Как узнать в какой программе создан файл
Как узнать, какой программе принадлежит файл на компьютере
Как определить принадлежность файла на компьютере
Файлы обычно имеют имя и расширение, сложилось так, что таким образом легче с ними работать. Файлы практически в любой операционной системе различаются по его расширению. Но, и не так редки случаи, когда операционные системы распознают файлы по содержимому, а не ориентируются на имена и расширения, хотя чаще, всё происходит наоборот. Поэтому и определяется важность учёта расширений файлов.
Какой файл, точнее, с каким расширением какой программе подходит или принадлежит, не всегда можно однозначно определить. Например, лог-файлы может создавать практически любая программа и никакой привязки к хозяину файл не имеет, если разработчик программы не позаботился о том, чтобы было легче идентифицировать хозяина.
Криминала особого в том нет, если какой-то файл невозможно однозначно идентифицировать, и он оказался потеряшкой. Важнее содержимое файла, когда не ясно, чей он и кому нужен. Но. В операционных системах действуют ассоциации по «типам» файлов с конкретными прикладными программами. Изменить привязку файла к программе может сам пользователь компьютера по своему усмотрению, не лишая эту операцию здравого смысла. Программы «научить» работать с «чужими» файлами не так просто, а порой и невозможно.
Чтобы научиться разбираться в файлах, которые находятся на вашем компьютере, например, на рабочем столе вашего монитора, чтобы свободно пользоваться необходимыми программами на компьютере для решения своих повседневных задач, рекомендуем ознакомиться с нашими компьютерными курсами для начинающих
как отследить приложение, записывающее непонятные файлы на диск – Вадим Стеркин
Непонятные файлы на диске мы обнаруживаем двумя путями. Либо они явно видны в проводнике или файловом менеджере, либо к ним приводят поиски причины исчезновения свободного места на диске. Хорошо, если после удаления файлов, они больше не появляются. Но так бывает не всегда, и в этом случае приходится определять приложение, которое их создает.
Однажды на форум обратился человек, у которого какое-то приложение записывало в корень системного диска файлы, в имени которых содержится tmp _out.
Конечно, не исключено, что эта система заражена, и требуется тщательная проверка всевозможными антивирусными средствами. Но далеко не всегда проблема связана с вредоносным кодом, и тогда понадобится другой подход. Проще всего вычислить виновника появления таких файлов с помощью утилиты Process Monitor. Из видео за четыре минуты вы узнаете, как это сделать.
Отслеживание активности
При запуске утилита отслеживает несколько типов системной активности:
- реестр
- файловую систему
- сеть
- процессы и потоки
Поскольку мы ищем причину записи файлов на диск, нужно сосредоточиться на активности в файловой системе. Для этого на панели инструментов оставьте включенной только одну кнопку, отвечающую за активность на диске.
Кроме того, убедитесь, что утилита отслеживает активность. Если у вас перечеркнута кнопка, которая на рисунке обведена красным, нажмите CTRL+E.
На рисунке выше активность отслеживается, причем только в файловой системе.
Основной фильтр
Теперь нужно применить фильтр, чтобы исключить не относящуюся к делу активность. Нажмите сочетание клавиш CTRL+L, и вы увидите возможности фильтрации. В Process Monitor сразу активны некоторые фильтры, исключающие отслеживание деятельности самой программы, а также некоторых системных компонентов (файла подкачки, таблицы MFT и т.д.). Это сделано для того, чтобы исключить мониторинг стандартной активности системы. В большинстве случаев удалять эти фильтры не нужно, и достаточно просто добавить свой.
На рисунке выше показан фильтр, который будет отслеживать создание и изменение всех файлов, в путях к которым содержится tmp _out. Давайте разберем фильтр подробнее слева направо:
- Path. Путь в файловой системе. Также можно указывать разделы реестра, когда отслеживается активность в нем.
- contains. Условие, по которому определяется поиск ключевого слова. В переводе с английского это слово означает «содержит». В зависимости от задачи можно конкретизировать условие, выбрав вариант begins with (начинается с) или ends with (заканчивается на).
- tmp _out. Ключевое слово, которое в данном случае должно содержаться в пути. Имя файла и его расширение являются частью полного пути к файлу.
- Include. Включение заданного условия в список отслеживаемых.
Не забудьте нажать кнопку Add, чтобы добавить фильтр в список. Впрочем, если вы забудете, Process Monitor напомнит об этом, прежде чем закрыть окно фильтров.
В данном случае я использовал часть имени файла в качестве ключевого слова, поскольку все непонятные файлы содержат в имени tmp_out. Если файлы создаются с разными именами, но зато в определенной папке, используйте путь к этой папке в качестве ключевого слова.
Поскольку задано жесткое условие фильтрации файловой активности, в окне программы, скорее всего, теперь не будет отображаться никаких процессов. Но Process Monitor уже начал их отслеживать.
Проверить работу фильтра очень просто. Достаточно создать в текстовом редакторе файл с искомым именем или в наблюдаемой папке, и Process Monitor моментально отреагирует на это.
Увеличить рисунок
Дополнительные фильтры
Обратите внимание, что утилита зафиксировала не только активность блокнота, но также проводника и поиска Windows. Не относящиеся к делу процессы можно исключить из результатов, создав дополнительные фильтры. Достаточно щелкнуть по процессу правой кнопкой мыши и выбрать из контекстного меню пункт Exclude <имя процесса>. Это самый простой способ создания фильтра, но можно сделать это из окна фильтрации, как показано выше. В этом случае условие будет: Process Name – Is — <имя процесса> — Exclude.
Запись и открытие лога
Учтите, что при длительном отслеживании размер лога может измеряться гигабайтами. По умолчанию Process Monitor записывает лог в файл подкачки. Если у вас маленький системный раздел, имеет смысл сохранять лог в файл на другом разделе диска.
Для сохранения лога в файл нажмите сочетание клавиш CTRL+B и укажите имя и желаемое расположение файла.
Изменения вступают в силу после перезапуска захвата активности. Теперь можно смело оставить Process Monitor включенным на длительное время, не опасаясь за лимит дискового пространства.
Остановить отслеживание активности можно сочетанием клавиш CTRL+E.
Впоследствии вы всегда сможете загрузить в утилиту лог из сохраненного файла. Закройте Process Monitor и дважды щелкните файл лога с расширением PML. Содержимое лога отобразится в окне Process Explorer.
Человек, обратившийся на форум с проблемой, так и не вернулся сообщить, помог ли ему мой совет. Но он был с таким вопросом не первый и, наверняка, не последний. Если вопрос возникнет у вас, вы сможете ответить на него с помощью Process Monitor.
О видео
Читатели блога выразили поддержку моей идее дополнять статьи видеоматериалами. Я подумал, что этот случай очень хорошо подходит, и записал ролик длиной менее 4 минут.
Если честно, создание такого видео занимает намного больше времени, чем написание статьи. Поэтому я в любом случае не готов заменять печатный текст видеоматериалами. Но мне кажется, что в данном случае видео интереснее и понятнее. А что вы думаете по этому поводу?
Видео длится около четырех минут, и я старался сделать его быстрым и емким. Ведь в реальности подготовка к поимке приложения занимает буквально одну минуту. Вас устраивает скорость изложения?
Более подробный рассказ о Process Monitor и другие примеры его практического использования вы можете посмотреть в видео моего коллеги Василия Гусева, если у вас есть свободные 40 минут :)
Обсуждение завершено.
Основные linux-команды для новичка / Хабр
Linux — это операционная система. Как винда (windows), только более защищенная. В винде легко подхватить вирус, в линуксе это практически невозможно. А еще линукс бесплатный, и ты сам себе хозяин: никаких тебе неотключаемых автообновлений системы!Правда, разобраться в нем немного посложнее… Потому что большинство операций выполняется в командной строке. И если вы видите в вакансии «знание linux» — от вас ожидают как раз умение выполнять простейшие операции — перейти в другую директорию, скопировать файл, создать папочку… В этой статье я расскажу про типовые операции, которые стоит уметь делать новичку. Ну и плюс пара полезняшек для тестировщиков.
Я дам кратенькое описание основных команд с примерами (примеры я все проверяла на cent os, red hat based системе) + ссылки на статьи, где можно почитать подробнее. Если же хочется копнуть еще глубже, то см раздел «Книги и видео по теме». А еще комментарии к статье, там много полезного написали)
Содержание
Где я? Как понять, где находишься
Команда pwd:
pwd --- мы ввели команду /home/test --- ответ системы, мы находимся в домашней директории пользователя testОчень полезная команда, когда у вас нет ничего, кроме командной строки под рукой. Расшифровывается как Print Working Directory. Запомните ее, пригодится.
Как понять, что находится в папке
Команда ls позволяет просмотреть содержимое каталога:
Хотя лучше использовать команду сразу с флагом «l»:
ls -lТакая команда выведет более читабельный список, где можно будет сразу увидеть дату создания файла, его размер, автора и выданные файлу права.
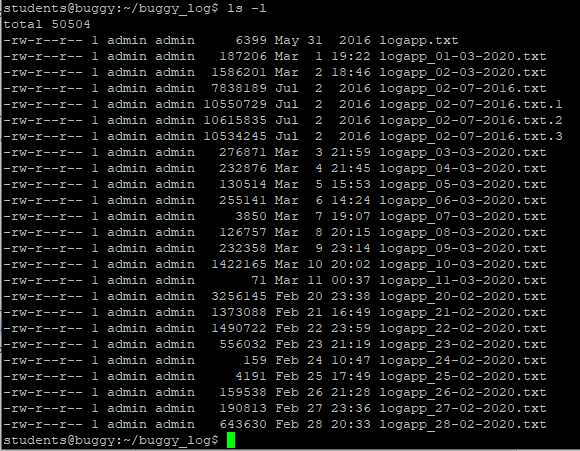
У команды есть и другие флаги, но чаще всего вы будете использовать именно «ls – l».
См также:
Команда ls Linux — подробнее о команде и всех ее флагах
Команда ls – просмотр каталога — о команде для новичков (без перечисления всех флагов)
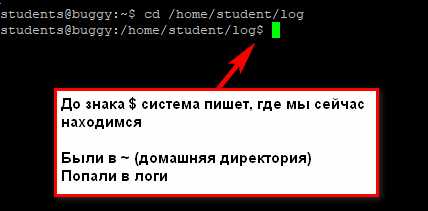
Как перейти в другую директорию
С помощью команды cd:
cd <путь к директории>Путь может быть абсолютным или относительным.
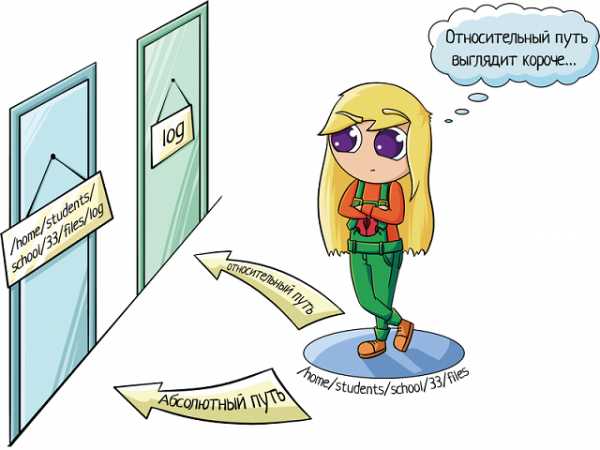
По абсолютному пути
Либо у вас где-то записан путь, «куда идти», либо вы подсмотрели его в графическом интерфейсе (например, в WinSCP).
Вставляем путь в командную строку после «cd»
cd /home/student/logНу вот, мы переместились из домашней директории (обозначается как ~) в /home/student/log.
По относительному пути
Относительный путь — относительно вашей текущей директории, где вы сейчас находитесь. Если я уже нахожусь в /home/student, а мне надо в /home/student/log, команда будут такой:
cd log --- перейди в папку log из той директории, где ты сейчас находишьсяЕсли мне из надо из /home/student/photo в /home/student/photo/city/msk/2017/cat_1, команда будет такой:
cd city/msk/2017/cat_1Я не пишу /home/student/photo, так как я уже там.
В линуксе можно задавать путь относительно домашней папки текущего пользователя. Домашняя директория обозначается ~/. Заметьте, не ~, а именно ~/. Дальше вы уже можете указывать подпапки:
cd ~/logЭта команда будет работать отовсюду. И переместит нас в /home/user/log.
Вот пример, где я вошла под пользователем students. Исходно была в директории /var, а попала в /home/students/log:
С автодополнением
Если вы начнете набирать название папки и нажмете Tab, система сама его подставит. Если просто нажмете Tab, ничего не вводя, система начнет перебирать возможные варианты:
— (cd tab) Может, ты имел в виду папку 1?
— (tab) Нет? Может, папку 2?
— (tab) Снова нет? Может, папку 3?
— (tab) Снова нет? Может, файл 1 (она перебирает имена всех файлов и директорий, которые есть в той, где вы сейчас находитесь)?
— (tab) У меня кончились варианты, поехали сначала. Папка 1?

cd lon(Tab) → cd long-long-long-long-name-folder — начали вводить название папки и система сама подставила имя (из тех, что есть в директории, где мы находимся).
cd (Tab)(Tab)(Tab) — система перебирает все файлы / папки в текущей директории.
Это очень удобно, когда перемещаешься в командной строке. Не надо вспоминать точное название папки, но можно вспомнить первую букву-две, это сократит количество вариантов.
Подняться наверх
Подняться на уровень выше:
cd ..Если нужно поднять на два уровня выше, то
cd ../..И так до бесконечности =) Можно использовать файл, лежащий на уровне выше или просто сменить директорию.
Обратите внимание, что команда для линукса отличается от команды для винды — слеш другой. В винде это «cd ..\..», а в линуксе именно «cd ../..».
См также:
Путь к файлу в linux
Как создать директорию
Используйте команду mkdir:
mkdir test --- создает папку с названием «test» там, где вы находитесьМожно и в другом месте создать папку:
mkdir /home/test --- создает папку «test» в директории /home, даже если вы сейчас не тамКогда это нужно? Например, если вам надо сделать бекап логов. Создаете папку и сохраняете туда нужные логи. Или если вы читаете инструкцию по установке ПО и видите там «создать папку». Через командную строку это делается именно так.
См также:
Как создать каталог в Linux с помощью команды mkdir
Как создать файл
Командой touch:
touch app.logТакая команда создаст пустой файл с названием «app.log». А потом уже можно открыть файл в редакторе и редактировать.
Как отредактировать файл
Вот честное слово, лучше делать это через графический интерфейс!
Но если такой возможности нет, чтож… Если использовать программы, которые есть везде, то у вас два варианта:
- nano — более простая программа, рассчитана на новичков
- vim — более сложная, но позволяет сделать кучу всего
Начнем с nano. Указываете имя команды и путь в файлу:
nano test_env.jsonДля перемещения по файлу используйте кнопки со стрелками. После того, как закончите редактировать файл, нажмите:
- Ctrl+O — чтобы сохранить
- Ctrl+X — для выхода
Самое приятное в nano — это подсказки внизу экрана, что нажать, чтобы выйти.
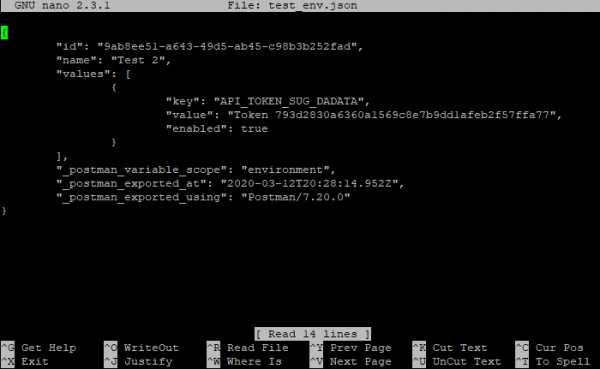
А вот с vim с этим сложнее. В него легко зайти:
vim test_env.json vi test_env.json (предшественник vim)Войти вошли, а как выйти то, аааа? Тут начинается легкая паника, потому что ни одна из стандартных комбинаций не срабатывает: Esc, ctrl + x, ctrl + q… Если под рукой есть второй ноутбук или хотя бы телефон / планшет с интернетом, можно прогуглить «как выйти из vim», а если у вас только одно окно с терминалом, которое вы заблокировали редактором?
Делюсь секретом, для выхода надо набрать:
- :q — закрыть редактор
- :q! — закрыть редактор без сохранения (если что-то меняли, то просто «:q» не проканает)
Двоеточие запускает командный режим, а там уже вводим команду «q» (quit).
Исходно, когда мы открываем файл через vim, то видим его содежимое, а внизу информацию о файле:
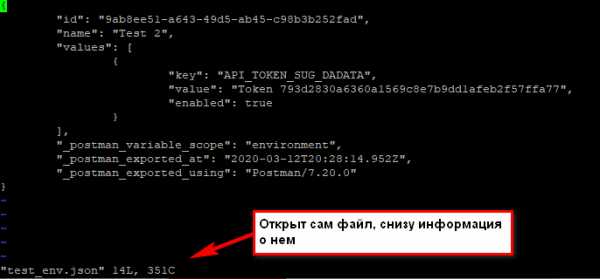
Когда нажимаем двоеточие, оно печатается внизу:
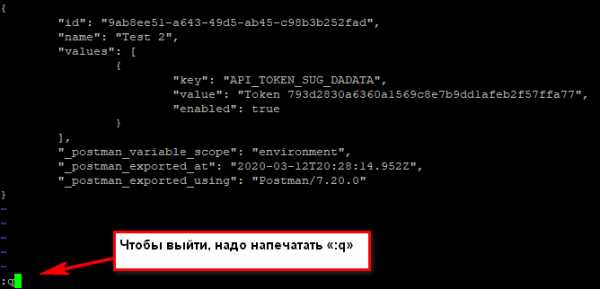
Если не печатается, не паникуем! Тогда попробуйте нажать Esc (вернуться в нормальный режим), потом Enter (подтвердить команду), а потом снова печатайте. Фух, помогло, мы вышли оттуда!!!
На самом деле сейчас всё не так страшно. Даже если вас заслали работать в банк, где нет доступа в интернет, а вы вошли в vi и не знаете как выйти, всегда можно погулить выход с телефона. Слава мобильному интернету! Ну а если вы знаете логин-пароль от сервера, то можно просто закрыть терминал и открыть его снова.
Если нужно выйти, сохранив изменения, используйте команду
:w — сохранить файл; :q — закрыть редактор;Ну а про возможности редактирования см статьи ниже =)
См также:
Как редактировать файлы в Ubuntu — подробнее о разных способах
Как пользоваться текстовым редактором vim — подробнее о vim и всех его опциях
Как выйти из редактора Vi или Vim? — зачем нажимать Esc
Как перенести / скопировать файл
Допустим, у нас в директории /opt/app/log находится app.log, который мы хотим сохранить в другом месте. Как перенести лог в нужное место, если нет графического интерфейса, только командная строка?
Скопировать файл
Команда:
cp что_копировать куда_копироватьЕсли мы находимся в директории /opt/app/log:
cp app.log /home/olgaВ данном примере мы использовали относительный путь для «что копировать» — мы уже находимся рядом с логом, поэтому просто берем его. А для «куда копировать» используем абсолютный путь — копируем в /home/olga.
Можно сразу переименовать файл:
cp app.log /home/olga/app_test_2020_03_08.logВ этом случае мы взяли app.log и поместили его в папку /home/olga, переименовав при этом в app_test_2020_03_08.log. А то мало ли, сколько логов у вас в этом папке уже лежит, чтобы различать их, можно давать файлу более говорящее имя.
Если в «куда копировать» файл с таким именем уже есть, система не будет ничего спрашивать, просто перезапишет его. Для примера положим в папку log внутри домашней директории файл «app.log», который там уже есть:
Никаких ошибок, система просто выполнила команду.
См также:
Копирование файлов в linux
Скопировать директорию
Команда остается та же, «cp», только используется ключ R — «копировать папку рекурсивно»:
cp -r путь_к_папке путь_к_новому_местуНапример:
cp /opt/app/log /home/olgaТак в директории /home/olga появится папка «log».
Переместить файл
Если надо переместить файл, а не скопировать его, то вместо cp (copy) используем mv (move).
cp app.log /home/olga ↓ mv app.log /home/olgaМожно использовать относительные и абсолютные пути:
mv /opt/app/logs/app.log /home/olga — абсолютные пути указаны, команда сработает из любого местаМожно сразу переименовать файл:
mv app.log /home/olga/app_2020_03_08.log — перенесли лог в /home/olga и переименовалиПереместить директорию
Аналогично перемещению файла, команда mv
mv /opt/app/log/ /home/olga/bakup/Как удалить файл
С помощью команды rm (remove):
rm test.txt — удалит файл test.txtЕсли нужно удалить все файлы в текущей директории (скажем, вычищаем старые логи перед переустановкой приложения), используйте «*»:
rm * — удалит все файлы в текущей директории
Если нужно удалить папку, надо добавить флаг -r (recursive):
rm -r test_folderЕсли вы пытаетесь удалить файлы, которые уже используются в программе или доступны только для чтения, система будет переспрашивать:
А теперь представьте, что вы чистите много файлов. И на каждый система переспрашивает, и надо постоянно отвечать «да, да, да...» (y – enter, y – enter, y – enter)… Чтобы удалить все без вопросов, используйте флаг -f (force):
rm -rf test_folder --- просто все удалит без разговоровНо учтите, что это довольно опасная команда! Вот так надоест подстверждать удаление и введешь «-rf», а директорию неправильно укажешь… Ну и все, прости-прощай нужные файлы. Аккуратнее с этой командой, особенно если у вас есть root-полномочия!
Опция -v показывает имена удаляемых файлов:
rm -rfv test_folder --- удалит папку со всем содержимым, но выведет имена удаляемых файловТут вы хотя бы можете осознать, что натворили )))
См также:
Как удалить каталог Linux
Как изменить владельца файла
Если у вас есть root-доступ, то вы наверняка будете выполнять все действия под ним. Ну или многие… И тогда любой созданный файл, любая папка будут принадлежать root-пользователю.
Это плохо, потому что никто другой с ними работать уже не сможет. Но можно создать файл под root-ом, а потом изменить его владельца с помощью команды chown.

Допустим, что я поднимаю сервис testbase. И он должен иметь доступ к директории user и файлу test.txt в другой директории. Так как никому другому эти файлики не нужны, а создала я их под рутом, то просто меняю владельца:
chown testbase:testbase test.txt — сменить владельца файла chown -R testbase:testbase user — сменить владельца папкиВ итоге был владелец root, а стал testbase. То, что надо!
См также:
Команда chown Linux
Как установить приложение
Если вы привыкли к винде, то для вас установка приложения — это скачать некий setup файлик, запустить и до упора тыкать «далее-далее-далее». В линуксе все немного по-другому. Тут приложения ставятся как пакеты. И для каждой системы есть свой менеджер пакетов:
- yum — red hat, centos
- dpkg, apt — debian
См также:
5 Best Linux Package Managers for Linux Newbies
Давайте посмотрим на примере, как это работает. В командной строке очень удобно работать с Midnight Commander (mc) — это как FAR на windows. К сожалению, программа далеко не всегда есть в «чистом» дистрибутиве.
И вот вы подняли виртуалку на centos 7, хотите вызвать Midnight Commander, но облом-с.
mcНичего страшного, установите это приложение через yum:
yum install mc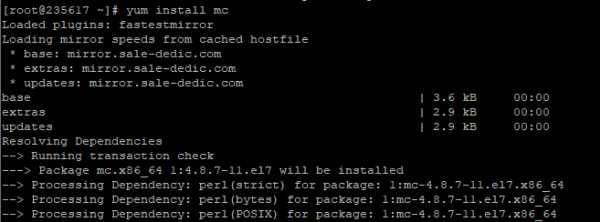
Он там будет что-то делать, качать, а потом уточнит, согласны ли вы поставить программу с учетом ее размеров. Если да, печатаем «y»:
И система заканчивает установку.
Вот и все! Никаких тебе унылых «далее-далее-далее», сказал «установи», программа установилась! Теперь, если напечатать «mc» в командной строке, запустится Midnight Commander:
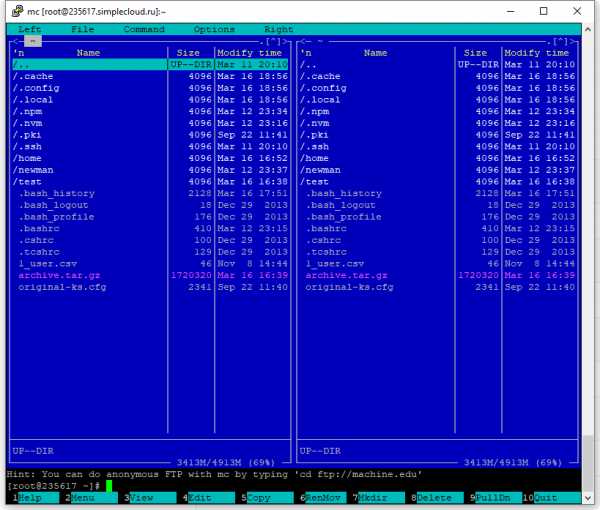
См также:
Как устанавливать программы для Linux
Yum, шпаргалка — всякие опции и плагины
Как запустить приложение
Некоторые приложения запускаются через скрипты. Например, чтобы запустить сервер приложения WildFly, нужно перейти в папку bin и запустить там standalone.sh. Файл с расширением .sh — это скрипт.
Чтобы запустить скрипт, нужно указать полный путь к нему:
/opt/cdi/jboss/bin/standalone.sh — запустили скрипт standalone.shЭто важно! Даже если вы находитесь в той папке, где и скрипт, он не будет найден, если просто указать название sh-скрипта. Надо написать так:
./standalone.sh — запустили скрипт, если мы в той же директорииПоиск идет только в каталогах, записанных в переменную PATH. Так что если скрипт используется часто, добавляйте путь туда и вызывайте просто по названию:
standalone.sh --- запустили скрипт standalone.sh, путь к которому прописан в PATHСм также:
Запуск скрипта sh в Linux — подробнее о скриптах

Если же приложение запускается как сервис, то все еще проще:
service test start — запустить сервис под названием «test» service test stop — остановить сервисЧтобы сервис test запускался автоматически при рестарте системы, используйте команду:
chkconfig test onОна добавит службу в автозапуск.
Как понять, где установлено приложение
Вот, например, для интеграции Jenkins и newman в Jenkins надо прописать полный путь к ньюману в параметре PATH. Но как это сделать, если newman ставился автоматически через команду install? И вы уже забыли, какой путь установки он вывел? Или вообще не вы ставили?
Чтобы узнать, куда приложение установилось, используйте whereis (без пробела):
whereis newmanКак создать архив
Стандартная утилита, которая будет работать даже на «голой» системе — tar. Правда, для ее использования надо запомнить флаги. Для создания архива стандартная комбинация cvzf:
tar -cvzf archive.tar.gz /home/testВ данном примере мы упаковали директорию /home/test, внутри которой было две картинки — 502.jpg и 504.jpg.
Для распаковки меняем флаг «c» на «x» и убираем «z»:
tar -xvf archive.tar.gzХотя система пишет, что распаковала «/home/test», на самом деле папка «test» появляется там, где мы сейчас находимся.
Давайте разберемся, что все эти флаги означают:
- c — создать архив в linux
- x — извлечь файлы из архива
- v — показать подробную информацию о процессе работы (без него мы бы не увидели, какие файлики запаковались / распаковались)
- f — файл для записи архива
- z — сжатие
Для упаковки используется опция c — Create, а для распаковки x — eXtract.

Если очень хочется использовать rar, то придется изгаляться. Через yum установка не прокатит:
yum install rar yum install unrarГоворит, нет такого пакета:
No package rar available. Error: Nothing to doПридется выполнить целую пачку команд! Сначала скачиваем, разархивируем и компилируем:
wget http://rarlabs.com/rar/rarlinux-x64-5.4.0.tar.gz tar xzf rarlinux-x64-5.4.0.tar.gz cd rar make installУстанавливаем:
mkdir -p /usr/local/bin mkdir -p /usr/local/lib cp rar unrar /usr/local/bin cp rarfiles.lst /etc cp default.sfx /usr/local/libИ применяем:
unrar x test.rarСм также:
Установка RAR на Linux
Как посмотреть использованные ранее команды
Вот, допустим, вы выполняли какие-то сложные действия. Или даже не вы, а разработчик или админ! У вас что-то сломалось, пришел коллега, вжух-вжух ручками, magic — работает. А что он делал? Интересно же!
Или, может, вы писали длинную команду, а теперь ее надо повторить. Снова набирать ручками? Неохота! Тем более что есть помощники:
↑ (стрелочка «наверх») — показать последнюю команду history — показать последние 1000 командЕсли надо «отмотать» недалеко, проще через стрелочку пролистать команды. Один раз нажали — система показала последнюю команду. Еще раз нажали — предпоследнюю. И так до 1000 раз (потому что именно столько хранится в истории).

Большой бонус в том, что линукс хранит историю даже при перезапуске консоли. Это вам не как в винде — скопировал текст, скопировал другой, а первый уже потерялся. А при перезагрузке системы вообще все потерялось.
Если тыкать в стрелочку не хочется, или команды была давно, можно напечатать «history» и внимательно изучить команды.
См также:
История команд Linux — больше о возможностях history
Как посмотреть свободное место
Сколько места свободно на дисках
df -hСколько весит директория
du -sh du -sh * --- с разбиениемКак узнать IP компьютера
Если у вас настроены DNS-имена, вы подключаетесь к linux-машине именно по ним. Ведь так проще запомнить — это testbase, это bugred… Но иногда нужен именно IP. Например, если подключение по DNS работает только внутри рабочей сети, а коллега хочет подключиться из дома, вот и уточняет айпишник.
Чтобы узнать IP машины, используйте команду:
hostname -IТакже можно использовать ifconfig:
ifconfig — выведет кучу инфы, в том числе ваш внешний IP ip a — аналог, просто иногда Ifconfig дает очень много результата, тут поменьше будетСм также:
Displaying private IP addresses
Как узнать версию OS
Сидите вы у Заказчика на линуксовой машине. Пытаетесь что-то установить — не работает. Лезете гуглить, а способы установки разные для разных операционных систем. Но как понять, какая установлена на данной машине?
Используйте команду:
cat /etc/*-release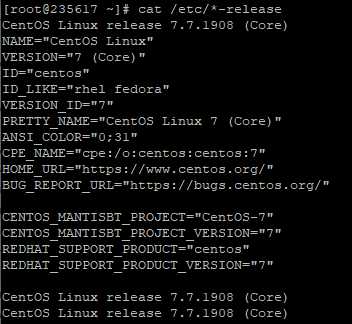
На этой виртуалке стоит CentOs 7.
Если нужна версия ядра:
uname -aСм также:
Как узнать версию Linux
Как узнать, как работает команда
Если вы не знаете, как работает команда, всегда можно спросить о ней саму систему, используя встроенную команду man:
man ls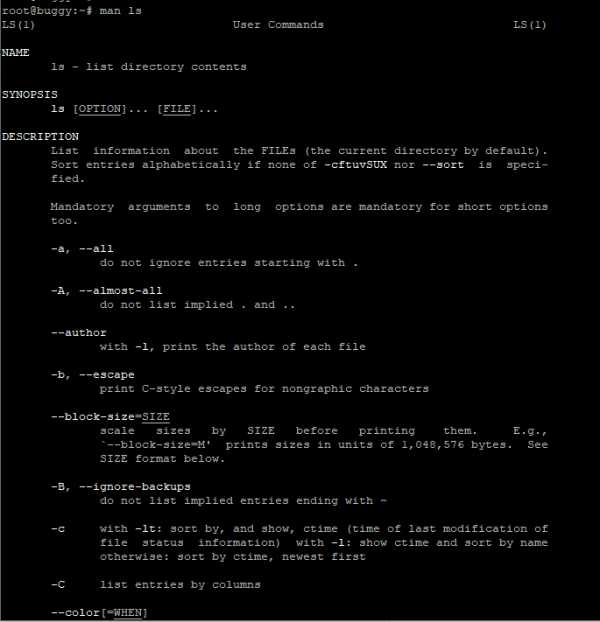
Закрыть мануал можно с помощью клавиши q. Для того, кто первый раз в линуксовой консоли, это совсем не очевидно, а подсказки есть не везде.
Команда удобна тем, что не надо даже уходить из командной строки, сразу получаешь всю информацию. К тому же это всегда актуальная информация. А что вы там нагуглите — неизвестно =))
Хотя лично мне проще какую-то команду прогуглить, ведь так я получу русское описание + сначала самые главные флаги (а их может быть много). Но я сама новичок в линуксе, это подход новичка. А лучше сразу учиться прокачивать навык поиска по man-у. Он вам очень пригодится для более сложных задач!
Если man у программы нет, используйте флаг -h (--help):
ls -hКак создать много тестовых папок и файлов
Допустим, у нас есть некая папка test. Создадим в ней сотню директорий и кучу файликов в каждой:
mkdir -p test/dir--{000..100} touch test/dir--{000..100}/file-{A..Z}Вот и все, дальше можно играться с ними!
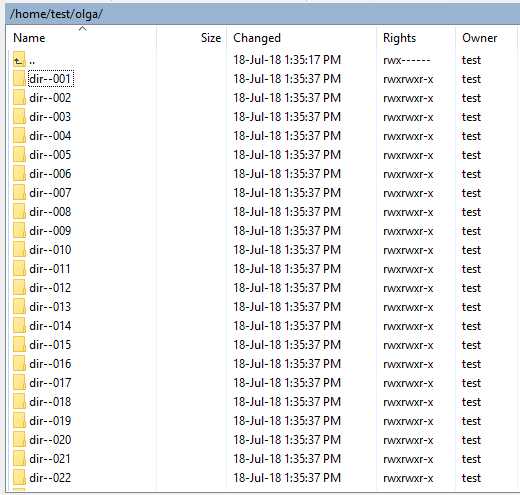
Теперь пояснения:
- mkdir — создать директорию
- touch — создать файл (или изменить существующий, но если файла с таким именем нет, то команда создаст новый, пустой)
А выражения в скобках играют роль функции, которая выполняется в цикле и делает ручную работу за вас:
- {000..100} — пробежится по всем числам от 0 до 100
- {A..Z} — пробежится по всем буквам английского алфавита от A до Z
Как я пробовала эту команду. Сначала посмотрела, где нахожусь:
$ pwd /home/testСимвол $ при описании команд означает начало строки, куда мы пишем команду. Так мы отделяем то, что ввели сами (pwd) от ответа системы (/home/test).
Ага, в домашней директории. Создам себе песочницу:
mkdir olgaВот в ней и буду творить!
mkdir -p olga/dir--{000..100} touch olga/dir--{000..100}/file-{A..Z}А потом можно проверить, что получилось:
cd olga ls -lКак-то так! Имхо, полезные команды.
Я нашла их в книге «Командная строка Linux. Полное руководство», они используются для того, чтобы создать песочницу для прощупывания команды find. Я, как и автор, восхищаюсь мощью командной строки в данном случае. Всего 2 строчки, а сколько боли бы принесло сделать похожую структуру через графический интерфейс!
И, главное, тестировщику полезно — может пригодиться для тестов.
Как протестировать IOPS на Linux
Это очень полезно делать, если машину вам дает заказчик. Там точно SSD-диски? И они дают хороший iops? Если вы разрабатываете серверное приложение, и от вас требуют выдерживать нагрузку, нужно быть уверенными в том, что диски вам выдали по ТЗ.
Наше приложение активно использует диск. Поэтому, если заказчик хочет видеть хорошие результаты по нагрузке, мы хотим видеть хорошие результаты по производительности самих дисков.Но верить админам другой стороны на слово нельзя. Если приложение работает медленно, они, разумеется, будут говорить, что у них то все хорошо, это «они» виноваты. Поэтому надо тестировать диски самим.
Я расскажу о том, как мы тестировали диски. Как проверили, сколько IOPS они выдают.

Используем утилиту fio — https://github.com/axboe/fio/releases.
1) Скачиваем последнюю версию, распаковываем, переходим в каталог. В командах ниже нужно заменить «fio-3.19» на актуальную версию из списка
cd /tmp wget https://github.com/axboe/fio/archive/fio-3.19.tar.gz tar xvzf fio-3.19.tar.gz rm fio-3.19.tar.gz cd fio-fio-3.192) Должны стоять пакеты для сборки
apt-get install -y gcc make libaio-dev | yum install -y make gcc libaio-devel3) Собираем
make4) Тестируем
./fio -readonly -name iops -rw=randread -bs=512 -runtime=20 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1Какие должны быть результаты:
- Средний SSD, выпущенный 2-3 года назад — 50 тысяч IOPS.
- Свежий Samsung 960 Pro, который стоит на одной из железок у нас в офисе — 350 тысяч IOPS.
Свежесть определяется на момент написания статьи в 2017 году.
Если должно быть 50 тысяч, а диск выдает сильно меньше, то:
— он не SSD;
— есть сетевые задержки;
— неправильно примонтирован;
— с ними что-то еще плохое случилось и стоит поднять алярм.
И это все?
Разумеется, нет =))
Еще полезно изучить команду find и регулярные выражения. Тестировщику как минимум надо уметь «грепать логи» — использовать grep. Но это уже остается на самостоятельный гуглеж.
База, которая всегда нужна — pwd, cp, mv, mkdir, touch. Остальное можно легко гуглить, как только возникает необходимость.
Вот вам еще пара ссылочек от меня:
Для понимания структуры папок рекомендую статью «Структура папок ОС Linux. Какая папка для чего нужна. Что и где лежит в линуксе»
Книги и видео по теме
Видео:
ПО GNU/Linux — видео лекции Георгия Курячего — очень хорошие видео-лекции
Книги:
Командная строка Linux. Уильям Шоттс
Скотт Граннеман. Linux. карманный справочник
Где тренироваться
Можно поднять виртуалку. Правда, тут сначала придется разбираться, как поднимать виртуалку )))
А можно купить облачную машину. Когда мне надо было поиграться с линуксом, я пошла на SimpleCloud (он мне в гугле одним из первых выпал и у него дружелюбный интерфейс. Но можно выбрать любой аналог) и купила самую дешманскую машину — за 150 руб в месяц. Месяца вам за глаза, чтобы «пощупать-потыркать», и этой машины с минимумом памяти тоже.
У меня был когда-то план самой платить эти 150р за то, чтобы дать машину в общий доступ. Но увы. Как я не пыталась ее огородить (закрывала команды типа ssh, ping и прочая), у меня не получилось. Всегда есть люди, которых хлебом не корми, дай испортить чужое. Выложил в общий доступ пароли? На тебе ддос-атаку с твоего сервера. Ну и сервер блокируют. После N-ой блокировки я плюнула на это дело. Кто хочет научиться, найдет 150р.
Чтобы подключиться к машине, используйте инструменты:
- Putty — командная строка
- WinSCP — графический интерфейс
См также:
WinSCP — что это и как использовать
Как определить какой программой открыть файл
Автор Руслан Ошаров На чтение 2 мин. Опубликовано
Привет, дорогие читатели и гости блога! Продолжаем знакомиться с компьютером и интернетом. Разбираем возникающие вопросы подробно и простым языком. Сегодня учимся определять, какой программой открыть файл, если он не открывается через обычный клик мыши.
В каких случаях может возникнуть ситуация, когда ваш ПК не находит решения для открытия файла? Например, вы скачали в интернете интересующий вас материал с определённым расширением, но на вашем ПК нет необходимой программы, которая работает с этим расширением.
Или компьютер спрашивает при открытии файла, какой программой вы хотите этот файл открыть, а вы вообще не имеете об этом понятия.
Начнём с того, что узнаем что такое расширение, и как определить расширение файла, который вы скачали и хотите открыть.
Расширение — это точка и несколько латинских букв после имени файла. В зависимости от настроек компьютера, вы можете видеть расширение или оно может быть скрыто.
Чтобы определить расширение файла, достаточно навести на него курсор, затем кликнуть правой кнопкой мыши, и выбрать “Свойства”
Откроется окно, где есть информация о файле, в том числе и его тип. В данном примере файл имеет расширение .pdf
Теперь нам нужно воспользоваться специальным сервисом для определения программы, которой можно открыть файл. Переходим по ссылке //open-file.ru/ Далее вводим расширение в строку поиска без точки, и нажимаем клавишу ввода либо на значок лупы.
Перед нами открылся список расширений. Находим нужное расширение и жмём на него левой кнопкой.
Пролистав вниз мы найдём список программ для разных устройств, которыми можно открыть файл. Теперь мы знаем, какой программой открыть файл на компьютере. Возможно такая программа уже есть на ПК, просто нужно выбрать её в настройках для открытия файла.
Кликаем правой кнопкой и выбираем “Открыть с помощью”, а затем в списке ищем программу. Если на ПК нет подходящих программ, значит нужно скачать в интернете или найти другой файл.
До связи! Пусть ваши файлы открываются легко!
Как узнать, какой программой можно открыть файл?
Суть проблемы в том что: В большинстве случаев, на компьютере пользователя не установлена нужная программа для открытия файла.
Для примера – имеется потребность запустить файл «FileName.rtf» но если, «Microsoft Office Word» не установлен, то, операционная система проинформирует пользователя сообщением «Windows не может открыть данный файл».
Ниже вы узнаете, какой программой можно открыть файл, если он не открывается и главное, как быстро найти нужную программу. Но, прежде чем открыть браузер для поиска программы, необходимо узнать расширение файла, который требуется открыть. Так как, именно по расширению файла и выбирается нужная программа.
Узнать расширение файла довольно просто! Как раз окно с информацией о том, что windows не может открыть файл, нам и нужно.
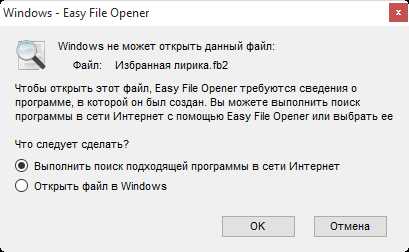
Из данного окна мы видим, что имя файла «Избранная лирика» а расширение файла «fb2». В данном окне предлагается два варианта действий.
Можно попробовать выполнить поиск, подходящий программы в интернете, но в 99.9% случаев найти ничего не получится! И второй вариант «Открыть файл в Windows» покажет список уже установленных программ, среди которых, скорее всего не окажется подходящий!
Поиск программы для открытия неизвестного файла.
Итак, мы узнали расширение файла, который нужно открыть, в данном случаи это «fb2». Чтобы найти нужную программу, переходим на сайт «Чем открыть» и в строке поиска указываем расширение файла.
Нажмите кнопку найти и перейдите по первой ссылки из выдачи.
На следующей странице Вас будет ждать описание расширение и список программ, которые умеют работать с «fb2» файлами.

Выберете любую программу, скачайте и установите. Теперь нужный файл будет открываться в этой программе при его запуске. Но это не всегда так! Возможно что, после установки программы файл по-прежнему не будет открываться. Что делать?
Программа установлена, но файл не открывается.
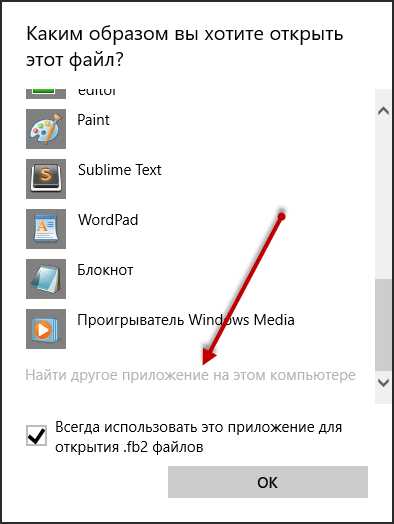
Нами была выбрана и установлена первая программа из списка «FBReader». Но, файл так и не хочет открываться. Это происходит из-за того, что тип файл не был связан с программой «FBReader». Чтобы исправить ситуацию, выбираем второй вариант, как показано ниже.

Появится окно, в котором кликните по ссылке «Ещё приложения». Если в списке приложений не окажется нужной программы, то в самом низу списка выбираем «Найти другое приложение на этом компьютере»
Откроется проводник, где нужно перейти в папку с установленной программой. Путь до установленной программы можно посмотреть и заодно скопировать из свойства ярлыка самой программы. Двойным кликом «ЛКМ» выберите исполняемый файл, как правило, это «название программы.exe».
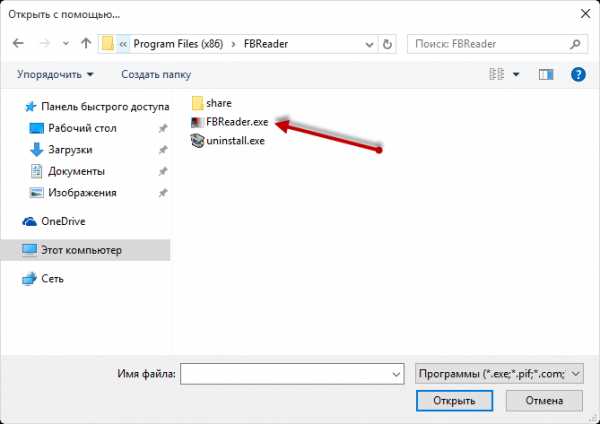
Теперь файлы с расширение «fb2» всегда будут открываться в данной программе при их запуске.
Рекомендуем добавить в закладки сайт «Чем открыть». Достаточно полезный ресурс, с помощью которого можно быстро выяснить, какой программой можно открыть файл и скачать программу с официального сайта.
Как узнать, какие документы или папки открывались на компьютере?
Сегодня статья из разряда форензики (компьютерной криминалистики), недавно узнал интересное место, где хранится что-то вроде истории открытий файлов, которой можно воспользоваться с целью сбора интересующей информации при расследовании компьютерных инцидентов.
Способ касается современных операционных систем (старше Windows 7).
На самом деле много где остаётся информация об открытых файлах, документах и посещений каталогов. Система на удивление любит “натоптать”. Итак, приступим.
Как-то на глаза мне попались какие-то файлы с расширением “.automaticDestinations-ms”, о таких я раньше не слышал. Находятся они в каталоге:
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations\
Файл представляет собой что-то вроде базы данных наиболее часто используемых файлов. Несмотря на плохо читаемые имена файлов (16 hex-цифр, напоминает буквенно-цифровой хеш), это конкретные константы, в частности файл “a7bd71699cd38d1c” всегда отвечает за Word 2010 (32-bit), а “adecfb853d77462a” – за Word 2007 и т.д. (Где взять расширенный список я подскажу ниже).
При клике правой кнопкой мыши на панели задач конкретного приложения мы увидим нечто подобное:
Так каждая программа пишет в свой конкретный файл.
Итак, открываются эти файлы прекрасно различными специализированными программами, я пользуюсь JumpLister.
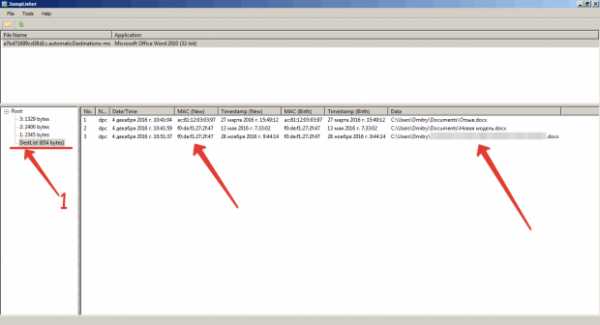
Открываем файл в программе и видим следующее. Цифрой 1 я пометил общий список файлов, который открывался. Что характерно здесь – есть путь к файлу (справа), а так же неплохое поле – MAC-адрес хоста, создавшего документ. В частности здесь видно, что первый файл создан на одном компьютере, второй и третий – на другом. Если выбрать конкретную запись, то увидим детали этого файла.
Кстати, файл AppIds.txt в каталоге с программой – и есть список имён файлов и приложений.
Поговорим ещё немного об этих файлах, поскольку они могут как помочь вам расследовать какой-либо инцидент или замести за собой следы (просто как факт того, что информация об открытых файлах где-то отложилась).
Итак, настроить количество записей в эти файлы можно тут:
Или в реестре:
HKCU\Software\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_JumpListItems.
Друзья! Вступайте в нашу группу Вконтакте, чтобы не пропустить новые статьи! Также, подписывайтесь на наш канал в YouTube!
Как узнать, какой процесс Windows использует файл
Вы когда-нибудь пытались удалить, переместить или переименовать файл только для того, чтобы получить предупреждение системы Windows с чем-то вроде одного из этих сообщений?
- «Невозможно удалить файл: доступ запрещен»
- «Произошло нарушение совместного использования»
- «Исходный или целевой файл может использоваться»
- «Файл используется другой программой или пользователем».
- «Убедитесь, что диск не заполнен, не защищен от записи и что файл в настоящее время не используется»
Один из лучших способов обработки заблокированных файлов или папок - использовать бесплатную программу Microsoft Process Explorer .Программа была описана в другой статье, и вот как с ее помощью узнать, какая программа, DLL или дескриптор использует файл или папку. Вам нужно будет запустить как администратор.
Как узнать какая программа использует файл
В Windows 7 или 8 системное сообщение может сказать вам, какая программа использует файл. Если это не так или если вы используете Windows XP, есть простой способ найти программу:
- Откройте Process Explorer от имени администратора.
- На панели инструментов найдите значок прицела справа (выделен на рисунке ниже).
- Перетащите значок на открытый файл или заблокированную папку.
- Исполняемый файл, использующий файл, будет выделен в основном списке отображения Process Explorer.
Как узнать, какой дескриптор или DLL использует файл
- Откройте Process Explorer от имени администратора.
- Введите сочетание клавиш Ctrl + F .Или щелкните меню «Найти» и выберите «Найти дескриптор или DLL».
- Откроется диалоговое окно поиска.
- Введите имя заблокированного файла или другого интересующего файла. Обычно достаточно частичных имен.
- Нажмите кнопку «Искать»,
- Список будет создан. Может быть несколько записей.
- Отдельный дескриптор в списке можно убить, выбрав его и нажав клавишу удаления. Однако при удалении дескрипторов необходимо соблюдать осторожность, поскольку могут возникнуть нестабильности.Часто просто перезагрузка освобождает заблокированный файл.
Process Explorer можно скачать здесь.
Похожая статья: Best Free Undeletable File Remover
Опубликуйте свой любимый совет! Знаете полезный технический совет или уловку? Тогда почему бы не опубликовать его здесь и не получить полную оценку? Щелкните здесь, чтобы сообщить нам свой совет.
Этот раздел советов поддерживает Вик Лори. Вик ведет несколько веб-сайтов с практическими рекомендациями, руководствами и учебными пособиями по Windows, в том числе сайт для изучения Windows и Интернета и еще один с советами по Windows 7.
Щелкните здесь, чтобы увидеть больше подобных вещей. Еще лучше получить технические советы, доставленные через ваш RSS-канал, или, как вариант, отправить RSS-канал по электронной почте прямо на ваш почтовый ящик.
.Как определить, какой процесс Windows блокирует файл или папку - Справочный центр GSX
Последнее обновление: . Автор: Поддержка GSX (Янн) .
При попытке удалить, переместить или переименовать файл или папку вы получаете предупреждающее сообщение Windows; Операционная система отказывается завершить операцию.
Эта статья помогает определить процесс, который в настоящее время обрабатывает файл или папку, над которыми вы пытаетесь выполнить операцию обслуживания.
Sysinternals Process Explorer | Окна
Симптомы
При попытке удалить, переместить или переименовать файл вы получаете системное предупреждение Windows:
- «Невозможно удалить файл: доступ запрещен».
- «Произошло нарушение совместного использования».
- «Возможно, используется исходный или целевой файл».
- «Файл используется другой программой или пользователем».
- «Убедитесь, что диск не заполнен, не защищен от записи и что файл в настоящее время не используется».
Как решить проблему
Один из самых простых способов работать с заблокированными файлами или папками - использовать Microsoft Sysinternals Process Explorer .
Определите, какая программа использует файл
С помощью Process Explorer найти программу очень просто:
- Открыть обозреватель процессов
- Запуск от имени администратора .
- На панели инструментов найдите значок прицела справа.
- Перетащите значок и отпустите его на открытый файл или заблокированную папку.
- Исполняемый файл, который использует файл, будет выделен в основном списке отображения Process Explorer.
Определите, какой дескриптор или DLL использует файл
- Открыть обозреватель процессов
- Запуск от имени администратора .
- Введите сочетание клавиш Ctrl + F .
- Либо щелкните меню «Найти» и выберите «Найти дескриптор или DLL».
- Откроется диалоговое окно поиска.
- Введите имя заблокированного файла или другого интересующего файла.
- Частичных имен обычно достаточно.
- Нажмите кнопку «Искать».
- Список будет создан.
- Может быть несколько записей.
Снять блокировку файла или папки
Чтобы снять блокировку с файла, над которым вы пытаетесь выполнить операцию обслуживания, вам нужно будет убить соответствующий процесс. Отдельную программу или дескриптор в списке, предоставленном Process Explorer, можно убить с помощью:
- Выбор процесса / дескриптора / записи программы.
- Нажатие клавиши удаления.
Будьте осторожны при удалении дескрипторов, поскольку это может привести к нестабильному поведению и нестабильности.
Загрузки
Вы можете скачать Sysinternals Process Explorer здесь.
Была ли эта статья полезной?
135 из 356 нашли это полезным .Как узнать, на каком языке программирования написано конкретное программное обеспечение?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
Создание, открытие, чтение, запись и закрытие файла
- Home
-
Testing
-
- Back
- Agile Testing
- BugZilla
- Cucumber
- Database Testing
- ETL Testing
- ETL
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- SAP
- 00030003 Центр контроля качества
- SoapUI
- Управление тестированием
- TestLink
-
-
SAP
-
- Назад
- ABAP
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- QM4000
- QM4
- Заработная плата
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- Учебники SAP
-
-
- Apache
- AngularJS
- ASP.Net
- C
- C #
- C ++
- CodeIgniter
- СУБД
- JavaScript
- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux
- Kotlin
- Linux js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL 000
- SQL 000 0003 SQL 000 0003 SQL 000
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно учите!
-
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Встроенные системы
- 0003
- 9000 Эталонный дизайн 900 Ethical
- Учебные пособия по Excel
- Программирование на Go
- IoT
- ITIL
- Jenkins
- MIS
- Сеть
- Операционная система
- Назад
- Prep
- Управление проектом
- Prep
- PM Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Большие данные
-
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
- DevOps Back
- DevOps Back
- HBase
- HBase2
- MongoDB
- NiFi
Как узнать, в каком классе я сейчас учусь в Pycharm?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд
способов обнаружения и удаления выбросов | Наташа Шарма
Что вы ищете, работая над проектом Data Science? Что является наиболее важной частью фазы EDA? Есть определенные вещи, которые, если их не сделать на этапе EDA, могут повлиять на дальнейшее статистическое моделирование / моделирование машинного обучения. Один из них - поиск «выбросов». В этом посте мы попытаемся понять, что такое выброс? Почему важно идентифицировать выбросы? Какие есть методы для выбросов? Не волнуйтесь, мы не будем проходить только теоретическую часть, мы также займемся кодированием и построением графиков данных.
Определение Википедии,
В статистике выброс - это точка наблюдения, удаленная от других наблюдений.
Приведенное выше определение предполагает, что выброс - это что-то отдельное / отличное от толпы. Многие мотивационные видео предлагают отличиться от толпы, особенно Малкольма Гладуэлла. Что касается статистики, это тоже хорошо или нет? мы собираемся найти это в этом посте.
Google Image - WikihowВы видите что-нибудь по-другому на изображении выше? Все числа в диапазоне 30, кроме числа 3.Это наш выброс, потому что он не где-то рядом с другими числами.
Теперь мы знаем, что такое выброс, но задаетесь ли вы вопросом, как выброс представился населению?
Проект Data Science начинается со сбора данных, и именно тогда выбросы впервые представляются населению. Однако на этапе сбора данных о выбросах вы вообще не узнаете. Выбросы могут быть результатом ошибки во время сбора данных или могут быть просто признаком расхождения в ваших данных.
Давайте посмотрим на несколько примеров. Предположим, вас попросили понаблюдать за выступлениями индийской команды по крикету, т. Е. Пробегом каждого игрока, и собрать данные.
Собранные данныеКак видно из собранных выше данных, все остальные игроки набрали 300+, кроме Игрока 3, который набрал 10. Эта цифра может быть просто ошибкой ввода или дисперсией в ваших данных и указанием Player3 работает очень плохо, поэтому требует улучшений.
Теперь, когда мы знаем, что выбросы могут быть либо ошибкой, либо просто отклонением, как бы вы решили, важны они или нет. Что ж, это довольно просто, если они являются результатом ошибки, тогда мы можем их игнорировать, но если это просто расхождение в данных, нам нужно подумать немного дальше. Прежде чем мы попытаемся понять, игнорировать выбросы или нет, нам нужно знать способы их выявления.
Большинство из вас может подумать: «О! Я могу просто получить пик данных, чтобы найти выбросы, как мы это делали в ранее упомянутом примере с крикетом.Давайте представим файл с 500+ столбцами и 10k + строками. Вы все еще думаете, что выбросы можно найти вручную? Чтобы облегчить обнаружение выбросов, у нас есть множество методов статистики, но мы будем обсуждать только некоторые из них. В основном мы будем стараться рассматривать методы визуализации (самые простые), а не математические.
Итак, приступим. Мы будем использовать набор данных Boston House Pricing Dataset, который включен в API набора данных sklearn. Мы загрузим набор данных и разделим функции и цели.
boston = load_boston ()Boston Housing Data
x = boston.data
y = boston.target
columns = boston.feature_names # создать фрейм данных
boston_df = pd.DataFrame (boston.data)
boston_df.columns = columns
boston_df.head ()
Характеристики / независимая переменная будет использоваться для поиска любых выбросов. Глядя на данные выше, кажется, что у нас есть только числовые значения, то есть нам не нужно выполнять какое-либо форматирование данных. (Вздох!)
Есть два типа анализа, которым мы будем следовать, чтобы найти выбросы - Uni-variate (анализ выбросов с одной переменной) и многомерный (анализ выбросов с двумя или более переменными).Не запутайтесь, когда вы начнете кодировать и строить график данных, вы сами убедитесь, насколько легко было обнаружить выброс. Для простоты мы начнем с основного метода обнаружения выбросов и постепенно перейдем к более продвинутым методам.
Обнаружение выбросов с помощью инструментов визуализации
Коробчатая диаграмма-
Определение Википедии,
В описательной статистике прямоугольная диаграмма - это метод графического изображения групп числовых данных через их квартили.Коробчатые диаграммы также могут иметь линий, идущих вертикально на из прямоугольников ( усов, ) , указывающих на изменчивость за пределами верхнего и нижнего квартилей, отсюда термины прямоугольная диаграмма и прямоугольная диаграмма. Выбросы могут быть , нанесенными на график как отдельных точек.
Приведенное выше определение предполагает, что если есть выброс, он будет отображаться в виде точки на прямоугольной диаграмме, а другая совокупность будет сгруппирована вместе и отображаться в виде прямоугольников.Давайте попробуем и увидим сами.
import seaborn as snsBoxplot - Distance to Employment Center
sns.boxplot (x = boston_df ['DIS'])
На графике выше показаны три точки от 10 до 12, это выбросы, поскольку они не включены в рамку другое наблюдение, т. е. нет, где рядом с квартилями.
Здесь мы проанализировали однозначный выброс, т.е. мы использовали столбец DIS только для проверки выброса. Но мы также можем проводить многомерный анализ выбросов. Можем ли мы провести многомерный анализ с помощью прямоугольной диаграммы? Ну, это зависит от того, если у вас есть категориальные значения, вы можете использовать их с любой непрерывной переменной и выполнять многомерный анализ выбросов.Поскольку у нас нет категориального значения в нашем наборе данных Boston Housing, нам, возможно, придется забыть об использовании ящичной диаграммы для многомерного анализа выбросов.
Диаграмма рассеяния -
Определение в Википедии
Диаграмма рассеяния - это тип графика или математической диаграммы, использующей декартовы координаты для отображения значений обычно двух переменных для набора данных. Данные отображаются в виде набора из точек , каждая из которых имеет значение , одна переменная , определяющая положение на горизонтальной оси , , и значение , другая переменная , определяющая положение на вертикальной оси , . .
Как следует из определения, диаграмма рассеяния - это набор точек, который показывает значения двух переменных. Мы можем попытаться построить диаграмму рассеяния для двух переменных из нашего набора данных о жилищном строительстве.
fig, ax = plt.subplots (figsize = (16,8))Точечная диаграмма - Доля некоммерческих коммерческих площадей на город по сравнению с полной стоимостью налога на недвижимость
ax.scatter (boston_df ['INDUS'], boston_df ['TAX'])
ax.set_xlabel ('Доля акров, не связанных с розничной торговлей на город ')
ax.set_ylabel (' Полная ставка налога на имущество на $ 10 000 ')
plt.show ()
На графике выше мы видим, что большинство точек данных находятся внизу слева, но есть точки, которые далеки от населения, например, в правом верхнем углу.
Выявление выбросов с помощью математической функции
Z-Score-
Определение Википедии
Z-score - это стандартное отклонение со знаком, на которое значение наблюдения или точки данных превышает среднее значение того, что наблюдается или измеряется.
Интуиция, стоящая за Z-оценкой, состоит в том, чтобы описать любую точку данных, найдя их связь со стандартным отклонением и средним значением группы точек данных.Z-оценка находит распределение данных, где среднее значение равно 0, а стандартное отклонение равно 1, то есть нормальное распределение.
Вам должно быть интересно, как это помогает в идентификации выбросов? Что ж, при вычислении Z-показателя мы повторно масштабируем и центрируем данные и ищем точки данных, которые слишком далеки от нуля. Эти точки данных, которые слишком далеки от нуля, будут рассматриваться как выбросы. В большинстве случаев используется порог 3 или -3, то есть, если значение Z-оценки больше или меньше 3 или -3 соответственно, эта точка данных будет идентифицирована как выбросы.
Мы будем использовать функцию Z-score, определенную в библиотеке scipy, для обнаружения выбросов.
из scipy import statsZ-score of Boston Housing Data
import numpy as npz = np.abs (stats.zscore (boston_df))
print (z)
Глядя на код и выходные данные выше, трудно сказать какая точка данных является выбросом. Давайте попробуем определить порог для выявления выброса.
порог = 3
печать (np.where (z> 3))
Это даст результат, как показано ниже -
Точки данных, где Z-оценка больше 3Результаты не могут вас смутить.Первый массив содержит список номеров строк, а второй массив номеров соответствующих столбцов, что означает, что z [55] [1] имеют Z-оценку выше 3.
print (z [55] [1]) 3.375038763517309
Итак , точка данных - 55-я запись в столбце ZN является выбросом.
Оценка IQR -
График в виде прямоугольников использует метод IQR для отображения данных и выбросов (форма данных), но для того, чтобы получить список идентифицированных выбросов, нам нужно будет использовать математическую формулу и получить выброс данные.
Определение Википедии
Межквартильный диапазон ( IQR ), также называемый средним или средним 50% , или технически H-разбросом , является мерой статистической дисперсии, равной разница между 75-м и 25-м процентилями или между верхним и нижним квартилями, IQR = Q 3 - Q 1.
Другими словами, IQR - это первый квартиль, вычитаемый из третьего квартиля; эти квартили можно четко увидеть на прямоугольной диаграмме данных.
Это мера дисперсии, аналогичная стандартному отклонению или дисперсии, но гораздо более устойчивая к выбросам.
IQR в некоторой степени похож на Z-оценку с точки зрения определения распределения данных и последующего сохранения некоторого порога для выявления выброса.
Давайте выясним, что мы можем использовать коробчатый график с использованием IQR и как мы можем использовать его для поиска списка выбросов, как мы это делали при вычислении Z-показателя. Сначала мы рассчитаем IQR,
Q1 = boston_df_o1.quantile (0.25)
Q3 = boston_df_o1.quantile (0,75)
IQR = Q3 - Q1
print (IQR)
Здесь мы получим IQR для каждого столбца.
IQR для каждого столбцаПоскольку теперь у нас есть оценки IQR, пора зафиксировать выбросы. Приведенный ниже код даст результат с некоторыми истинными и ложными значениями. Точка данных, где у нас есть False, означает, что эти значения действительны, тогда как True указывает на наличие выброса.
print (boston_df_o1 <(Q1 - 1.5 * IQR)) | (boston_df_o1> (Q3 + 1.5 * IQR))Обнаружение выбросов с помощью IQR
Теперь, когда мы знаем, как обнаруживать выбросы, важно понимать, нужны ли они быть удаленным или исправленным.В следующем разделе мы рассмотрим несколько методов удаления выбросов и, при необходимости, подстановки новых значений.
Во время анализа данных, когда вы обнаруживаете выброс, одним из самых сложных решений может быть то, как поступить с выбросом. Должны ли они их удалить или исправить? Прежде чем мы поговорим об этом, мы рассмотрим несколько методов удаления выбросов.
Z-Score
В предыдущем разделе мы видели, как можно обнаружить выбросы, используя Z-оценку, но теперь мы хотим удалить или отфильтровать выбросы и получить чистые данные.Это можно сделать с помощью всего одного строчного кода, поскольку мы уже рассчитали Z-оценку.
boston_df_o = boston_df_o [(z <3) .all (axis = 1)]С и без размера выброса набора данных
Итак, приведенный выше код удалил около 90+ строк из набора данных, т.е. выбросы были удалены.
Оценка IQR -
Так же, как Z-оценка, мы можем использовать ранее рассчитанную оценку IQR, чтобы отфильтровать выбросы, сохраняя только действительные значения.
boston_df_out = boston_df_o1 [~ ((boston_df_o1 <(Q1 - 1.5 * IQR)) | (boston_df_o1> (Q3 + 1.5 * IQR))). Any (axis = 1)] boston_df_out.shape
Приведенный выше код удалит выбросы из набора данных.
Существует несколько способов обнаружения и удаления выбросов, но методы, которые мы использовали для этого упражнения, широко используются и просты для понимания.
Следует ли удалять выбросы. Эти мысли могут возникать у каждого аналитика / специалиста по данным хоть раз при каждой проблеме, над которой он работает. Я нашел несколько хороших объяснений -
https: // www.researchgate.net/post/When_is_it_justifiable_to_exclude_outlier_data_points_from_statistical_analyses
https://www.researchgate.net/post/Which_is_the_best_method_for_removing_outliers_in_a_best_method_for_removing_outliers_in_a_a_data_set 9000-data_set 9000-data_set
000-data_set 9000-0003Подводя итог их объяснения - неверные данные, неправильные вычисления, их можно определить как выбросы, и их следует отбросить, но в то же время вы можете захотеть исправить и их, поскольку они изменяют уровень данных i.е. означают, что вызывает проблемы при моделировании данных. Например, 5 человек получают зарплату 10К, 20К, 30К, 40К и 50К, и вдруг один из них начинает получать зарплату 100К. Рассмотрите эту ситуацию, поскольку, если вы являетесь работодателем, новое обновление зарплаты может быть воспринято как необъективное, и вам может потребоваться увеличить зарплату и другим сотрудникам, чтобы сохранить баланс. Итак, может быть несколько причин, по которым вы хотите понять и исправить выбросы.
На протяжении этого упражнения мы видели, как на этапе анализа данных можно столкнуться с некоторыми необычными данными i.е выброс. Мы узнали о методах, которые можно использовать для обнаружения и удаления этих выбросов. Но был поднят вопрос о том, можно ли удалить выбросы. Чтобы ответить на эти вопросы, мы нашли дополнительные материалы для чтения (эти ссылки указаны в предыдущем разделе). Надеюсь, этот пост помог читателям узнать о выбросах.
Note- Для этого упражнения использовались инструменты и библиотеки, указанные ниже.
Framework- Jupyter Notebook, Language- Python, Libraries - библиотека sklearn, Numpy, Panda и Scipy, Plot Lib- Seaborn и Matplot.
.
- Boston Dataset
- Github Repo
- Выбросы KDNuggets
- Обнаружение выбросов