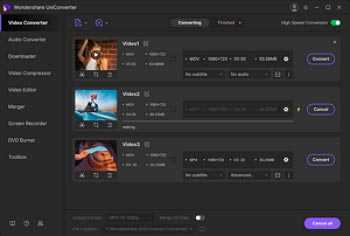
Как сохранить проект c в exe файл
Как сохранить проект в exe
← →Bratyk © (2007-07-21 12:27) [0]
Подскажите как сохранить созданый проект в exe - файл.
← →
Dib@zol © (2007-07-21 12:29) [1]
ГЫГЫГЫГЫГЫ... +1
Ctrl+F9 нажми.
← →
Bratyk © (2007-07-21 13:07) [2]
Да так просто. Спасибо
← →
Virgo_Style © (2007-07-21 13:26) [3]
Dib@zol © (21.07.07 12:29) [1]
А потом он спросит, как оттуда .pas достать, и как ты выкручиваться будешь? =))
← →
Anatoly Podgoretsky © (2007-07-21 13:27) [4]
> Virgo_Style (21.07.2007 13:26:03) [3]
Да как ни будь выкрутимся.
← →
Юрий Зотов © (2007-07-21 13:29) [5]
> Virgo_Style © (21.07.07 13:26) [3]
Обратное действие обычно выполняется теми же клавишами + Shift. То есть, Ctrl+Shift+F9.
← →
ProgRAMmer Dimonych © (2007-07-21 13:50) [6]
Фигня товарищи. SFX-архивы - рулят.
← →
ASoft (2007-07-21 14:57) [7]
oх, Bratyk, нашел бы ты себе сестренку с книжкой по Delphi.. :-)
← →
PEAKTOP © (2007-07-21 15:15) [8]
> Подскажите как сохранить созданый проект в exe - файл.
> Ctrl+F9 нажми.
> Да так просто. Спасибо
С ума сойти... куда этот мир катиться...
← →
Kostafey © (2007-07-22 00:20) [9]
Не, зря вопрос хороший.
Я вот как-то ~ 7 лет назад пытался
выяснить как это делается для QBASIC.
Так и не выяснил, как и следовало ожидать :)
← →
Vendict © (2007-07-22 00:44) [10]
Kostafey © (22.07.07 0:20) [9]
самое интересное было искать( в 7классе это было )) ), как заставить Турбо Паскаль компилировать в exe-шник. он просто по умолчанию компилировал в память... ностальгия. )
← →
Kostafey © (2007-07-22 01:10) [11]
> [10] Vendict © (22.07.07 00:44)
Да, да в Turbo Basic - такая же история,
куда компилируется код в памать или на диск переключается в настройках.
Компиляция вашей первой программы в C++ | Уроки С++
Обновл. 17 Сен 2020 |
Перед написанием нашей первой программы мы еще должны кое-что узнать.
Теория
Во-первых, несмотря на то, что код ваших программ находится в файлах .cpp, эти файлы добавляются в проект. Проект содержит все необходимые файлы вашей программы, а также сохраняет указанные вами настройки вашей IDE. Каждый раз, при открытии проекта, он запускается с того момента, на котором вы остановились в прошлый раз. При компиляции программы, проект говорит компилятору и линкеру, какие файлы нужно скомпилировать, а какие связать. Стоит отметить, что файлы проекта одной IDE не будут работать в другой IDE. Вам придется создать новый проект (в другой IDE).
Во-вторых, есть разные типы проектов. При создании нового проекта, вам нужно будет выбрать его тип. Все проекты, которые мы будем создавать на данных уроках, будут консольного типа. Это означает, что они запускаются в консоли (аналог командной строки). По умолчанию, консольные приложения не имеют графического интерфейса пользователя — GUI (сокр. от «Graphical User Interface») и компилируются в автономные исполняемые файлы. Это идеальный вариант для изучения языка C++, так как он сводит всю сложность к минимуму.
В-третьих, при создании нового проекта большинство IDE автоматически добавят ваш проект в рабочее пространство. Рабочее пространство — это своеобразный контейнер, который может содержать один или несколько связанных проектов. Несмотря на то, что вы можете добавить несколько проектов в одно рабочее пространство, все же рекомендуется создавать отдельное рабочее пространство для каждой программы. Это намного упрощает работу для новичков.
Традиционно, первой программой на новом языке программирования является всеми известная программа «Hello, world!». Мы не будем нарушать традиции 🙂
Пользователям Visual Studio
Для создания нового проекта в Visual Studio 2019, вам нужно сначала запустить эту IDE, затем выбрать "Файл" > "Создать" > "Проект":
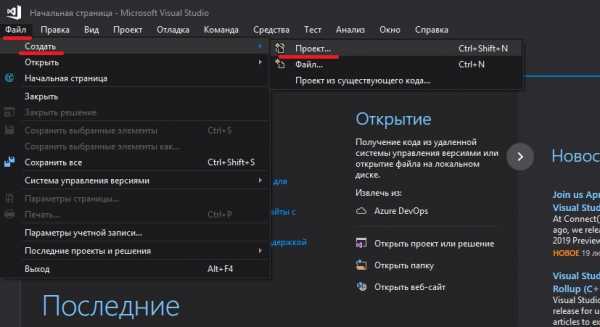
Дальше появится диалоговое окно, где вам нужно будет выбрать "Консольное приложение Windows" из вкладки "Visual C++" и нажать "ОК":

Также вы можете указать имя проекта (любое) и его расположение (рекомендую ничего не менять) в соответствующих полях.
В текстовом редакторе вы увидите, что уже есть некоторый текст и код — удалите его, а затем напечатайте или скопируйте следующий код:
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; }
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; } |
Вот, что у вас должно получиться:

ВАЖНОЕ ПРИМЕЧАНИЕ: Строка #include "pch.h" требуется только для пользователей Visual Studio 2017. Если вы используете Visual Studio 2019 (или более новую версию), то не нужно писать эту строку вообще.
Чтобы запустить программу в Visual Studio, нажмите комбинацию
Ctrl+F5. Если всё хорошо, то вы увидите следующее:
Это означает, что компиляция прошла успешно и результат выполнения вашей программы следующий:
Hello, world!
Чтобы убрать строку «…завершает работу с кодом 0…», вам нужно перейти в "Отладка" > "Параметры":

Затем "Отладка" > "Общие" и поставить галочку возле "Автоматически закрыть консоль при остановке отладки" и нажать "ОК":

Тогда ваше консольное окно будет выглядеть следующим образом:
Готово! Мы научились компилировать программу в Visual Studio.
Пользователям Code::Blocks
Чтобы создать новый проект, запустите Code::Blocks, выберите "File" > "New" > "Project":

Затем появится диалоговое окно, где вам нужно будет выбрать "Console application" и нажать "Go":

Затем выберите язык "C++" и нажмите "Next":

Затем нужно указать имя проекта и его расположение (можете создать отдельную папку Projects) и нажать "Next":

В следующем диалоговом окне нужно будет нажать "Finish".
После всех этих манипуляций, вы увидите пустое рабочее пространство. Вам нужно будет открыть папку Sources в левой части экрана и дважды кликнуть по main.cpp:

Вы увидите, что программа «Hello, world!» уже написана!
Для того, чтобы скомпилировать ваш проект в Code::Blocks, нажмите Ctrl+F9, либо перейдите в меню "Build" и выберите "Build". Если всё пройдет хорошо, то вы увидете следующее во вкладке "Build log":
Это означает, что компиляция прошла успешно!
Чтобы запустить скомпилированную программу, нажмите Ctrl+F10, либо перейдите в меню "Build" и выберите "Run". Вы увидите следующее окно:
Это результат выполнения вашей программы.
Пользователям командной строки
Вставьте следующий код в текстовый файл с именем HelloWorld.cpp:
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; }
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; } |
В командной строке напишите:
g++ -o HelloWorld HelloWorld.cpp
Эта команда выполнит компиляцию и линкинг файла HelloWorld.cpp. Для запуска программы напишите:
HelloWorld
Или:
./HelloWorld
И вы увидите результат выполнения вашей программы.
Пользователям веб-компиляторов
Вставьте следующий код в рабочее пространство:
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; }
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; } |
Затем нажмите "Run". Вы должны увидеть результат в окне выполнения.
Пользователям других IDE
Вам нужно:
Шаг №1: Создать консольный проект.
Шаг №2: Добавить файл .cpp в проект (если нужно).
Шаг №3: Вставить следующий код в файл .cpp:
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; }
#include <iostream> int main() { std::cout << "Hello, world!" << std::endl; return 0; } |
Шаг №4: Скомпилировать проект.
Шаг №5: Запустить проект.
Если компиляция прошла неудачно (a.k.a. «О Боже, что-то пошло не так!»)
Всё нормально, без паники. Скорее всего, это какой-то пустяк.
Во-первых, убедитесь, что вы написали код правильно: без ошибок и опечаток. Сообщение об ошибке компилятора может дать вам ключ к пониманию того, где и какие ошибки случились.
Во-вторых, просмотрите Урок №7 — там есть решения наиболее распространенных проблем.
Если всё вышесказанное не помогло — «загуглите» проблему. С вероятностью 90% кто-то уже сталкивался с этим раньше и нашел решение.
Заключение
Поздравляем, вы написали, скомпилировали и запустили свою первую программу на языке C++! Не беспокойтесь, если вы не понимаете, что означает весь этот код, приведенный выше. Мы детально всё это рассмотрим на следующих уроках.
Оценить статью:
Загрузка...Поделиться в социальных сетях:
Как преобразовать проект на Scratch в формат ехе и в swf
20.09.2018 by scratchbook2015
Для того чтобы запустить проект на Scratch на любом компьютере, даже где не установлен редактор Scratch
И где нет подключения к интернету пригодится этот способ, которому меня научил великий маг Никита Кот
Перейдите на по ссылке сайт, который сконвертирует проект на Скретч с расширением sb2 в проект на флеш с расширением swf
https://junebeetle.github.io/converter/online/
Нажмите на Flash Player
Нажмите Разрешить
Нажмите на кнопку Open Scratch File
Выберите файл с расширением sb2 и нажмите открыть
Нажмите Convert to SWF
Вручную введите имя файла с расширением swf и нажмите Сохранить
Скачайте по ссылке и запустите flashplayer10
https://yadi.sk/d/wDfPE3n23XMRve
Нажмите Файл
Выберите swf файл
Проект откроется в плеере.
Нажмите Файл – Создать проектор
введите имя файла с расширением ехе и нажмите Сохранить.
Готово!
Теперь у вас есть екзешник, который можно запускать на любом компе!
Создаем EXE / Хабр
Самоизоляция это отличное время приступить к тому, что требует много времени и сил. Поэтому я решил заняться тем, чем всегда хотел — написать свой компилятор.Сейчас он способен собрать Hello World, но в этой статье я хочу рассказать не про парсинг и внутреннее устройство компилятора, а про такую важную часть как побайтовая сборка exe файла.
Начало
Хотите спойлер? Наша программа будет занимать 2048 байт.
Обычно работа с exe файлами заключается в изучении или модификации их структуры. Сами же исполняемые файлы при этом формируют компиляторы, и этот процесс кажется немного магическим для разработчиков.
Но сейчас мы с вами попробуем это исправить!
Для сборки нашей программы нам потребуется любой HEX редактор (лично я использовал HxD).
Для старта возьмем псевдокод:
Исходный кодfunc MessageBoxA(u32 handle, PChar text, PChar caption, u32 type) i32 ['user32.dll'] func ExitProcess(u32 code) ['kernel32.dll'] func main() { MessageBoxA(0, 'Hello World!', 'MyApp', 64) ExitProcess(0) } Первые две строки указывают на функции импортируемые из библиотек WinAPI. Функция MessageBoxA выводит диалоговое окно с нашим текстом, а ExitProcess сообщает системе о завершении программы.
Рассматривать отдельно функцию main нет смысла, так как в ней используются функции, описанные выше.
DOS Header
Для начала нам нужно сформировать корректный DOS Header, это заголовок для DOS программ и влиять на запуск exe под Windows не должен.
Более-менее важные поля я отметил, остальные заполнены нулями.
Стуктура IMAGE_DOS_HEADERStruct IMAGE_DOS_HEADER { u16 e_magic // 0x5A4D "MZ" u16 e_cblp // 0x0080 128 u16 e_cp // 0x0001 1 u16 e_crlc u16 e_cparhdr // 0x0004 4 u16 e_minalloc // 0x0010 16 u16 e_maxalloc // 0xFFFF 65535 u16 e_ss u16 e_sp // 0x0140 320 u16 e_csum u16 e_ip u16 e_cs u16 e_lfarlc // 0x0040 64 u16 e_ovno u16[4] e_res u16 e_oemid u16 e_oeminfo u16[10] e_res2 u32 e_lfanew // 0x0080 128 } Самое главное, что этот заголовок содержит поле e_magic означающее, что это исполняемый файл, и e_lfanew — указывающее на смещение PE-заголовка от начала файла (в нашем файле это смещение равно 0x80 = 128 байт).
Отлично, теперь, когда нам известна структура заголовка DOS Header запишем ее в наш файл.
(1) RAW DOS Header (Offset 0x00000000)4D 5A 80 00 01 00 00 00 04 00 10 00 FF FF 00 00 40 01 00 00 00 00 00 00 40 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 80 00 00 00 
УточнениеГотово, первые 64 байта записали. Теперь нужно добавить еще 64, это так называемый DOS Stub (Заглушка). Во время запуска из-под DOS, она должна уведомить пользователя что программа не предназначена для работы в этом режиме.Сначала я использовал левую колонку как на скриншоте для указания смещения внутри файла, но тогда неудобно копировать исходный текст, приходится обрезать каждую строку.
Поэтому для удобства в первой скобке каждого блока указан порядок добавления в файл, а в последней смещение в файле (Offset) по которому должен располагаться данный блок.
Например, первый блок мы вставляем по смещению 0x00000000, и он займет 64 байта (0x40 в 16-ричной системе), следующий блок мы будем вставлять уже по этому смещению 0x00000040 и т.д.
Но в целом, это маленькая программа под DOS которая выводит строку и выходит из программы.
Запишем наш Stub в файл и рассмотрим его детальнее.
0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68 69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F 74 20 62 65 20 72 75 6E 20 69 6E 20 44 4F 53 20 6D 6F 64 65 2E 0D 0A 24 00 00 00 00 00 00 00 00 
А теперь этот же код, но уже в дизассемблированном виде Asm DOS Stub
0000 push cs ; Запоминаем Code Segment(CS) (где мы находимся в памяти) 0001 pop ds ; Указываем что Data Segment(DS) = CS 0002 mov dx, 0x0E ; Указываем адрес начала строки DS+DX, которая будет выводиться до символа $(Конец строки) 0005 mov ah, 0x09 ; Номер инструкции (Вывод строки) 0007 int 0x21 ; Вызов системного прерывания 0x21 0009 mov ax, 0x4C01 ; Номер инструкции 0x4C (Выход из программы) ; Код выхода из программы 0x01 (Неудача) 000c int 0x21 ; Вызов системного прерывания 0x21 000e "This program cannot be run in DOS mode.\x0D\x0A$" ; Выводимая строка Это работает так: сначала заглушка выводит строку о том, что программа не может быть запущена, а затем выходит из программы с кодом 1. Что отличается от нормального завершения (Код 0).
Код заглушки может немного отличатся (от компилятора к компилятору) я сравнивал gcc и delphi, но общий смысл одинаковый.
А еще забавно, что строка заглушки заканчивается как \x0D\x0D\x0A$. Скорее всего причина такого поведения в том, что c++ по умолчанию открывает файл в текстовом режиме. В результате символ \x0A заменяется на последовательность \x0D\x0A. В результате получаем 3 байта: 2 байта возврата каретки Carriage Return (0x0D) что бессмысленно, и 1 на перевод строки Line Feed (0x0A). В бинарном режиме записи (std::ios::binary) такой подмены не происходит.
Для проверки корректности записи значений я буду использовать Far с плагином ImpEx:

NT Header
Спустя 128 (0x80) байт мы добрались до NT заголовка (IMAGE_NT_HEADERS64), который содержит в себе и PE заголовок (IMAGE_OPTIONAL_HEADER64). Несмотря на название IMAGE_OPTIONAL_HEADER64 является обязательным, но различным для архитектур x64 и x86. Структура IMAGE_NT_HEADERS64
Struct IMAGE_NT_HEADERS64 { u32 Signature // 0x4550 "PE" Struct IMAGE_FILE_HEADER { u16 Machine // 0x8664 архитектура x86-64 u16 NumberOfSections // 0x03 Количество секций в файле u32 TimeDateStamp // Дата создания файла u32 PointerToSymbolTable u32 NumberOfSymbols u16 SizeOfOptionalHeader // Размер IMAGE_OPTIONAL_HEADER64 (Ниже) u16 Characteristics // 0x2F } Struct IMAGE_OPTIONAL_HEADER64 { u16 Magic // 0x020B Указывает что наш заголовок для PE64 u8 MajorLinkerVersion u8 MinorLinkerVersion u32 SizeOfCode u32 SizeOfInitializedData u32 SizeOfUninitializedData u32 AddressOfEntryPoint // 0x1000 u32 BaseOfCode // 0x1000 u64 ImageBase // 0x400000 u32 SectionAlignment // 0x1000 (4096 байт) u32 FileAlignment // 0x200 u16 MajorOperatingSystemVersion // 0x05 Windows XP u16 MinorOperatingSystemVersion // 0x02 Windows XP u16 MajorImageVersion u16 MinorImageVersion u16 MajorSubsystemVersion // 0x05 Windows XP u16 MinorSubsystemVersion // 0x02 Windows XP u32 Win32VersionValue u32 SizeOfImage // 0x4000 u32 SizeOfHeaders // 0x200 (512 байт) u32 CheckSum u16 Subsystem // 0x02 (GUI) или 0x03 (Console) u16 DllCharacteristics u64 SizeOfStackReserve // 0x100000 u64 SizeOfStackCommit // 0x1000 u64 SizeOfHeapReserve // 0x100000 u64 SizeOfHeapCommit // 0x1000 u32 LoaderFlags u32 NumberOfRvaAndSizes // 0x16 Struct IMAGE_DATA_DIRECTORY [16] { u32 VirtualAddress u32 Size } } } Разберемся что хранится в этой структуре: Описание IMAGE_NT_HEADERS64 Signature — Указывает на начало структуры PE заголовка
Далее идет заголовок IMAGE_FILE_HEADER общий для архитектур x86 и x64.
Machine — Указывает для какой архитектуры предназначен код в нашем случае для x64
NumberOfSections — Количество секции в файле (О секциях чуть ниже)
TimeDateStamp — Дата создания файла
SizeOfOptionalHeader — Указывает размер следующего заголовка IMAGE_OPTIONAL_HEADER64, ведь он может быть заголовком IMAGE_OPTIONAL_HEADER32.
Characteristics — Здесь мы указываем некоторые атрибуты нашего приложения, например, что оно является исполняемым (EXECUTABLE_IMAGE) и может работать более чем с 2 Гб RAM (LARGE_ADDRESS_AWARE), а также что некоторая информация была удалена (на самом деле даже не была добавлена) в файл (RELOCS_STRIPPED | LINE_NUMS_STRIPPED | LOCAL_SYMS_STRIPPED).
SizeOfCode — Размер исполняемого кода в байтах (секция .text)
SizeOfInitializedData — Размер инициализированных данных (секция .rodata)
SizeOfUninitializedData — Размер не инициализированных данных (секция .bss)
BaseOfCode — указывает на начало секции кода блок
SectionAlignment — Размер по которому нужно выровнять секции в памяти
FileAlignment — Размер по которому нужно выровнять секции внутри файла
SizeOfImage — Размер всех секций программы
SizeOfHeaders — Размер всех заголовков вместе (IMAGE_DOS_HEADER, DOS Stub, IMAGE_NT_HEADERS64, IMAGE_SECTION_HEADER[IMAGE_FILE_HEADER.NumberOfSections]) выровненный по FileAlignment
Subsystem — Указывает тип нашей программы GUI или Console
MajorOperatingSystemVersion, MinorOperatingSystemVersion, MajorSubsystemVersion, MinorSubsystemVersion — Говорят о том на какой системе можно запускать данный exe, и что он может поддерживать. В нашем случае мы берем значение 5.2 от Windows XP (x64).
SizeOfStackReserve — Указывает сколько приложению нужно зарезервировать памяти под стек. Этот параметр по умолчанию составляет 1 Мб, максимально можно указать 1Гб. Вроде как умные программы на Rust умеют считать необходимый размер стека, в отличии от программ на C++ где этот размер нужно править вручную.
SizeOfStackCommit — Размер по умолчанию составляет 4 Кб. Как должен работать данный параметр пока не разобрался.
SizeOfHeapReserve — Указывает сколько резервировать памяти под кучу. Равен 1 Мб по умолчанию.
SizeOfHeapCommit — Размер по умолчанию равен 4 Кб. Подозреваю что работает аналогично SizeOfStackCommit, то есть пока неизвестно как.
IMAGE_DATA_DIRECTORY — массив записей о каталогах. В теории его можно уменьшить, сэкономив пару байт, но вроде как все описывают все 16 полей даже если они не нужны. А теперь чуть подробнее.
У каждого каталога есть свой номер, который описывает, где хранится его содержимое. Пример:
Export(0) — Содержит ссылку на сегмент который хранит экспортируемые функции. Для нас это было бы актуально если бы мы создавали DLL. Как это примерно должно работать можно посмотреть на примере следующего каталога.
Import(1) — Этот каталог указывает на сегмент с импортируемыми функциями из других DLL. В нашем случае значения VirtualAddress = 0x3000 и Size = 0xB8. Это единственный каталог, который мы опишем.
Resource(2) — Каталог с ресурсами программы (Изображения, Текст, Файлы и т.д.)
Значения других каталогов можно посмотреть в документации.
Теперь, когда мы посмотрели из чего состоит NT-заголовок, запишем и его в файл по аналогии с остальными по адресу 0x80. (3) RAW NT-Header (Offset 0x00000080)
50 45 00 00 64 86 03 00 F4 70 E8 5E 00 00 00 00 00 00 00 00 F0 00 2F 00 0B 02 00 00 3D 00 00 00 13 00 00 00 00 00 00 00 00 10 00 00 00 10 00 00 00 00 40 00 00 00 00 00 00 10 00 00 00 02 00 00 05 00 02 00 00 00 00 00 05 00 02 00 00 00 00 00 00 40 00 00 00 02 00 00 00 00 00 00 02 00 00 00 00 00 10 00 00 00 00 00 00 10 00 00 00 00 00 00 00 00 10 00 00 00 00 00 00 10 00 00 00 00 00 00 00 00 00 00 10 00 00 00 00 00 00 00 00 00 00 00 00 30 00 00 B8 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 В результате получаем вот такой вид IMAGE_FILE_HEADER, IMAGE_OPTIONAL_HEADER64 и IMAGE_DATA_DIRECTORY заголовков:


Далее описываем все секции нашего приложения согласно структуре IMAGE_SECTION_HEADER
Структура IMAGE_SECTION_HEADERStruct IMAGE_SECTION_HEADER { i8[8] Name u32 VirtualSize u32 VirtualAddress u32 SizeOfRawData u32 PointerToRawData u32 PointerToRelocations u32 PointerToLinenumbers u16 NumberOfRelocations u16 NumberOfLinenumbers u32 Characteristics } Описание IMAGE_SECTION_HEADER
Name — имя секции из 8 байт, может быть любым
VirtualSize — сколько байт копировать из файла в память
VirtualAddress — адрес секции в памяти выровненный по SectionAlignment
SizeOfRawData — размер сырых данных выровненных по FileAlignment
PointerToRawData — адрес секции в файле выровненный по FileAlignment
Characteristics — Указывает какие данные хранит секция (Код, инициализированные или нет данные, для чтения, для записи, для исполнения и др.)
В нашем случае у нaс будет 3 секции.
Почему Virtual Address (VA) начинается с 1000, а не с нуля я не знаю, но так делают все компиляторы, которые я рассматривал. В результате 1000 + 3 секции * 1000 (SectionAlignment) = 4000 что мы и записали в SizeOfImage. Это полный размер нашей программы в виртуальной памяти. Вероятно, используется для выделения места под программу в памяти.
Name | RAW Addr | RAW Size | VA | VA Size | Attr --------+---------------+---------------+-------+---------+-------- .text | 200 | 200 | 1000 | 3D | CER .rdata | 400 | 200 | 2000 | 13 | I R .idata | 600 | 200 | 3000 | B8 | I R Расшифровка атрибутов:
I — Initialized data, инициализированные данные
U — Uninitialized data, не инициализированные данные
C — Code, содержит исполняемый код
E — Execute, позволяет исполнять код
R — Read, позволяет читать данные из секции
W — Write, позволяет записывать данные в секцию
.text (.code) — хранит в себе исполняемый код (саму программу), атрибуты CE
.rdata (.rodata) — хранит в себе данные только для чтения, например константы, строки и т.п., атрибуты IR
.data — хранит данные которые можно читать и записывать, такие как статические или глобальные переменные. Атрибуты IRW
.bss — хранит не инициализированные данные, такие как статические или глобальные переменные. Кроме того, данная секция обычно имеет нулевой RAW размер и ненулевой VA Size, благодаря чему не занимает места в файле. Атрибуты URW
.idata — секция содержащая в себе импортируемые из других библиотек функции. Атрибуты IR
Важный момент, секции должны следовать друг за другом. При чем как в файле, так и в памяти. По крайней мере когда я менял их порядок произвольно программа переставала запускаться.
Теперь, когда нам известно какие секции будет содержать наша программа запишем их в наш файл. Тут смещение оканчивается на 8 и запись будет начинаться с середины файла.
(4) RAW Sections (Offset 0x00000188) 2E 74 65 78 74 00 00 00 3D 00 00 00 00 10 00 00 00 02 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 20 00 00 60 2E 72 64 61 74 61 00 00 13 00 00 00 00 20 00 00 00 02 00 00 00 04 00 00 00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 40 2E 69 64 61 74 61 00 00 B8 00 00 00 00 30 00 00 00 02 00 00 00 06 00 00 00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 40 
Следующий адрес для записи будет 00000200 что соответствует полю SizeOfHeaders PE-Заголовка. Если бы мы добавили еще одну секцию, а это плюс 40 байт, то наши заголовки не уложились бы в 512 (0x200) байт и пришлось бы использовать уже 512+40 = 552 байта выровненные по FileAlignment, то есть 1024 (0x400) байта. А все что останется от 0x228 (552) до адреса 0x400 нужно чем-то заполнить, лучше конечно нулями.
Взглянем как выглядит блок секций в Far:

Далее мы запишем в наш файл сами секции, но тут есть один нюанс.
Как вы могли заметить на примере SizeOfHeaders, мы не можем просто записать заголовок и перейти к записи следующего раздела. Так как что бы записать заголовок мы должны знать сколько займут все заголовки вместе. В результате нам нужно либо посчитать заранее сколько понадобиться места, либо записать пустые (нулевые) значения, а после записи всех заголовков вернуться и записать уже их реальный размер.
Поэтому программы компилируются в несколько проходов. Например секция .rdata идет после секции .text, при этом мы не можем узнать виртуальный адрес переменной в .rdata, ведь если секция .text разрастется больше чем на 0x1000 (SectionAlignment) байт, она займет адреса 0x2000 диапазона. И соответственно секция .rdata будет находиться уже не в адресе 0x2000, а в адресе 0x3000. И нам будет необходимо вернуться и пересчитать адреса всех переменных в секции .text которая идет перед .rdata.
Но в данном случае я уже все рассчитал, поэтому будем сразу записывать блоки кода.
Секция .text
Asm segment .text
0000 push rbp 0001 mov rbp, rsp 0004 sub rsp, 0x20 0008 mov rcx, 0x0 000F mov rdx, 0x402000 0016 mov r8, 0x40200D 001D mov r9, 0x40 0024 call QWORD PTR [rip + 0x203E] 002A mov rcx, 0x0 0031 call QWORD PTR [rip + 0x2061] 0037 add rsp, 0x20 003B pop rbp 003C ret Конкретно для этой программы первые 3 строки, ровно, как и 3 последние не обязательны.
Последние 3 даже не будут исполнены, так как выход из программы произойдет еще на второй функции call.
Но скажем так, если бы это была не функция main, а подфункция следовало бы сделать именно так.
А вот первые 3 в данном случае хоть и не обязательны, но желательны. Например, если бы мы использовали не MessageBoxA, а printf то без этих строк получили бы ошибку.
Согласно соглашению о вызовах для 64-разрядных систем MSDN, первые 4 параметра передаются в регистрах RCX, RDX, R8, R9. Если они туда помещаются и не являются, например числом с плавающей точкой. А остальные передаются через стек.
По идее если мы передаем 2 аргумента функции, то должны передать их через регистры и зарезервировать под них два места в стеке, что бы при необходимости функция могла скинуть регистры в стек. Так же мы не должны рассчитывать, что нам вернут эти регистры в исходном состоянии.
Так вот проблема функции printf заключается в том, что, если мы передаем ей всего 1 аргумент, она все равно перезапишет все 4 места в стеке, хотя вроде бы должна перезаписать только одно, по количеству аргументов.
Поэтому если не хотите, чтобы программа себя странно вела, всегда резервируйте как минимум 8 байт * 4 аргумента = 32(0x20) байт, если передаете функции хотя бы 1 аргумент.
Рассмотрим блок кода с вызовами функций
MessageBoxA(0, 'Hello World!', 'MyApp', 64) ExitProcess(0) Сначала мы передаем наши аргументы:
rcx = 0
rdx = абсолютный адрес строки в памяти ImageBase + Sections[".rdata"].VirtualAddress + Смещение строки от начала секции, строка читается до нулевого байта
r8 = аналогично предыдущему
r9 = 64(0x40) MB_ICONINFORMATION, значок информации
А далее идет вызов функции MessageBoxA, с которым не все так просто. Дело в том, что компиляторы стараются использовать как можно более короткие команды. Чем меньше размер команды, тем больше таких команд влезет в кэш процессора, соответственно, будет меньше промахов кэша, подзагрузок и выше скорость работы программы. Для более подробной информации по командам и внутренней работе процессора можно обратиться к документации Intel 64 and IA-32 Architectures Software Developer’s Manuals.
Мы могли бы вызвать функцию по полному адресу, но это заняло бы как минимум (1 опкод + 8 адрес = 9 байт), а с относительным адресом команда call занимает всего 6 байт.
Давайте взглянем на эту магию поближе: rip + 0x203E, это ни что иное, как вызов функции по адресу, указанному нашим смещением.
Я подсмотрел немного вперед и узнал адреса нужных нам смещений. Для MessageBoxA это 0x3068, а для ExitProcess это 0x3098.
Пора превратить магию в науку. Каждый раз, когда опкод попадает в процессор, он высчитывает его длину и прибавляет к текущему адресу инструкции (RIP). Поэтому, когда мы используем RIP внутри инструкции, этот адрес указывает на конец текущей инструкции / начало следующей.
Для первого call смещение будет указывать на конец команды call это 002A не забываем что в памяти этот адрес будет по смещению Sections[".text"].VirtualAddress, т.е. 0x1000. Следовательно, RIP для нашего call будет равен 102A. Нужный нам адрес для MessageBoxA находится по адресу 0x3068. Считаем 0x3068 — 0x102A = 0x203E. Для второго адреса все аналогично 0x1000 + 0x0037 = 0x1037, 0x3098 — 0x1037 = 0x2061.
Именно эти смещения мы и видели в командах ассемблера.
0024 call QWORD PTR [rip + 0x203E] 002A mov rcx, 0x0 0031 call QWORD PTR [rip + 0x2061] 0037 add rsp, 0x20 Запишем в наш файл секцию .text, дополнив нулями до адреса 0x400: (5) RAW .text section (Offset 0x00000200-0x00000400)
55 48 89 E5 48 83 EC 20 48 C7 C1 00 00 00 00 48 C7 C2 00 20 40 00 49 C7 C0 0D 20 40 00 49 C7 C1 40 00 00 00 FF 15 3E 20 00 00 48 C7 C1 00 00 00 00 FF 15 61 20 00 00 48 83 C4 20 5D C3 00 00 00 ........ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Хочется отметить что всего лишь 4 строки реального кода содержат весь наш код на ассемблере. А все остальное нули что бы набрать FileAlignment. Последней строкой заполненной нулями будет 0x000003F0, после идет 0x00000400, но это будет уже следующий блок. Итого в файле уже 1024 байта, наша программа весит уже целый Килобайт! Осталось совсем немного и ее можно будет запустить.

Секция .rdata
Это, пожалуй, самая простая секция. Мы просто положим сюда две строки добив нулями до 512 байт. .rdata
0400 "Hello World!\0" 040D "MyApp\0" (6) RAW .rdata section (Offset 0x00000400-0x00000600)
48 65 6C 6C 6F 20 57 6F 72 6C 64 21 00 4D 79 41 70 70 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ........ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Секция .idata
Ну вот осталась последняя секция, которая описывает импортируемые функции из библиотек.
Первое что нас ждет новая структура IMAGE_IMPORT_DESCRIPTOR
Структура IMAGE_IMPORT_DESCRIPTORStruct IMAGE_IMPORT_DESCRIPTOR { u32 OriginalFirstThunk (INT) u32 TimeDateStamp u32 ForwarderChain u32 Name u32 FirstThunk (IAT) } Описание IMAGE_IMPORT_DESCRIPTOR
OriginalFirstThunk — Адрес указывает на список имен импортируемых функций, он же Import Name Table (INT)
Name — Адрес, указывающий на название библиотеки
FirstThunk — Адрес указывает на список адресов импортируемых функций, он же Import Address Table (IAT)
Для начала нам нужно добавить 2 импортируемых библиотеки. Напомним:
func MessageBoxA(u32 handle, PChar text, PChar caption, u32 type) i32 ['user32.dll'] func ExitProcess(u32 code) ['kernel32.dll'] (7) RAW IMAGE_IMPORT_DESCRIPTOR (Offset 0x00000600)
58 30 00 00 00 00 00 00 00 00 00 00 3C 30 00 00 68 30 00 00 88 30 00 00 00 00 00 00 00 00 00 00 48 30 00 00 98 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 У нас используется 2 библиотеки, а что бы сказать что мы закончили их перечислять. Последняя структура заполняется нулями.
INT | Time | Forward | Name | IAT --------+--------+----------+--------+-------- 0x3058 | 0x0 | 0x0 | 0x303C | 0x3068 0x3088 | 0x0 | 0x0 | 0x3048 | 0x3098 0x0000 | 0x0 | 0x0 | 0x0000 | 0x0000 Теперь добавим имена самих библиотек: Имена библиотек
063С "user32.dll\0" 0648 "kernel32.dll\0" (8) RAW имена библиотек (Offset 0x0000063С)
75 73 65 72 33 32 2E 64 6C 6C 00 00 6B 65 72 6E 65 6C 33 32 2E 64 6C 6C 00 00 00 00 Далее опишем библиотеку user32: (9) RAW user32.dll (Offset 0x00000658)
78 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 78 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 4D 65 73 73 61 67 65 42 6F 78 41 00 00 00 Поле Name первой библиотеки указывает на 0x303C если мы посмотрим чуть выше, то увидим что по адресу 0x063C находится библиотека «user32.dll\0».
Подсказка, вспомните что секция .idata соответствует смещению в файле 0x0600, а в памяти 0x3000. Для первой библиотеки INT равен 3058, значит в файле это будет смещение 0x0658. По этому адресу видим запись 0x3078 и вторую нулевую. Означающую конец списка. 3078 ссылается на 0x0678 это RAW-строка
«00 00 4D 65 73 73 61 67 65 42 6F 78 41 00 00 00»
Первые 2 байта нас не интересуют и равны нулю. А вот дальше идет строка с названием функции, заканчивающаяся нулем. То есть мы можем представить её как "\0\0MessageBoxA\0".
При этом IAT ссылается на аналогичную таблице IAT структуру, но только в нее при запуске программы будут загружены адреса функций. Например, для первой записи 0x3068 в памяти будет значение отличное от значения 0x0668 в файле. Там будет адрес функции MessageBoxA загруженный системой к которому мы и будем обращаться через вызов call в коде программы.
И последний кусочек пазла, библиотека kernel32. И не забываем добить нулями до SectionAlignment.
(10) RAW kernel32.dll (Offset 0x00000688-0x00000800) A8 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 A8 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 45 78 69 74 50 72 6F 63 65 73 73 00 00 00 00 00 00 00 00 00 00 00 ........ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 
Проверяем что Far смог корректно определить какие функции мы импортировали:

Отлично! Все нормально определилось, значит теперь наш файл готов к запуску.
Барабанная дробь…
Финал

Поздравляю, мы справились!
Файл занимает 2 Кб = Заголовки 512 байт + 3 секции по 512 байт.
Число 512(0x200) ни что иное, как FileAlignment, который мы указали в заголовке нашей программы.
Дополнительно:
Если хочется вникнуть чуть глубже, можно заменить надпись «Hello World!» на что-нибудь другое, только не забудьте изменить адрес строки в коде программы (секция .text). Адрес в памяти 0x00402000, но в файле будет обратный порядок байт 00 20 40 00.
Или квест чуть сложнее. Добавить в код вызов ещё одного MessageBox. Для этого придется скопировать предыдущий вызов, и пересчитать в нем относительный адрес (0x3068 — RIP).
Заключение
Статья получилась достаточно скомканной, ей бы, конечно, состоять из 3 отдельных частей: Заголовки, Программа, Таблица импорта.
Если кто-то собрал свой exe значит мой труд был не напрасен.
Думаю в скором времени создать ELF файл похожим образом, интересна ли будет такая статья?)
Ссылки:
Как отлаживать и профилировать любой EXE-файл с помощью Visual Studio
Вам когда-нибудь нужно было отлаживать или профилировать исполняемый файл (файл .exe), для которого у вас нет исходного кода или вы не можете его собрать? Тогда наименее известный тип проекта Visual Studio, проект EXE, для вас!В Visual Studio вы можете открыть любой EXE-файл как «проект». Просто перейдите в Файл -> Открыть -> Проект/Решение и перейдите к файлу .exe . Как если бы это был файл .sln . Visual Studio откроет этот EXE-файл как проект. Эта функция существует уже давно. Она работает на всех поддерживаемых в настоящее время версиях Visual Studio, и документация по ней находится на странице Отладка приложения, которое не является частью решения Visual Studio.

Отладка
Как и в обычном проекте, вы можете начать отладку с помощью F5, которая запустит EXE и подключит отладчик. Если вы хотите отладить запуск, вы можете запустить с помощью F11, который запустит EXE и остановится на первой строке пользовательского кода. Оба эти параметра доступны в контекстном меню для проекта EXE в окне Solution Explorer, как показано ниже:
Для отладки понадобятся символы, файлы PDB, для EXE и любых DLL, которые нужно отладить. Visual Studio будет следовать тому же процессу и попытается получить символы также, как и при отладке обычного проекта. Поскольку маловероятно, что файлы PDB были распространены вместе с EXE-файлом, возможно, вы захотите найти их в сборке или, что еще лучше, на сервере символов. Дополнительную информацию и рекомендации по использованию символов можно найти в этом блоге.
Для эффективной отладки вам также понадобится исходный код, который использовался для сборки EXE, или даже для нескольких файлов, которые вас интересуют. Вам нужно найти эти файлы и открыть их в Visual Studio. Если исходный код не совпадает с исходным кодом, который был собран, EXE Visual Studio предупредит вас, когда вы попытаетесь вставить точку останова, и точка останова не будет привязана. Это поведение может быть изменено в окне Settings peek window. В окне просмотра параметров щелкните текст ссылки Must match source, а затем установите флажок, чтобы разрешить несоответствующий источник, как показано ниже. Конечно, с несоответствующим источником вы никогда не знаете, что произойдет, так что используйте это только на свой страх и риск.

Если EXE был собран с SourceLink, то информация об источнике будет включена в PDB, и Visual Studio попытается загрузить источник автоматически. Это действительно хорошая причина использовать SourceLink с вашими проектами. Даже если у вас есть локальный набор, у вас может не быть той версии, которая использовалась для сборки двоичного файла. SourceLink — ваш надежный способ убедиться, что правильный источник связан с правильным двоичным файлом.
Если вы не можете получить исходный код, у вас еще есть несколько вариантов:
- Используйте инструмент для декомпиляции сборок обратно в C#, который вы можете перекомпилировать в новую сборку, чтобы исправить старую.
- ILSpy — отличный выбор для этого, но есть и множество других хороших платных и бесплатных инструментов.
- Используйте окно инструмента «Disassembly» в Visual Studio.
- Документ Source Not Found содержит ссылку на view disassembly. Имейте в виду, что если вы привыкли к отладке кода на C#, представление о разборке (view disassembly) является крайним средством.
Наконец, если вам нужно передать какие-либо аргументы в отлаживаемый EXE-файл, вы можете настроить их вместе с другими параметрами на странице Свойства проекта (Щелкните правой кнопкой мыши -> Свойства в узле проекта в обозревателе решений).

Профилирование
Вы также можете использовать инструменты профилирования с EXE-файлом, запустив их из Отладка -> Профилирование производительности. На странице запуска инструментов профилирования вы можете выбрать, какие инструменты использовать против EXE. Дополнительную информацию о профилировании можно найти в этих документах ( https://docs.microsoft.com/en-us/visualstudio/profiling/profiling-feature-tour?view=vs-2019).

Заключение
Вот и все. Краткий обзор того, как вы можете использовать Visual Studio для отладки и профилирования приложений, которые вы не создаете и которые могут даже не иметь исходного кода. В следующий раз, когда вам понадобится отладить или профилировать EXE-файл, не забудьте, что вы можете открыть его как решение в Visual Studio!
Как скопировать .exe из проекта C ++ в выходной каталог проекта C #?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Как открыть .exe из другого C ++ .exe?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
Как сохранить расширение Chrome как файл .exe?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
Как сохранить файлы в папке проекта c #
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
c # - Сохранение файла в указанной папке внутри моего проекта
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся
visual studio - как добавить внешний .exe в мой проект C #?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя