual Studio. В них есть специальная подсветка тегов и всплывающие подсказки, что значительно упрощает работу человеку, плохо знакомому с синтаксисом этого языка.
Для этого способа не потребуется что-либо скачивать, так как в операционную систему уже встроен «Блокнот». Давайте попробуем сделать в нём простую XML-таблицу по данной инструкции:
- Создайте обычный текстовый документ с расширением TXT. Разместить его можно где угодно. Откройте его.
- Начните прописывать в нём первые команды. Для начала нужно задать всему файлу кодировку и указать версию XML, делается это следующей командой:
<?xml version="1.0" encoding="utf-8"?>Первое значение — это версия, её менять не обязательно, а второе значение — это кодировка. Рекомендуется использовать кодировку UTF-8, так как большинство программ и обработчиков работают с ней корректно. Однако её можно изменить на любую другую, просто прописав нужное название.
- Создайте первый каталог в вашем файле, прописав тег
<root>и закрыв его таким образом</root>. - Внутри этого тега теперь можно написать какой-нибудь контент. Создадим тег
<Employee>и присвоим ему любое имя, например, «Иван Иванов». Готовая структура должна быть такой:<Employee name="Иван Иванов"> - Внутри тега
<Employee>теперь можно прописать более подробные параметры, в данном случае это информация о неком Иване Иванове. Пропишем ему возраст и должность. Выглядеть это будет так:<Age>25</Age>
<Programmer>True</Programmer> - Если вы следовали инструкции, то у вас должен получиться такой же код, как ниже. По завершении работы в верхнем меню найдите «Файл» и из выпадающего меню выберите «Сохранить как…». При сохранении в поле «Имя файла» после точки должно стоять расширение не TXT, а XML.
Примерно так у вас должен выглядеть готовый результат:
<?xml version="1.0" encoding="utf-8"?>
<root>
<Employee name="Иван Иванов">
<Age>25</Age>
<Programmer>True</Programmer>
</Employee>
</root>
XML-компиляторы должны обработать этот код в виде таблицы с одной колонкой, где указаны данные о неком Иване Иванове.
В «Блокноте» вполне можно сделать несложные таблицы наподобие этой, но при создании более объёмных массивов данных могут возникнуть сложности, так как в обычном «Блокноте» нет функций исправления ошибок в коде или их подсветки.
Как видите в создании XML-файла нет ничего сложного. При желании его может создать любой пользователь, который более-менее умеет работать на компьютере. Однако для создания полноценного XML-файла рекомендуется изучить данный язык разметки, хотя бы на примитивном уровне.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТXML для начинающих - Служба поддержки Office
Вероятно, вы слышали о языке XML и вам известно множество причин, по которым его необходимо использовать в вашей организации. Но что именно представляет собой XML? В этой статье объясняется, что такое XML и как он работает.
В этой статье
-
Пометки, разметка и теги
-
Отличительные черты XML
-
Правильно сформированные данные
-
Схемы
-
Преобразования
-
XML в системе Microsoft Office
Пометки, разметка и теги
Для понимания языка XML он помогает понять смысл пометки данных. Люди создали документы для протяжении столетий, и пока они не пометили их в течение всего времени. Например, преподаватели замечают все время на учебные материалы для учащихся. Они указывают слушателям на то, что вы можете перемещать параграфы, прояснить предложения, исправлять опечатки и т. д. Пометка документа определяет структуру, значение и визуальное представление данных в документе. Если вы когда-нибудь использовали функцию "исправления" в Microsoft Office Word, вы использовали заметку, которая была установлена на компьютере.
В мире информационных технологий термин "пометка" превратился в термин "разметка". При разметке используются коды, называемые тегами (или иногда токенами), для определения структуры, визуального оформления и — в случае XML — смысла данных.
Текст этой статьи в формате HTML является хорошим примером применения компьютерной разметки. Если в Microsoft Internet Explorer щелкнуть эту страницу правой кнопкой мыши и выбрать команду Просмотр HTML-кода, вы увидите читаемый текст и теги HTML, например <p> и <h3>. В HTML- и XML-документах теги легко распознать, поскольку они заключены в угловые скобки. В исходном тексте этой статьи теги HTML выполняют множество функций, например определяют начало и конец каждого абзаца (<p> ... </p>) и местоположение рисунков.
Отличительные черты XML
Документы в форматах HTML и XML содержат данные, заключенные в теги, но на этом сходство между двумя языками заканчивается. В формате HTML теги определяют оформление данных — расположение заголовков, начало абзаца и т. д. В формате XML теги определяют структуру и смысл данных — то, чем они являются.
При описании структуры и смысла данных становится возможным их повторное использование несколькими способами. Например, если у вас есть блок данных о продажах, каждый элемент в котором четко определен, то можно загрузить в отчет о продажах только необходимые элементы, а другие данные передать в бухгалтерскую базу данных. Иначе говоря, можно использовать одну систему для генерации данных и пометки их тегами в формате XML, а затем обрабатывать эти данные в любых других системах вне зависимости от клиентской платформы или операционной системы. Благодаря такой совместимости XML является основой одной из самых популярных технологий обмена данными.
Учитывайте при работе следующее:
-
HTML нельзя использовать вместо XML. Однако XML-данные можно заключать в HTML-теги и отображать на веб-страницах.
-
Возможности HTML ограничены предопределенным набором тегов, общим для всех пользователей.
-
Правила XML разрешают создавать любые теги, требуемые для описания данных и их структуры. Допустим, что вам необходимо хранить и совместно использовать сведения о домашних животных. Для этого можно создать следующий XML-код:
<?xml version="1.0"?> <CAT> <NAME>Izzy</NAME> <BREED>Siamese</BREED> <AGE>6</AGE> <ALTERED>yes</ALTERED> <DECLAWED>no</DECLAWED> <LICENSE>Izz138bod</LICENSE> <OWNER>Colin Wilcox</OWNER> </CAT>
Как видно, по тегам XML понятно, какие данные вы просматриваете. Например, ясно, что это данные о коте, и можно легко определить его имя, возраст и т. д. Благодаря возможности создавать теги, определяющие почти любую структуру данных, язык XML является расширяемым.
Но не путайте теги в данном примере с тегами в HTML-файле. Например, если приведенный выше текст в формате XML вставить в HTML-файл и открыть его в браузере, то результаты будут выглядеть следующим образом:
Izzy Siamese 6 yes no Izz138bod Colin Wilcox
Веб-браузер проигнорирует теги XML и отобразит только данные.
Правильно сформированные данные
Вероятно, вы слышали, как кто-то из ИТ-специалистов говорил о "правильно сформированном" XML-файле. Правильно сформированный XML-файл должен соответствовать очень строгим правилам. Если он не соответствует этим правилам, XML не работает. Например, в предыдущем примере каждый открывающий тег имеет соответствующий закрывающий тег, поэтому в данном примере соблюдено одно из правил правильно сформированного XML-файла. Если же удалить из файла какой-либо тег и попытаться открыть его в одной из программ Office, то появится сообщение об ошибке и использовать такой файл будет невозможно.
Правила создания правильно сформированного XML-файла знать необязательно (хотя понять их нетрудно), но следует помнить, что использовать в других приложениях и системах можно лишь правильно сформированные XML-данные. Если XML-файл не открывается, то он, вероятно, неправильно сформирован.
XML не зависит от платформы, и это значит, что любая программа, созданная для использования XML, может читать и обрабатывать XML-данные независимо от оборудования или операционной системы. Например, при применении правильных тегов XML можно использовать программу на настольном компьютере для открытия и обработки данных, полученных с мейнфрейма. И, независимо от того, кто создал XML-данные, с ними данными можно работать в различных приложениях Office. Благодаря своей совместимости XML стал одной из самых популярных технологий обмена данными между базами данных и пользовательскими компьютерами.
В дополнение к правильно сформированным данным с тегами XML-системы обычно используют два дополнительных компонента: схемы и преобразования. В следующих разделах описывается, как они работают.
Схемы
Не пугайтесь термина "схема". Схема — это просто XML-файл, содержащий правила для содержимого XML-файла данных. Файлы схем обычно имеют расширение XSD, тогда как для файлов данных XML используется расширение XML.
Схемы позволяют программам проверять данные. Они формируют структуру данных и обеспечивают их понятность создателю и другим людям. Например, если пользователь вводит недопустимые данные, например текст в поле даты, программа может предложить ему исправить их. Если данные в XML-файле соответствуют правилам в схеме, для их чтения, интерпретации и обработки можно использовать любую программу, поддерживающую XML. Например, как показано на приведенном ниже рисунке, Excel может проверять данные <CAT> на соответствие схеме CAT.
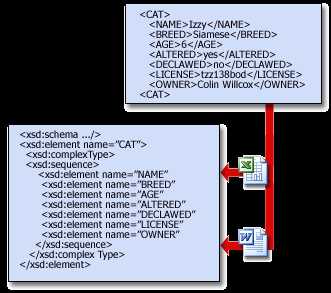
Схемы могут быть сложными, и в данной статье невозможно объяснить, как их создавать. (Кроме того, скорее всего, в вашей организации есть ИТ-специалисты, которые знают, как это делать.) Однако полезно знать, как выглядят схемы. Следующая схема определяет правила для набора тегов <CAT> ... </CAT>:
<xsd:element name="CAT">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="NAME" type="xsd:string"/>
<xsd:element name="BREED" type="xsd:string"/>
<xsd:element name="AGE" type="xsd:positiveInteger"/>
<xsd:element name="ALTERED" type="xsd:boolean"/>
<xsd:element name="DECLAWED" type="xsd:boolean"/>
<xsd:element name="LICENSE" type="xsd:string"/>
<xsd:element name="OWNER" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
Не беспокойтесь, если в примере не все понятно. Просто обратите внимание на следующее:
-
Строковые элементы в приведенном примере схемы называются объявлениями. Если бы требовались дополнительные сведения о животном, например его цвет или особые признаки, то специалисты отдела ИТ добавили бы к схеме соответствующие объявления. Систему XML можно изменять по мере развития потребностей бизнеса.
-
Объявления являются мощным средством управления структурой данных. Например, объявление <xsd:sequence> означает, что теги, такие как <NAME> и <BREED>, должны следовать в указанном выше порядке. С помощью объявлений можно также проверять типы данных, вводимых пользователем. Например, приведенная выше схема требует ввода положительного целого числа для возраста кота и логических значений (TRUE или FALSE) для тегов ALTERED и DECLAWED.
-
Если данные в XML-файле соответствуют правилам схемы, то такие данные называют допустимыми. Процесс контроля соответствия XML-файла данных правилам схемы называют (достаточно логично) проверкой. Большим преимуществом использования схем является возможность предотвратить с их помощью повреждение данных. Схемы также облегчают поиск поврежденных данных, поскольку при возникновении такой проблемы обработка XML-файла останавливается.
Преобразования
Как говорилось выше, XML также позволяет эффективно использовать и повторно использовать данные. Механизм повторного использования данных называется преобразованием XSLT (или просто преобразованием).
Вы (или ваш ИТ-отдел) можете также использовать преобразования для обмена данными между серверными системами, например между базами данных. Предположим, что в базе данных А данные о продажах хранятся в таблице, удобной для отдела продаж. В базе данных Б хранятся данные о доходах и расходах в таблице, специально разработанной для бухгалтерии. База данных Б может использовать преобразование, чтобы принять данные от базы данных A и поместить их в соответствующие таблицы.
Сочетание файла данных, схемы и преобразования образует базовую систему XML. На следующем рисунке показана работа подобных систем. Файл данных проверяется на соответствие правилам схемы, а затем передается любым пригодным способом для преобразования. В этом случае преобразование размещает данные в таблице на веб-странице.

В следующем примере кода показан один из способов написания преобразования. Данные> <CAT загружаются в таблицу на веб-странице. Опять же, на момент создания образца не показывается, как создать преобразование, но показать одну из них, которая может быть преобразована.
<?xml version="1.0"?>
<xsl:stylesheet version="1.0">
<TABLE>
<TR>
<TH>Name</TH>
<TH>Breed</TH>
<TH>Age</TH>
<TH>Altered</TH>
<TH>Declawed</TH>
<TH>License</TH>
<TH>Owner</TH>
</TR>
<xsl:for-each select="CAT">
<TR ALIGN="LEFT" VALIGN="TOP">
<TD>
<xsl:value-of select="NAME"/>
</TD>
<TD>
<xsl:value-of select="BREED"/>
</TD>
<TD>
<xsl:value-of select="AGE"/>
</TD>
<TD>
<xsl:value-of select="ALTERED"/>
</TD>
<TD>
<xsl:value-of select="DECLAWED"/>
</TD>
<TD>
<xsl:value-of select="LICENSE"/>
</TD>
<TD>
<xsl:value-of select="OWNER"/>
</TD>
</TR>
</xsl:for-each>
</TABLE>
В этом примере показано, как может выглядеть текст одного из типов преобразования, но помните, что вы можете ограничиться четким описанием того, что вам нужно от данных, и это описание может быть сделано на вашем родном языке. Например, вы можете пойти в отдел ИТ и сказать, что необходимо напечатать данные о продажах для конкретных регионов за последние два года, и что эти сведения должны выглядеть так-то и так-то. После этого специалисты отдела могут написать (или изменить) преобразование, чтобы выполнить вашу просьбу.
Корпорация Майкрософт и растущее число других компаний создают преобразования для различных задач, что делает использование XML еще более удобным. В будущем, скорее всего, можно будет скачать преобразование, отвечающее вашим потребностям без дополнительной настройки или с небольшими изменениями. Это означает, что со временем использование XML будет требовать все меньше и меньше затрат.
XML в системе Microsoft Office
Профессиональные выпуски Office обеспечивают всестороннюю поддержку XML. Начиная с Microsoft Office 2007, в Microsoft Office используются форматы файлов на основе XML, например DOCX, XLSX и PPTX. Поскольку XML-данные хранятся в текстовом формате вместо запатентованного двоичного формата, ваши клиенты могут определять собственные схемы и использовать ваши данные разными способами без лицензионных отчислений. Для получения дополнительных сведений о новых форматах ознакомьтесь с разрешениями в разделе форматы файлов Open XML и расширение имени файла. К другим преимуществам относятся:
-
Меньший размер файлов. Новый формат использует ZIP и другие технологии сжатия, поэтому размер файла на 75 процентов меньше, чем в двоичных форматах, применяемых в более ранних версиях Office.
-
Более простое восстановление данных и большая безопасность. Формат XML может быть легко прочитан пользователем, поэтому если файл поврежден, его можно открыть в Блокноте или другой программе для просмотра текста и восстановить хотя бы часть данных. Кроме того, новые файлы более безопасны, потому что они не могут содержать код Visual Basic для приложений (VBA). Если новый формат используется для создания шаблонов, то элементы ActiveX и макросы VBA находятся в отдельном, более безопасном разделе файла. Кроме того, можно удалять личные данные из документов с помощью таких средств, как инспектор документов. Дополнительные сведения об использовании инспектора документов можно найти в статье Удаление скрытых и персональных данных путем проверки документов.
Итак, но что делать, если у вас есть XML-данные без схемы? Программы Office, поддерживающие XML, обладают собственными подходами для облегчения работы с данными. Например, если вы открыли XML-файл, который еще не содержит, Excel выводит схему. После этого приложение Excel выдаст вам возможность загрузить эти данные в XML-таблицу. С помощью списков XML и таблиц можно сортировать, фильтровать данные и добавлять в них вычисления.
Включение средств XML в Office
По умолчанию вкладка "Разработчик" не отображается. Ее необходимо добавить на ленту для использования команд XML в Office.
Примечание: Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Была ли информация полезной? Для удобства также приводим ссылку на оригинал (на английском языке).
Собрать данные из XML файлов в Excel и экспортировать
Microsoft Excel – удобный инструмент для организации и структурирования самых разнообразных данных. Он позволяет обрабатывать информацию разными методами, редактировать массивы данных.
Рассмотрим возможности использования его для формирования и обработки файлов веб-приложений. На конкретном примере изучим основы работы с XML в Excel.
Как создать XML-файл из Excel
XML – стандарт файла для передачи данных в Сети. Excel поддерживает его экспорт и импорт.
Рассмотрим создание XML-файла на примере производственного календаря.
- Сделаем таблицу, по которой нужно создать XML файл в Excel и заполним ее данными.
- Создадим и вставим карту XML с необходимой структурой документа.
- Экспортируем данные таблицы в XML формат.
Итак.
- Наша таблица – производственный календарь.
- Создаем в любом текстовом редакторе (например, «Блокнот») желаемую карту XML структуры для генерации файла сохраним. В данном примере буде использовать следующую карту структуры:
- Открываем инструмент «Разработчик». Диалоговое окно «Источник» на вкладке XML.
- Если программа Excel не видит карт XML, их нужно добавить. Жмем «карты XML». И указываем путь к нашему файлу с выше указанной схемой карты созданной в текстовом редакторе.
- Добавить ОК.
- В правой колонке появляются элементы схемы. Их нужно перетащить на соответствующие названия столбцов таблицы.
- Проверяем возможен ли экспорт.
- Когда все элементы будут сопоставлены, щелкаем правой кнопкой мыши по любой ячейке в таблице – XML – экспорт.
Сохраняем в XML файл.
Другие способы получения XML-данных (схемы):
- Скачать из базы данных, специализированного бизнес-приложения. Схемы могут предоставляться коммерческими сайтами, службами. Простые варианты находятся в открытом доступе.
- Использовать готовые образцы для проверки карт XML. В образцах – основные элементы, структура XML. Копируете – вставляете в программу «Блокнот» - сохраняете с нужным расширением.
Как сохранить файл Excel в формате XML
Один из вариантов:
- Нажимаем кнопку Office. Выбираем «Сохранить как» - «Другие форматы».
- Назначаем имя. Выбираем место сохранения и тип файла – XML.
Сохранить.
Если выдает ошибку, книгу можно сохранить в виде таблицы XML 2003 либо веб-страницы. С этими форматами проблем, как правило, не возникает.
Еще варианты:
- Скачать конвертер XLC в XML. Либо найти сервис, с помощью которого можно экспортировать файл онлайн.
- Скачать с официального сайта Microsoft надстройку XML Tools Add-in. Она в бесплатном доступе.
- Открываем новую книгу. Кнопка Office – «Открыть».
Как открыть XML файл в Excel
- Меняем формат на «файлы XML». Выбираем нужный файл. Жмем «Открыть».
- Способ открытия – XML-таблица. ОК.
- Появляется оповещение типа
Жмем ОК. С полученной таблицей можно работать, как с любым файлом Excel.
Как преобразовать файл XML в Excel
- Меню «Разработчик» - вкладка «Импорт».
- В диалоговом окне выбираем файл XML, который хотим преобразовать.
- Нажимаем «Импорт». Программа Excel предложит самостоятельно создать схему на основе полученных данных. Соглашаемся – ОК. Откроется окно, где нужно выбрать место для импортируемого файла.
- Назначаем диапазон для импорта. Лучше брать с «запасом». Жмем ОК.
Созданную таблицу редактируем и сохраняем уже в формате Excel.
Как собрать данные из XML файлов в Excel
Принцип сбора информации из нескольких XML-файлов такой же, как и принцип преобразования. Когда мы импортируем данные в Excel, одновременно передается карта XML. В эту же схему можно переносить и другие данные.
Каждый новый файл будет привязываться к имеющейся карте. Каждому элементу в структуре таблицы соответствует элемент в карте. Допускается только одна привязка данных.
Чтобы настроить параметры привязки, откройте в меню «Разработчик» инструмент «Свойства карты».
Возможности:
- Каждый новый файл будет проверяться программой Excel на соответствие установленной карте (если поставим галочку напротив этого пункта).
- Данные могут обновляться. Либо новая информация добавится в существующую таблицу (имеет смысл, если нужно собрать данные из похожих файлов).
Это все ручные способы импорта и экспорта файлов.
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>И разберемся, что означает эта запись.

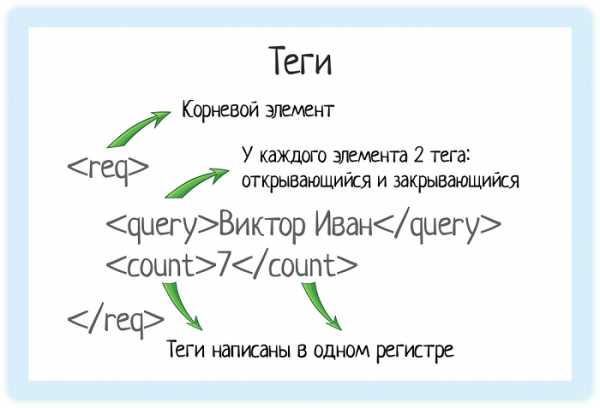
Теги
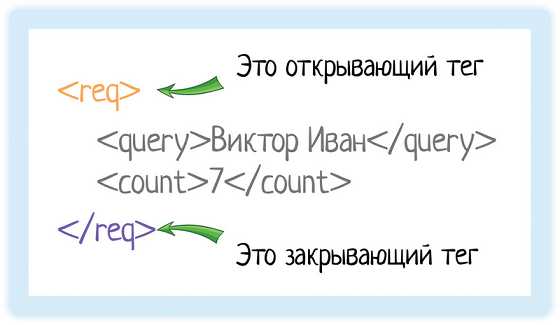
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag> - Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!

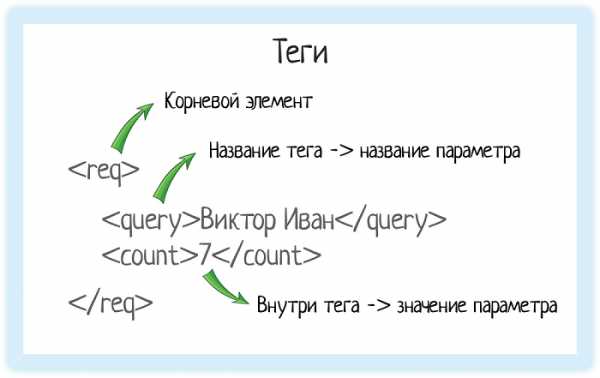
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».

Он мог бы называться по другому:
<main><sugg>Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.

Внутри — значение запроса.
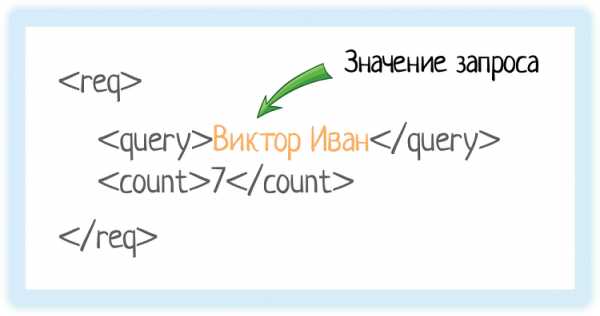
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
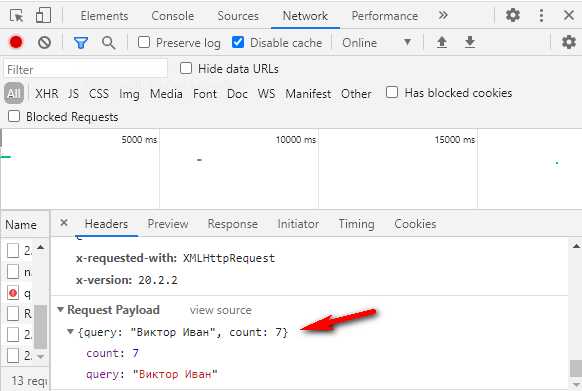
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2"> <field name=“name">Олег </field> <field name="birthdate">02.01.1980</field> <attribute type="PHONE" rawId="AL.2.PH.1"> <field name="type">MOBILE</field> <field name="number">+7 916 1234567</field> </attribute> </party>Давайте разберем эту запись. У нас есть основной элемент party.

У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!

Внутри party есть элементы field.

У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.

Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.

У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл...
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?

Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- ...
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.

Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!

А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.

Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister "> <xs:complexType> <xs:sequence> <xs:element name="email" type="xs:string"/> <xs:element name="name" type="xs:string"/> <xs:element name="password" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test"> <xsd:sequence> <xsd:element name="value" type="xsd:string"/> <xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/> <xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/> <xsd:element name="user" type="USER" minOccurs="0"/> </xsd:sequence> </xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name>Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
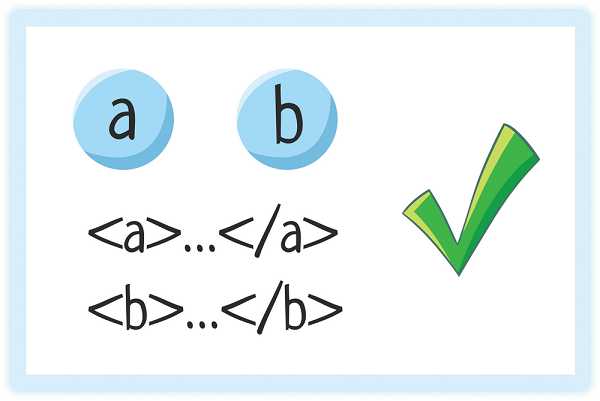
Один элемент может быть вложен в другой

Но накладываться друг на друга элементы НЕ могут!
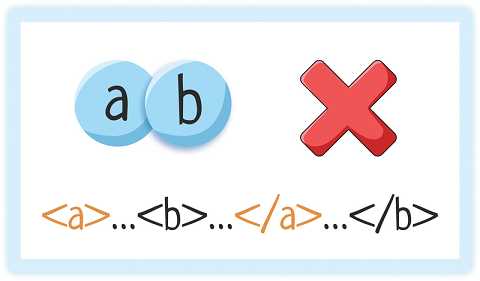
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Как создать файл XML, в какой программе, инструкция — Компьютер + Интернет + блог = Статьи, приносящие деньги
Сегодня я расскажу вам как, и главное, в чём создать файл XML. XML файл — это расширяемый язык разметки, Что это значит, простым языком, читайте далее.

Файлы xml используются во многих областях программирования. Данный формат позволяет создавать практически любые теги и декларации.
Файлы XML также используются для удобства обработки, хранения и передачи данных. Так, например, если у Интернет-сайта карта сохранена в XML, то на неё будет легче добавлять любую требующуюся информацию.
К примеру, это могут быть новые страницы и прочее. В этом материале вы узнаете, как происходит создание файлов в подобном формате.
Как создать файл XML
Если вам потребовалось создать файл XML, тогда можно воспользоваться одним из вариантов:
- Visual Studio.
- MS Excel.
- Блокнот и другие программы.
У каждого из вышеперечисленных способов имеется свои нюансы, с которыми стоит познакомиться поближе.
Создание файла XML в Visual Studio
Visual Studio – более улучшенная, многофункциональная версия «Блокнота».

Для её использования, сначала нужно скачать и установить программу, а затем:
- В левом верхнем углу программы, нужно нажать на «Файл» и выбрать пункт «Создать».
- Далее, в новом системном окне выбираете соответствующий тип файла и в правом нижнем углу нажимаете «Открыть».
- Затем прописываете всю необходимую информацию.
- Для сохранения данных выбираете «Сохранить всё».
Во время сохранения проследите, чтобы расширение было XML.
Как создать xml файл в Excel
Ещё одним способом, по созданию файла XML, является использование MS Excel:
- Сначала запускаете MS Excel и посредством использования одного из языков программирования вводите все требуемые команды в таблицу.
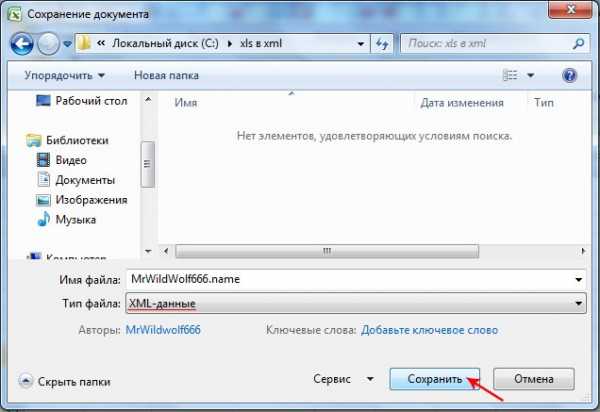
- Далее, в верхнем левом углу нажимаете на кнопку Microsoft Office и выбираете раздел «Сохранить как».
- В графе «Тип файла» из списка выбираете « XML-данные» и кликаете по «Сохранить».
Как создать xml файл в блокноте
Вариант создания файла формата XML через Блокнот, более сложный, по сравнению с ранее приведёнными способами.
В этом случае придётся самостоятельно прописывать все необходимые команды и теги.
Итак, чтобы создать XML-файл с помощью утилиты «Блокнот» потребуется:
- Сначала создаётся новый текстовый документ. То есть на рабочем столе или в любой папке, по пустому месту нужно щелкнуть правой клавишей мыши и выбрать пункт «Создать», а затем кликаете по «Текстовый документ».
- Далее задаётся кодировка файла с указанием его формата. Для этого используется следующая команда без кавычек: «<?xml version=”1.0” encoding=”utf-8”?>».
Затем создаётся первый каталог<root>. Для закрытия каталога применяется символ «/». Таким образом, на второй строчке документа прописываете тег </root>.
- Далее прописывается контент, для которого можно использовать тег <Employee> с присваиванием ему имени. Теперь тег будет выглядеть так: < Employee name=”имя”>. Здесь же можно добавить ещё дополнительные данные, которые должны вводиться с новой строки. Например, возраст <Age>20</Age> <Programmer>True</Programmer> и другие данные.
- Для закрытия тэга <Employee>, используется символ «/». Таким образом, тег примет следующий вид — </Employee>.
- Далее закрываете каталог при помощи символа «/». То есть, на второй строчке документа прописываете тег </root>.
- В конечном итоге должна получиться следующая запись:
<?xml version=”1.0” encoding=”utf-8”?>
<root>
< Employee name=”имя”>
<Age>20</Age>
<Programmer>True</Programmer>
</Employee>
</root>
- Для завершения работы в правом верхнем углу «Блокнота», нажимаете на «Файл» и выбираете «Сохранить как…». В графе «Имя файла», после точки указываете расширение XML и нажимаете на «Сохранить».
Блокнот хорошо использовать для небольших и несложных таблиц с командами для xml-файлов. Дело в том, что в данной утилите не предусмотрена возможность удаления и исправления ошибок в коде.
Также, ошибки не будут подсвечиваться и, соответственно, если файл небольшой, то найти недочёт не составит особого труда. То есть для более серьёзной работы с данным форматом, лучше воспользоваться другим способом.
Итог
Для решения вопроса о том, как создать файл XML, имеется несколько довольно простых способов. Кроме этого, не обязательно прописывать все команды самостоятельно.
Поскольку, при желании, можно воспользоваться специально предназначенными для этого компиляторами.
Как создать файл XML, видео
Рекомендую прочитать:
Интеграция XML данных — другой путь / Хабр
В данной статье описывается «нетрадиционная», но достаточно мощная технология обработки XML, позволяющая импортировать любые XML-данные и преобразовывать их структуру эффективно и просто, при этом один и тот же процесс обработки позволяет трансформировать исходные данные любой структуры без какого-либо изменения программного кода.XML как промежуточный формат обмена данными «оброс» экосистемой технологий и инструментов для работы с ним– специализированные редакторы, DOM-парсеры, XQUERY/XPATH, XSLT, специальные модули ETL и т. д. Все это многообразие и развитость инструментария идеологически приводят к тому, что у нас есть теперь технологии работы не просто с данными, а со специальными XML-данными. Это как отдельно «наука химия» и отдельно «наука химия для веществ, которые хранятся в синих коробках».
Описываемые далее принципы обработки позволили немножко «отмотать назад» условный прогресс технологий и перевести практически всю работу с XML данными на уровень «чистой» СУБД, без специфичного XML-инструментария. Такой подход дал возможность организовать унифицированное хранение любых XML-данных и обеспечить быстрый произвольный доступ к нужным частям информации. Кроме того, появилась возможность реализовывать ETL-функционал универсальным незатратным (практически без кодирования) способом.
Описываемый подход особенно хорошо показал себя на источниках данных большого объема и сложной структуры, с частыми изменениями схемы данных. Если вам приходится иметь дело с небольшим объемом информации, и/или структура несложная– возможно, данная технология вам (пока) не нужна.
Хорошим демо-кейсом для этой технологии могут служить открытые данные сервера госзакупок zakupki.gov.ru, доступные на соответствующем FTP: объём ежедневных обновлений – десятки и сотни тысяч XML файлов объемом в гигабайты или десятки гигабайт, в среднем раз в несколько недель выходит новая версия схемы данных.
Структура данных следует за требованиями законодательства, поэтому, например, информация об извещениях о проведении госзакупок представлена более чем десятком типов документов fcsNotification* в зависимости от типа закупки (электронный аукцион fcsNotificationEF, запрос котировок fcsNotificationZK, закупка у единственного поставщика fcsNotificationEP и т. п.)
Все эти документы основаны на одном базовом типе извещения но отличаются в деталях, поэтому для целей анализа все это многообразие при импорте надо в какой-то момент “схлопывать” и приводить к «единому знаменателю».
На данных госзакупок описываемый подход успешно применен и эффективно работает.
Кратко этапы/элементы описываемой технологии:
(1) Импорт всех XML данных в таблицу унифицированной структуры. Речь не идет о сохранении в базу документов целиком, мы импортируем данные поэлементно как пары “имя элемента” – “значение” или “имя атрибута” – “значение”. В результате данного этапа мы избавляемся от XML как формата хранения и получаем быстрый унифицированный доступ к данным всех импортированных XML-документов любой структуры (при этом нам больше не нужен XQUERY/XPATH).
(2) Вторым элементом технологии является создание спецификаций на “вытаскивание” нужных нам данных – выявление результирующих таблиц, в которые мы будем выливать данные, и маппинг полей источника и результата. Этот этап может быть проведен как на основе XSD-схем документов, так и без использования схем, через анализ закачанных на первом этапе образцов документов. Данный этап не требует никакого программирования и специальных навыков, основной инструментарий здесь – электронная таблица.
(3) Завершающие шаги – выборка нужной информации из первичного хранилища импорта (1) с помощью спецификаций (2), преобразование в “колоночное” представление (“пивотирование”) и автоматизированная трансформация в финальный “аналитический” формат – в терминах аналитических хранилищ данных это таблицы фактов структуры “звездочка” (star) со ссылками на справочники измерений (dimensions) и числовыми показателями-мерами (measures).
1. Первичный импорт.
Мы рассматриваем XML-документ как дерево, вершинами которого являются пары “имя”-“значение”. Таким образом, описываемый подход достаточно универсален и может быть применен к любому древовидному представлению данных.
Структура таблицы для загрузки данных из XML:
- Record_ID: идентификатор элемента специального иерархического вида, позволяющий связывать друг с другом разные уровни документа
- File_ID: поскольку в таблицу надо будет загружать содержимое множества XML-файлов, надо также хранить идентификатор файла
- Path: полный путь к данному элементу начиная с корня документа (фактически, это XPATH-путь до данного элемента)
- Element_Name: название элемента или атрибута
- Element _Value: значение элемента или атрибута (в виде строки – так же, как оно хранится в XML)
- Type: тип записи (элемент это или атрибут) – сохраним на всякий случай, вдруг потом надо будет из таблицы восстановить XML
Идея загрузки дерева в таблицу достаточно очевидная. В MS SQL (про другие СУБД не скажу, не смотрел) есть такая встроенная возможность –XML без указания схемы импортируется в так называемую EDGE-таблицу. Это не совсем то что нам нужно, т. к. в EDGE-формате хранятся отдельными записями имя элемента и его значение (то есть имя есть родительская запись для значения) – такой формат попросту неудобно использовать для дальнейших манипуляций. К тому же в EDGE таблице связи в дереве прописаны через указание ParentID.
Короче говоря, сделать нужное представление данных из EDGE таблицы можно, но придется немножко попотеть для “склеивания” названий и значений элементов, воссоздания XPATH до каждого элемента и создания иерархического идентификатора (о том, как мы его будем строить – чуть ниже). При большом объеме данных решение этих задач может оказаться довольно ресурсоемким, но зато можно обойтись единственным инструментом/языком.
Более правильный путь – получить дерево документа с помощью XML-парсера (какая-нибудь реализация есть практически в каждом языке и среде разработки) и заполнить нужную информацию одним проходом по документу.
Давайте посмотрим на конкретный пример. Есть у нас демо XML-файлы deliveries.xml и returns.xml. Файл deliveries.xml (доставки) содержит корневой элемент Deliveries, на верхнем уровне даты начала и окончания периода за который выгружены данные, дальше идут продукты с указанием названия и поставщика, по каждому продукту идет детализация информации доставок – дата, количество, цена.
deliveries.xml<Deliveries> <PeriodBegin>2017-01-01</PeriodBegin> <PeriodEnd>2017-01-31</PeriodEnd> <Products> <Product> <Supplier>Zaanse Snoepfabriek</Supplier> <ProductName>Chocolade</ProductName> <Details> <Detail> <DeliveryDate>2017-01-03</DeliveryDate> <UnitPrice>10.2000</UnitPrice> <Quantity>70</Quantity> </Detail> </Details> </Product> <Product> <Supplier>Mayumi's</Supplier> <ProductName>Tofu</ProductName> <Details> <Detail> <DeliveryDate>2017-01-09</DeliveryDate> <UnitPrice>18.6000</UnitPrice> <Quantity>12</Quantity> </Detail> <Detail> <DeliveryDate>2017-01-13</DeliveryDate> <UnitPrice>18.7000</UnitPrice> <Quantity>20</Quantity> </Detail> </Details> </Product> </Products> </Deliveries> Файл returns.xml (возвраты) абсолютно аналогичный, только корневой элемент называется Returns и в деталях элемент с датой по-другому называется.returns.xml
<Returns> <PeriodBegin>2017-02-01</PeriodBegin> <PeriodEnd>2017-02-28</PeriodEnd> <Products> <Product> <Supplier>Pavlova, Ltd.</Supplier> <ProductName>Pavlova</ProductName> <Details> <Detail> <ReturnDate>2017-02-21</ReturnDate> <UnitPrice>13.9000</UnitPrice> <Quantity>2</Quantity> </Detail> </Details> </Product> <Product> <Supplier>Formaggi Fortini s.r.l.</Supplier> <ProductName>Mozzarella di Giovanni</ProductName> <Details> <Detail> <ReturnDate>2017-02-27</ReturnDate> <UnitPrice>27.8000</UnitPrice> <Quantity>4</Quantity> </Detail> </Details> </Product> </Products> </Returns> Имена загруженных файлов хранятся в отдельной таблице, коды наших файлов там равны 2006 (deliveries) и 2007 (returns).
В нашей таблице-приемнике образ наших демо-документов будет выглядеть так:
(Тут не все, только начало таблицы)| Record_ID | File_ID | Path | Element_Name | Element_Value | Type |
| 001 | 2006 | Deliveries | E | ||
| 001\001 | 2006 | Deliveries\ | PeriodBegin | 2017-01-01 | E |
| 001\002 | 2006 | Deliveries\ | PeriodEnd | 2017-01-31 | E |
| 001\003 | 2006 | Deliveries\ | Products | E | |
| 001\003\001 | 2006 | Deliveries\Products\ | Product | E | |
| 001\003\001\001 | 2006 | Deliveries\Products\ Product\ |
Supplier | Zaanse Snoepfabriek | E |
| 001\003\001\002 | 2006 | Deliveries\Products\ Product\ |
ProductName | Chocolade | E |
| 001\003\001\003 | 2006 | Deliveries\Products\ Product\ |
Details | E | |
| 001\003\001\003\ 001 |
2006 | Deliveries\Products\ Product\Details\ |
Detail | E | |
| 001\003\001\003\ 001\001 |
2006 | Deliveries\Products\ Product\Details\Detail\ |
DeliveryDate | 2017-01-03 | E |
| 001\003\001\003\ 001\002 |
2006 | Deliveries\Products\ Product\Details\Detail\ |
UnitPrice | 10.2000 | E |
| 001\003\001\003\ 001\003 |
2006 | Deliveries\Products\ Product\Details\Detail\ |
Quantity | 70 | E |
По поводу иерархического идентификатора Record_ID: его цель — уникально пронумеровать узлы дерева документа с сохранением информации о связях со всеми предками. К сведению:
В том же SQL Server есть специальный тип данных (объектное расширение) под названием hierarchyid, служащий для этих целей.
В приведенном примере мы используем простую платформенно-независимую реализацию c последовательной конкатенацией счетчиков элементов на каждом уровне дерева. Мы “добиваем” счетчик каждого уровня нулями до заданной фиксированной глубины, чтобы получить легкое и быстрое выделение идентификаторов предков любого уровня через выделение подстрок фиксированной длины.
Вот собственно и все на этом этапе. Теперь мы можем простыми SQL-запросами выделить подмножества данных продуктов, деталей по доставкам или возвратам и связать их друг с другом через идентификаторы файлов и элементов.
Во многих случаях этого подхода будет вполне достаточно для эффективного хранения данных и организации доступа к ним, описанные далее “продвинутые” техники могут не понадобиться.
Действительно, мы уже загрузили все наши данные в единое хранилище, не обращая внимания на возможную разницу в структуре документов, получили достаточно эффективный способ вычленять нужную информацию из всего массива простыми SQL-запросами, можем связывать между собой “вычлененные” подмножества данных.
Производительность такого решения как системы хранения исходников XML для разовых запросов, даже без оптимизации индексов и прочих ухищрений, будет явно гораздо выше, чем если бы вы хранили XML в файлах или даже записывали его в специальные поля БД. В нашем случае не надо запускать процедуру XPATH поиска (которая подразумевает новый парсинг) к каждому документу, мы это проделали один раз и дальше спокойно пользуемся сохраненным результатом через достаточно простые запросы.
Однако:На этом этапе мы пока не сделали так, чтобы DeliveryDate, Quantity и UnitPrice стали полями одной таблицы, это описывается как процесс “пивотирования” в третьем разделе.
На следующих этапах мы рассмотрим трансформацию этих XML документов в единую структуру данных, содержащую 3 таблицы: MovementReports (тип движения – доставка или возврат, даты начала и окончания из корня документа), Products (название и поставщик) и MovementDetails (цена, количество, дата – поле даты в результате будет единое для обоих исходных документов, несмотря на то, что в исходных файлах поля по-разному называются)
2. Создание спецификаций трансформации в результирующие таблицы.
Рассмотрим процесс создания спецификаций на маппинг исходных данных и результирующих таблиц. Для создания таких спецификаций нам потребуется еще кое-что.
2.1. Получение таблички со структурой документов.
Для дальнейшей обработки нужно иметь развернутую структуру всех наших XML-документов, чтобы на ее основе решать в какую структуру таблиц мы все это будем преобразовать.
Одного конкретного образца XML-документа для этой задачи нам мало, в конкретном документе может не быть каких-то необязательных элементов, которые неожиданно обнаружатся в других документах.
Если у нас нет XSD-схемы или мы не хотим с ней связываться, то нам может быть достаточно загрузить в нашу таблицу какую-то репрезентативную выборку образцов XML-документов и построить с помощью группировки по полям Path и Element_Name нужный нам список.
Однако не забывайте, что мы хотим в итоге загрузить информацию в некие целевые “финальные” таблицы, поэтому нам надо знать где в XML хранятся отношения один-ко-многим. То есть надо понять какие элементы формируют “дочернюю” таблицу, где происходит размножение.
Иногда, если схема документа не очень сложная, нам это сразу понятно эмпирически, “глазками”. Также при группировке данных нашей “репрезентативной выборки” мы можем посчитать количество элементов и увидеть по этой статистике где они начинают “размножаться”. Но в общем случае, если у нас есть нормальная XSD-схема, лучше воспользоваться ей – размножение данных один ко многим мы “поймаем”, выявив XSD конструкцию maxoccurs=unbounded.
Как видим, задача немного усложняется: хочется получить не только простую табличку, содержащую список XPATH-путей для всех элементов наших документов, но еще и с указанием того, где начинается размножение данных. (А при анализе хорошо прописанной XSD-схемы приятном бонусом могли бы получить возможность вытащить описания элементов и их типы.)
Очень хорошо было бы для получения такой таблички использовать функциональность какого-нибудь XML-редактора, однако найти такой инструмент, который бы выдавал нужную нам структуру документов по XSD-схеме, не удалось (искали и пробовали долго).
Во всех этих Oxygen, Altova, Liquid и менее навороченных нужная информация внутри, несомненно, используется – однако отдавать ее в нужном виде никто из них не умеет. Как правило, в продвинутом редакторе есть возможность генерировать Sample XML на основании схемы, но в XSD может быть конструкция choice, когда в документе может присутствовать что-то на выбор из нескольких разных элементов –тогда уж лучше реальные “боевые” образцы документов проанализировать. И еще — по образцу или образцам документов мы момент размножения информации один-ко-многим в явном виде тоже не поймаем.
В итоге пришлось изобретать велосипед и писать генератор такой таблички (фактически, парсер XSD специального вида) самостоятельно. Благо XSD это тоже XML, его можно так же загрузить в наше хранилище и реляционными операциями вытащить нужный вид. Если схема простая, без ссылок на сложные типы элементов и без наследования от базовых типов, то это достаточно просто. В случае, когда все это наследование типов в наличии (как в госзакупках, например), задача посложнее.
Для нашего примера мы получим примерно вот такую таблицу структуры документов:| Path | Element_Name | maxoccurs |
| Deliveries\ | PeriodBegin | |
| Deliveries\ | PeriodEnd | |
| Deliveries\Products\Product\ | ProductName | Products\Product |
| Deliveries\Products\Product\ | Supplier | Products\Product |
| Deliveries\Products\Product\Details\Detail\ | DeliveryDate | Products\Product\Details\Detail |
| Deliveries\Products\Product\Details\Detail\ | Quantity | Products\Product\Details\Detail |
| Deliveries\Products\Product\Details\Detail\ | UnitPrice | Products\Product\Details\Detail |
| Returns\ | PeriodBegin | |
| Returns\ | PeriodEnd | |
| Returns\Products\Product\ | ProductName | Products\Product |
| Returns\Products\Product\ | Supplier | Products\Product |
| Returns\Products\Product\Details\Detail\ | Quantity | Products\Product\Details\Detail |
| Returns\Products\Product\Details\Detail\ | ReturnDate | Products\Product\Details\Detail |
| Returns\Products\Product\Details\Detail\ | UnitPrice | Products\Product\Details\Detail |
2.2. Описание трансформации
Получив исходные данные в виде табличной спецификации документов, переходим к дизайну трансформации данных. В результате этой трансформации мы преобразуем данные нашего исходного хранилища первичного XML в новые таблицы с новыми именами полей и уникальными кодами записей целевых таблиц. Нам не нужны какие-то специальные программные инструменты, просто добавим к этой табличке несколько новых столбцов:В приведенном примере некоторые поля представлены с сокращениями для улучшения читабельности.
| Path | Element_ Name |
maxoccurs | Target Table |
Target Field |
Element Depth |
Additional Info |
| Deliveries\ | PeriodBegin | MovementReports | PeriodBegin_Date | 1 | Deliveries | |
| Deliveries\ | PeriodEnd | MovementReports | PeriodEnd_Date | 1 | Deliveries | |
| Deliveries\...\Product\ | ProductName | …\Product | Products | ProductName_Dim | 3 | |
| Deliveries\...\Product\ | Supplier | …\Product | Products | Supplier_Dim | 3 | |
| Deliveries\...\...\...\Detail\ | DeliveryDate | …\Detail | MovementDetails | MovementDate_Date | 5 | |
| Deliveries\...\...\...\Detail\ | Quantity | …\Detail | MovementDetails | Quantity_Val | 5 | |
| Deliveries\...\...\...\Detail\ | UnitPrice | …\Detail | MovementDetails | UnitPrice_Val | 5 | |
| Returns\ | PeriodBegin | MovementReports | PeriodBegin_Date | 1 | Returns | |
| Returns\ | PeriodEnd | MovementReports | PeriodEnd_Date | 1 | Returns | |
| Returns\...\Product\ | ProductName | …\Product | Products | ProductName_Dim | 3 | |
| Returns\...\Product\ | Supplier | …\Product | Products | Supplier_Dim | 3 | |
| Returns\...\...\...\Detail\ | Quantity | …\Detail | MovementDetails | MovementDate_Date | 5 | |
| Returns\...\...\...\Detail\ | ReturnDate | …\Detail | MovementDetails | Quantity_Val | 5 | |
| Returns\...\...\...\Detail\ | UnitPrice | …\Detail | MovementDetails | UnitPrice_Val | 5 |
Вот какие поля мы добавили:
- Имя целевой таблицы TargetTable. Обратите внимание, что мы учитываем информацию о размножении один-ко-многим (столбец maxoccurs) для определения, в какую таблицу какие данные заливать.
- Имя поля целевой таблицы TargetField. Мы далее используем подход сonvention over configuration и будем присваивать суффикс _Dim для полей, которые станут справочниками-измерениями (dimensions), суффикс _Date для полей дат и суффикс _Val для числовых полей- мер (measures). На следующих этапах процесса соответствующие утилиты по суффиксу поймут что делать с данным полем – строить и обновлять нужный справочник или преобразовывать значение в соответствующий формат.
- Эффективная глубина вложенности элементов ElementDepth. Нам надо будет для последующих трансформаций сохранить единый код записи целевой таблицы на базе содержимого полей Record_ID и File_ID. В XML глубина элементов может быть разной, но попадать они должны будут в одну целевую таблицу, поэтому мы указываем, какую часть иерархического кода Record_ID нам надо сохранить, отбросив ненужный нам остаток. Благодаря фиксированной длине каждого сегмента иерархического кода, это будет достаточно “дешевая” операция выделения подстрок длины [Количество символов на сегмент кода]* ElementDepth.
- Дополнительная информация AdditionalInfo. В результате нашей трансформации мы перегрузим исходные данные в разбивке по целевым таблицам в похожую структуру с новыми названиями полей, однако в некоторых местах нам надо будет сохранить важную информацию о том, из какого именно XPATH-пути мы брали исходные данные.
Эта техника открывает несколько интересных возможностей манипуляции трансформацией данных. Не углубляясь в детали, просто перечислим что мы можем сделать:
- Если у нас есть несколько исходных схем кодирования XML-данных (например, “старая” схема госзакупок по 95 ФЗ и “новая” по 44 ФЗ), мы можем на этапе описания трансформации привести их к единой структуре данных через унификацию названий полей.
- Можем, как упоминалось ранее, “схлопнуть” разные разделы в рамках одной или нескольких схем документов в единую, более компактную структуру хранения, как мы это делаем в нашем примере.
- Можно также “схлопнуть” в единообразное представление данные разной глубины. Например, если брать схемы извещений о проведении госзакупок, то в разных схемах информация о лотах закупки может лежать “по адресу” \lot для однолотовых закупок (единственный элемент) и \lots\lot для многолотовых закупок (размножение). С помощью данного подхода можно достаточно просто весь этот зоопарк замаппить в единую таблицу информации о лотах.
После того, как наша табличка со спецификацией трансформации готова, мы загружаем ее в базу данных и джойним с нашим первичным хранилищем по полям Path и Element_Name.
Конкатенацией File_ID, “обрезанного” в соответствии с ElementDepth значения поля Record_ID и значения AdditionalInfo формируем композитный ключ нашей целевой таблицы.
Результат джойна выливаем для каждой целевой таблицы в отдельную “временную” таблицу (в зависимости от объема данных можно попробовать использовать результат запроса “ на лету ”), на следующем этапе с этими таблицами будут работать завершающие утилиты нашего “конвейера”.
Немного подробнее о композитном ключе, может быть, немного повторяясь – но это важный и тонкий момент:- До выливки мы имеем набор данных на уровне отдельных полей (элементов). Для того, чтобы соединить поля в записи результирующей таблицы, нам нужно иметь какой-то ключ, который будет однозначно идентифицировать запись целевой таблицы, в которую попадут соответствующие поля.
- Иерархический идентификатор Record_ID может быть разной длины, в зависимости от “глубины залегания” отдельных элементов в схеме документа. Однако, если углубление уровня не сопровождается размножением элементов один-ко-многим, мы обрезаем наш Record_ID до минимальной достаточной глубины, определенной параметром ElementDepth, что обеспечит нам одинаковость идентификатора для всех полей нашей целевой таблицы. В наших демо-документах такой ситуации нет, но представьте, к примеру, что наш UnitPrice “разветвлялся” бы на 2 значения – оптовую и розничную цены UnitPrice\Retail и UnitPrice\Wholesale.
- Поскольку в нашем базовом хранилище лежит содержимое множества файлов, в нашем ключе без значения File_ID не обойтись.
- Следующие этапы преобразования данных работают только с полученными на данном шаге “трансформированными” таблицами, никакой сквозной системы настроек у нас нет. Тип поля (dimension/measure) мы передаем через суффиксы названий, но иногда нам надо передать “по цепочке” еще и информацию о том, в каком именно разделе документа мы брали информацию (помним, что мы можем трансформировать в одинаковый вид документы, закодированные разными схемами). Для передачи на следующий этап преобразования этой информации мы используем необязательный параметр нашей трансформации AdditionalInfo, “подцепив” его к нашему композитному ключу так, чтобы не нарушилась нужная нам идентификация целевых записей.
Посмотрим, что получилось на выходе в нашем примере:Результат трансформации:MovementReports:
| KEY | TargetField | Element_Value |
| 001;2006@Deliveries | PeriodBegin_Date | 2017-01-01 |
| 001;2006@Deliveries | PeriodEnd_Date | 2017-01-31 |
| 001;2007@Returns | PeriodBegin_Date | 2017-02-01 |
| 001;2007@Returns | PeriodEnd_Date | 2017-02-28 |
Products:
| KEY | TargetField | Element_Value |
| 001\003\001;2006 | Supplier_Dim | Zaanse Snoepfabriek |
| 001\003\001;2006 | ProductName_Dim | Chocolade |
| 001\003\002;2006 | Supplier_Dim | Mayumis |
| 001\003\002;2006 | ProductName_Dim | Tofu |
| 001\003\001;2007 | Supplier_Dim | Pavlova, Ltd. |
| 001\003\001;2007 | ProductName_Dim | Pavlova |
| 001\003\002;2007 | Supplier_Dim | Formaggi Fortini s.r.l. |
| 001\003\002;2007 | ProductName_Dim | Mozzarella di Giovanni |
MovementDetails:
| KEY | TargetField | Element_Value |
| 001\003\001\003\001;2006 | MovementDate_Date | 2017-01-03 |
| 001\003\001\003\001;2006 | UnitPrice_Val | 10.2000 |
| 001\003\001\003\001;2006 | Quantity_Val | 70 |
| 001\003\002\003\001;2006 | MovementDate_Date | 2017-01-09 |
| 001\003\002\003\001;2006 | UnitPrice_Val | 18.6000 |
| 001\003\002\003\001;2006 | Quantity_Val | 12 |
| 001\003\002\003\002;2006 | MovementDate_Date | 2017-01-13 |
| 001\003\002\003\002;2006 | UnitPrice_Val | 18.7000 |
| 001\003\002\003\002;2006 | Quantity_Val | 20 |
| 001\003\001\003\001;2007 | MovementDate_Date | 2017-02-21 |
| 001\003\001\003\001;2007 | UnitPrice_Val | 13.9000 |
| 001\003\001\003\001;2007 | Quantity_Val | 2 |
| 001\003\002\003\001;2007 | MovementDate_Date | 2017-02-27 |
| 001\003\002\003\001;2007 | UnitPrice_Val | 27.8000 |
| 001\003\002\003\001;2007 | Quantity_Val | 4 |
Обратите внимание – полученный ключ одинаков для всех полей, которые войдут в соответствующие записи наших целевых таблиц.
3. Финальная обработка.
3.1. Пивотирование
Получив в результате предыдущей трансформации “заготовку” целевой таблицы с исходными данными, разбитыми на тройки <ключ>-<имя поля>-<значение>, мы должны перевести ее в более привычный вид таблицы со множеством полей. Алгоритм этого преобразования очевиден – сначала группировкой значений нашего композитного ключа получаем “скелет” таблицы, потом осуществляем джойны этого “скелета” с таблицей-результатом трансформации по значению композитного ключа. (“Наращиваем мясо”, так сказать.)
То есть получится N соединений “скелета” с подмножествами таблицы- результата трансформации, выделенными по именам полей, где N- количество названий полей в целевой таблице-результате трансформации.
Мы благополучно “донесли” поле AdditionalInfo до данной стадии, закодировав его внутри композитного ключа. Теперь надо освободить наш ключ от этой “обузы” и отрезать AdditionalInfo-часть в новое поле AdditionalInfo_Dim.
Мы соединяли код файла и идентификатор записи, чтобы передать на этап пивотирования ключ одним полем. Для “финального” хранения лучше обратно разделить код файла и иерархический идентификатор на два поля, так будет проще связывать результирующие таблицы друг с другом.
В итоге получатся такие вот
pivot-таблички:MovementReports:| Record_ID | File_ID | AdditionalInfo_Dim | PeriodBegin_Date | PeriodEnd_Date |
| 001 | 2006 | Deliveries | 2017-01-01 | 2017-01-31 |
| 001 | 2007 | Returns | 2017-02-01 | 2017-02-28 |
Products:
| Record_ID | File_ID | Supplier_Dim | ProductName_Dim |
| 001\003\001 | 2006 | Zaanse Snoepfabriek | Chocolade |
| 001\003\002 | 2006 | Mayumis | Tofu |
| 001\003\001 | 2007 | Pavlova, Ltd. | Pavlova |
| 001\003\002 | 2007 | Formaggi Fortini s.r.l. | Mozzarella di Giovanni |
MovementDetails:
| Record_ID | File_ID | MovementDate_Date | UnitPrice_Val | Quantity_Val |
| 001\003\001\003\001 | 2006 | 2017-01-03 | 10.2000 | 70 |
| 001\003\001\003\001 | 2007 | 2017-02-21 | 13.9000 | 2 |
| 001\003\002\003\001 | 2006 | 2017-01-09 | 18.6000 | 12 |
| 001\003\002\003\001 | 2007 | 2017-02-27 | 27.8000 | 4 |
| 001\003\002\003\002 | 2006 | 2017-01-13 | 18.7000 | 20 |
3.2. Нормализация
Следующий этап условно можно назвать нормализацией, мы заменим все поля с суффиксом _Dim ссылками на соответствующие справочники, поля с суффиксами _Date и _Val преобразуем, соответственно, в даты и числа. Можно при необходимости и другие суффиксы типов данных использовать, это не догма.
Для каждого поля _Dim мы проверим наличие соответствующего справочника (если справочника нет, то создадим его) и дополним новыми значениями из поля пивотированной таблицы.
В конце процесса перельем данные в финальную структуру хранения, соединив пивотированную таблицу с проапдейченными справочниками по значениям полей.
В итоге мы получим наши целевые таблицы, в которых будет содержаться код файла, иерархический идентификатор, ссылки на значения справочников и преобразованные к нужным типам остальные поля.
В заключение описания процесса
Иерархический идентификатор в каждой целевой таблице дает нам возможность связать эти таблицы друг с другом (причем в любом порядке, при необходимости можно опускать промежуточные звенья). Как отмечалось выше, фиксированный размер элементов иерархического идентификатора дает нам возможность достаточно легко строить выражения для связывания наших целевых таблиц.
Конечно же, при желании можно дополнить структуру таблиц связями через значения привычных автоинкрементных ключей.
Отметим достаточную толерантность описанного подхода к ошибкам и упущениям разработчика (точнее, человека, конфигурирующего маппинг). Если в процессе подготовки трансформации вы упустили нужное поле, или если в схеме файлов произошли изменения типа добавления или переименования полей, которые не были отслежены вовремя – ничего страшного, даже если большой объем информации уже обработан без учета этой ошибки.
Вся информация у нас сохранена и доступна в нашем “первичном” табличном хранилище, поэтому заново парсить исходники не придется.
Можно прописать маппинг полей для «маленькой» трансформации данных – только для нужного нам пропущенного фрагмента. После того как мы “вытащим” недостающий кусок данных, мы сможем достаточно легко “подцепить” его к основному обработанному массиву через связку по иерархическому идентификатору.
Выводы
Как видим, мы с самого начала поместили всю исходную информацию вне зависимости от схем документов в единообразный вид, позволяющий быстро “вытаскивать” нужные данные в режиме ad-hoc.
В процессе дальнейшей обработки ни одно животное не пострадало не возникло необходимости в создании или модификации каких-либо скриптов или объектов типа ETL task, специфичных для структуры исходных XML-файлов.
Конечно, само программное окружение нашего “фреймворка” (инфраструктуру закачки и переливок данных) нужно было создать один раз, но затем интеграция данных любых структур XML сводится к редактированию таблицы маппинга исходного и целевого представлений.
Как сгенерировать образцы XML-документов из их DTD или XSD?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
рубинов на рельсах - как сгенерировать XML из XMLBuilder, используя файл .xml.builder?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
c # - Как сгенерировать XML-файл с определенной структурой из таблиц данных?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд
sql - Как сгенерировать XML-файл в Excel с данными из внешнего источника?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
как сгенерировать XML-файл с использованием PHP
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где девелоперы и технологи делят приват