Как узнать коэффициент сжатия файла
Как узнать степень сжатия файлов архива пошаговая инструкция
E-mail: [email protected]
Этот сайт использует cookie для хранения данных. Продолжая использовать сайт, Вы даете свое согласие на работу с этими файламиВНИМАНИЕ! При копировании материалов с сайта, активная обратная ссылка на kompmix.ru - обязательна.
kompmix.ru © 2020 Все права защищены.
Как посмотреть степень сжатия архива – инструкция
Приветствую!
В этой подробной пошаговой инструкции, с фотографиями, мы покажем вам, как узнать степень сжатия файлов в архиве.
Воспользовавшись этой инструкцией, вы с легкостью справитесь с данной задачей.
Узнаём степень сжатия архива
Для определения степени сжатия на компьютере должен быть установлен архиватор WinRar. Если он у вас не установлен, то вот в этой подобной пошаговой инструкции рассказывается о том, где его бесплатно скачать и как установить.
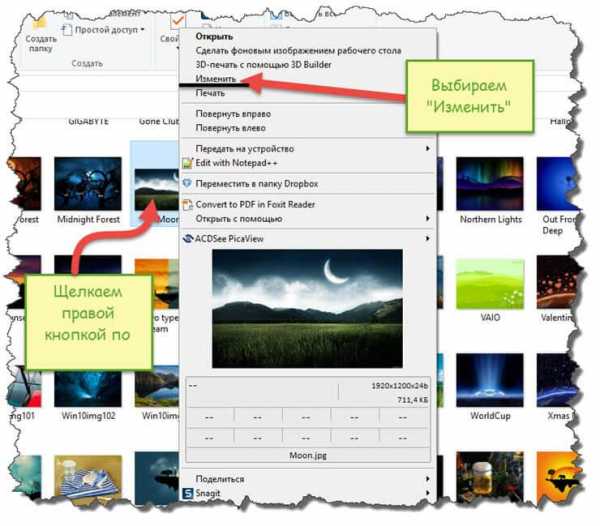
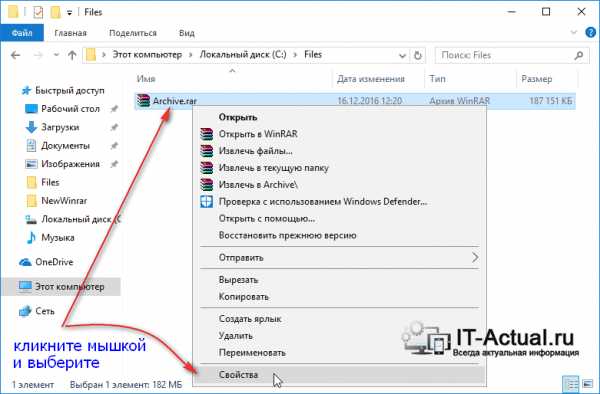 Вызовите контекстное меню, кликнув правой клавишей мышки на интересующем архиве, для которого требуется определить степень сжатия.
Вызовите контекстное меню, кликнув правой клавишей мышки на интересующем архиве, для которого требуется определить степень сжатия.
В нём выберите пункт Свойства.
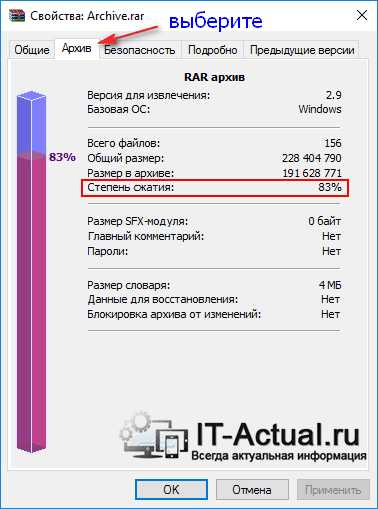 В открывшемся окне перейдите во вкладку Архив. Там в строке Степень сжатия будет указан интересующий нас параметр.
В открывшемся окне перейдите во вкладку Архив. Там в строке Степень сжатия будет указан интересующий нас параметр.
Если у вас остались вопросы, вы можете задать их в комментариях.
Мы рады, что смогли помочь Вам в решении поставленной задачи или проблемы.В свою очередь, Вы тоже можете нам очень помочь.
Просто поделитесь статьей в социальных сетях и мессенджерах с друзьями.
Поделившись результатами труда автора, вы окажете неоценимую помощь как ему самому, так и сайту в целом. Спасибо!
Опрос: помогла ли вам эта статья?(cбор пожертвований осуществляется через сервис «ЮMoney»)
На что пойдут пожертвования \ реквизиты других платёжных систем Привет.Не секрет, что в экономике ныне дела обстоят не лучшим образом, цены растут, а доходы падают. И данный сайт также переживает нелёгкие времена :-(
Если у тебя есть возможность и желание помочь развитию ресурса, то ты можешь перевести любую сумму (даже самую минимальную) через форму пожертвований, или на следующие реквизиты:
Номер банковской карты: 5331 5721 0220 5546
Кошелёк ЮMoney: 410015361853797
Кошелёк WebMoney: P865066858877
PayPal: [email protected]
QIWI кошелёк: +79687316794
BitCoin: 1DZUZnSdcN6F4YKhf4BcArfQK8vQaRiA93
Оказавшие помощь:
Сергей И. - 500руб
<аноним> - 468руб
<аноним> - 294руб
Мария М. - 300руб
Валерий С. - 420руб
<аноним> - 600руб
Полина В. - 240руб
Деньги пойдут на оплату хостинга, продление домена, администрирование и развитие ресурса. Спасибо.
С уважением, создатель сайта IT-Actual.ru
§16. Сжатие данных
Содержание урока
Зачем и как сжимать данные?
Сжатие без потерь
Сжатие с потерями
Программы-архиваторы
Выводы. Интеллект-карта
Вопросы и задания
Практическая работа № 5 «Использование архиватора»
Зачем и как сжимать данные?
Ключевые слова:
• сжатие данных • коэффициент сжатия • сжатие без потерь • сжатие с потерями • архивация • самораспаковывающийся архив • программа-архиватор • контрольная сумма
Для того чтобы сэкономить место на внешних носителях (жёстких дисках, «флэшках») или ускорить передачу данных по компьютерным сетям, можно сжать данные — уменьшить их информационный объём, сократить размер файла.
Как вы уже знаете, рисунки часто хранятся в сжатом виде. Кроме того, сжатие почти всегда используется при хранении и передаче звука и видео — упаковку и распаковку этих данных выполняют специальные программы-кодеки.
Покажем, как можно сжать данные, на простом примере. Есть файл, в котором в 8-битной кодировке записаны сначала 100 русских букв А, а потом — 100 букв Б (рис. 2.39).
Рис. 2.39
Каждая буква на рис. 2.39 занимает 8 бит. Определите информационный объём файла в байтах.
Теперь запишем те же самые данные иначе: сначала количество повторений первого символа, а затем — сам первый символ, потом так же для второго символа (рис. 2.40).
Рис. 2.40
Каждая ячейка на рис. 2.40 занимает 8 бит. Определите информационный объём файла в байтах.
Объём файла уменьшился, это значит, что мы сжали данные.
Коэффициент сжатия — это отношение размера исходного файла IO к размеру сжатого файла IСЖ: kсж = IO / IСЖ
Определите коэффициент сжатия файла в рассмотренном выше примере.
Почему же этот файл удалось так удачно сжать? Всё дело в том, что в нём были длинные цепочки повторяющихся символов, и мы применили алгоритм, который очень удачно их сжимает. Этот алгоритм называется кодированием цепочек одинаковых символов (по-английски — RLE 1) : Run Length Encoding).
1) Алгоритм RLE можно успешно использовать для сжатия рисунков, в которых большие области закрашены одним цветом.
В файле записаны 100 различных символов. Определите коэффициент сжатия файла с помощью алгоритма RLE. Что означает полученное число?
Данные можно сжать, если в них есть какие-то закономерности (избыточность), например одинаковые символы, стоящие рядом, или одинаковые цепочки символов («слова»). Поэтому хорошо сжимаются данные, в которых таких закономерностей много, например тексты и рисунки. Хуже всего сжимаются случайные данные, в которых нет ничего закономерного.
Программы для сжатия данных выявляют избыточность данных и устраняют её, поэтому сжимать второй раз уже сжатые данные чаще всего бесполезно.
Следующая страница Сжатие без потерь
Cкачать материалы урока
Показатель степени сжатия файлов — Студопедия.Нет
Реферат на тему: "Программы-архиваторы"
Выполнила: Дмитриева Диана
Содержание
1.Введение
2.Основные виды программ-архиваторов
3.Сжатие файлов при архивации
4. Показатель степени сжатия файлов
5. Оценка функциональности самых популярных архиваторов
5.1 WinZip
5.2 WinRAR
5.3 WinAce
5.4 7-Zip
6.Заключение
7.Список литературы
Введение
Архивация - это сжатие, уплотнение, упаковка информации с целью ее более рационального размещения на внешнем носителе (диске или дискете). Архиваторы - это программы, реализующие процесс архивации, позволяющие создавать и распаковывать архивы.
Необходимость архивации связана с резервным копированием информации на диски и дискеты с целью сохранения программного обеспечения компьютера и защиты его от порчи и уничтожения (умышленного, случайного или под действием компьютерного вируса). Чтобы уменьшить потери информации, следует иметь резервные копии всех программ и файлов.
Программы-упаковщики (архиваторы) позволяют за счет специальных методов сжатия информации создавать копии файлов меньшего размера и объединять копии нескольких файлов в один архивный файл. Это даёт возможность на дисках или дискетах разместить больше информации, то есть повысить плотность хранения информации на единицу объёма носителя (дискеты или диска).
Кроме того, архивные файлы широко используются для передачи информации в Интернете и по электронной почте, причем благодаря сжатию информации повышается скорость её передачи. Это особенно важно, если учесть, что быстродействие модема и канала связи (телефонной линии) намного меньше, чем процессора и жесткого диска.
Работа архиваторов основана на том, что они находят в файлах повторяющиеся участки и пробелы, помечают их в архивном файле и затем при распаковке восстанавливают по этим отметкам исходные файлы.
Программы-упаковщики (или архиваторы) позволяют помещать копии файлов в архив и извлекать файлы из архива, просматривать оглавление архива и тестировать его целостность, удалять файлы, находящиеся в архиве, и обновлять их, устанавливать пароль при извлечении файлов из архива и др. Разные программы архивации отличаются форматом архивных файлов, скоростью работы, степенью сжатия, набором услуг (полнотой меню для пользователя), удобством пользования (интерфейсом), наличием помощи, собственным размером.
Ряд архиваторов позволяют создавать многотомные архивы, самоизвлекающиеся архивы, архивы, содержащие каталоги. Наиболее популярны и широко используются следующие архиваторы: ARJ, PKZIP/PKUNZIP, RAR, ACE, LHA, ICE, PAK, PKARC/PKXARC, ZOO, HYPER, AIN.
Наиболее высокоэффективными являются архиваторы RAR, ACE, AIN, ARJ.
Основные виды программ-архиваторов
Различными разработчиками были созданы специальные программы для архивации файлов. Как правило, программы для архивации файлов позволяют помещать копии файлов на диске в сжатом виде в архивный файл, извлекать файлы из архива, просматривать оглавление архива и т.д. Разные программы отличаются форматом архивных файлов, скоростью работы, степенью сжатия файлов при помещении в архив, удобством использования.
В настоящее время применяется несколько десятков программ - архиваторов, которые отличаются перечнем функций и параметрами работы, однако лучшие из них имеют примерно одинаковые характеристики. Из числа наиболее популярных программ можно выделить:, PKPAK, LHA, ICE, HYPER, ZIP, РАК, ZOO, EXPAND, разработанные за рубежом, а также AIN и RAR, разработанные в России. Обычно упаковка и распаковка файлов выполняются одной и той же программой, но в некоторых случаях это осуществляется разными программами, например, программа РКZIР производит упаковку файлов, a PKUNZIP - распаковку файлов.
Программы-архиваторы позволяют создавать и такие архивы, для извлечения из которых содержащихся в них файлов не требуются какие - либо программы, так как сами архивные файлы могут содержать программу распаковки. Такие архивные файлы называются самораспаковывающимися.
Самораспаковывающийся архивный файл - это загрузочный, исполняемый модуль, который способен к самостоятельной разархивации находящихся в нем файлов без использования программы - архиватора.
Самораспаковывающийся архив получил название SFX - архив (SelF - eXtracting).
архиватор сжатие упаковщик потеря
Сжатие файлов при архивации
Все алгоритмы сжатия оперируют входным потоком информации с целью получения более компактного выходного потока при помощи некоторого преобразования. Основными техническими характеристиками процессов сжатия и результатов их работы являются:
·степень сжатия - отношение объемов исходного и результирующего потоков;
·скорость сжатия - время, затрачиваемое на сжатие некоторого объема информации входного потока, до получения из него эквивалентного выходного потока;
·качество сжатия - величина, показывающая, на сколько сильно упакован выходной поток при применении к нему повторного сжатия по тому же или другому алгоритму.
Алгоритмы, которые устраняют избыточность записи данных, называются алгоритмами сжатия данных, или алгоритмами архивации. В настоящее время существует огромное множество программ для сжатия данных, основанных на нескольких основных способах.
Все алгоритмы сжатия данных делятся на:
) алгоритмы сжатия без потерь, при использовании которых данные на приемной восстанавливаются без малейших изменений;
)алгоритмы сжатия с потерями, которые удаляют из потока данных информацию, незначительно влияющую на суть данных, либо вообще невоспринимаемую человеком.
Существует два основных метода архивации без потерь:
алгоритм Хаффмана (англ. Huffman), ориентированный на сжатие последовательностей байт, не связанных между собой,
алгоритм Лемпеля-Зива (англ. Lempel, Ziv), ориентированный на сжатие любых видов текстов, то есть использующий факт неоднократного повторения "слов" - последовательностей байт.
Практически все популярные программы архивации без потерь (ARJ, RAR, ZIP и т.п.) используют объединение этих двух методов - алгоритм LZH.
Алгоритм Хаффмана.
Алгоритм основан на том факте, что некоторые символы из стандартного 256-символьного набора в произвольном тексте могут встречаться чаще среднего периода повтора, а другие, соответственно, - реже. Следовательно, если $+o записи распространенных символов использовать короткие последовательности бит, длиной меньше 8, а для записи редких символов - длинные, то суммарный объем файла уменьшится.
Алгоритм Лемпеля-Зива. Классический алгоритм Лемпеля-Зива -LZ77, названный так по году своего опубликования, предельно прост. Он формулируется следующим образом: если в прошедшем ранее выходном потоке уже встречалась подобная последовательность байт, причем запись о ее длине и смещении от текущей позиции короче чем сама эта последовательность, то в выходной файл записывается ссылка (смещение, длина), а не сама последовательность.
Показатель степени сжатия файлов
Сжатие информации в архивных файлах производится за счет устранения избыточности различными способами, например за счет упрощения кодов, исключения из них постоянных битов или представления повторяющихся символов или повторяющейся последовательности символов в виде коэффициента повторения и соответствующих символов. Алгоритмы подобного сжатия информации реализованы в специальных программах-архиваторах (наиболее известные из которых arj/arjfolder, pkzip/pkunzip/winzip, rar/winrar) применяются определенные Сжиматься могут как один, так и несколько файлов, которые в сжатом виде помещаются в так называемый архивный файл или архив.
Целью упаковки файлов обычно являются обеспечение более компактного размещения информации на диске, сокращение времени и соответственно стоимости передачи информации по каналам связи в компьютерных сетях. Поэтому основным показателем эффективности той или иной программы-архиватора является степень сжатия файлов.
Степень сжатия файлов характеризуется коэффициентом Кс, определяемым как отношение объема сжатого файла Vc к объему исходного файла Vо, выраженное в процентах (в некоторых источниках используется обратное соотношение):
Кс=(Vc/Vo)*100%
Степень сжатия зависит от используемой программы, метода сжатия и типа исходного файла.
Наиболее хорошо сжимаются файлы графических образов, текстовые файлы и файлы данных, для которых коэффициент сжатия может достигать 5 - 40%, меньше сжимаются файлы исполняемых программ и загрузочных модулей Кс = 60 - 90%. Почти не сжимаются архивные файлы. Это нетрудно объяснить, если знать, что большинство программ-архиваторов используют для сжатия варианты алгоритма LZ77 (Лемпеля-Зива), суть которого заключается в особом кодировании повторяющихся последовательностей байт (читай - символов). Частота встречаемости таких повторов наиболее высока в текстах и точечной графике и практически сведена к нулю в архивах.
Кроме того, программы для архивации все же различаются реализациями алгоритмов сжатия, что соответственно влияет на степень сжатия.
В некоторые программы-архиваторы дополнительно включаются средства, направленные на уменьшение коэффициента сжатия Кс. Так в программе WinRAR реализован механизм непрерывного (solid) архивирования, при использовании которого может быть достигнута на 10 - 50% более высокая степень сжатия, чем дают обычные методы, особенно если упаковывается значительное количество небольших файлов однотипного содержания.
Характеристики архиваторов - обратно зависимые величины. То есть, чем больше скорость сжатия, тем меньше степень сжатия, и наоборот.
На компьютерном рынке предлагается множество архиваторов - у каждого свой набор поддерживаемых форматов, свои плюсы и минусы, свой круг почитателей, свято верящих в то, что используемый ими архиватор самый лучший. Не будем никого и ни в чем разубеждать - просто попытаемся беспристрастно оценить самые популярные архиваторы в плане функциональности и эффективности. К таковым отнесем WinZip, WinRAR, WinAce, 7-Zip - они лидируют по количеству скачиваний на софтовых серверах. Рассматривать остальные архиваторы вряд ли целесообразно, поскольку процент применяющих их пользователей (судя по числу скачиваний) невелик.
Сжатие информации без потерь. Часть первая / Хабр
Доброго времени суток.Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Третья группа методов – это так называемые методы преобразования блока. Входящие данные разбиваются на блоки, которые затем трансформируются целиком. При этом некоторые методы, особенно основанные на перестановке блоков, могут не приводить к существенному (или вообще какому-либо) уменьшению объема данных. Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики
Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F = {p(si)} неизменно, и вероятности элементов взаимно независимы, то средняя длина кодов может быть рассчитана как
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.
Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.
Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.
Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 <-> B1
a2 <-> B2
…
an <-> Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B'B''. Тогда B' называют началом, или префиксом слова B, а B'' — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Итак, мы разобрались с основными определениями. Так как же происходит само кодирование без памяти?
Оно происходит в три этапа.
- Составляется алфавит Ψ символов исходного сообщения, причем символы алфавита сортируются по убыванию их вероятности появления в сообщении.
- Каждому символу ai из алфавита Ψ ставится в соответствие некое слово Bi из префиксного множества Ω.
- Осуществляется кодирование каждого символа, с последующим объединением кодов в один поток данных, который будет являться результатам сжатия.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
В первую очередь при кодировании алгоритмом Хаффмана, нам нужно построить схему ∑. Делается это следующим образом:
- Все буквы входного алфавита упорядочиваются в порядке убывания вероятностей. Все слова из алфавита выходного потока (то есть то, чем мы будем кодировать) изначально считаются пустыми (напомню, что алфавит выходного потока состоит только из символов {0,1}).
- Два символа aj-1 и aj входного потока, имеющие наименьшие вероятности появления, объединяются в один «псевдосимвол» с вероятностью p равной сумме вероятностей входящих в него символов. Затем мы дописываем 0 в начало слова Bj-1, и 1 в начало слова Bj, которые будут впоследствии являться кодами символов aj-1 и aj соответственно.
- Удаляем эти символы из алфавита исходного сообщения, но добавляем в этот алфавит сформированный псевдосимвол (естественно, он должен быть вставлен в алфавит на нужное место, с учетом его вероятности).
Шаги 2 и 3 повторяются до тех пор, пока в алфавите не останется только 1 псевдосимвол, содержащий все изначальные символы алфавита. При этом, поскольку на каждом шаге и для каждого символа происходит изменение соответствующего ему слова Bi (путем добавление единицы или нуля), то после завершения этой процедуры каждому изначальному символу алфавита ai будет соответствовать некий код Bi.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — { a1, a2, a3, a4}. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:
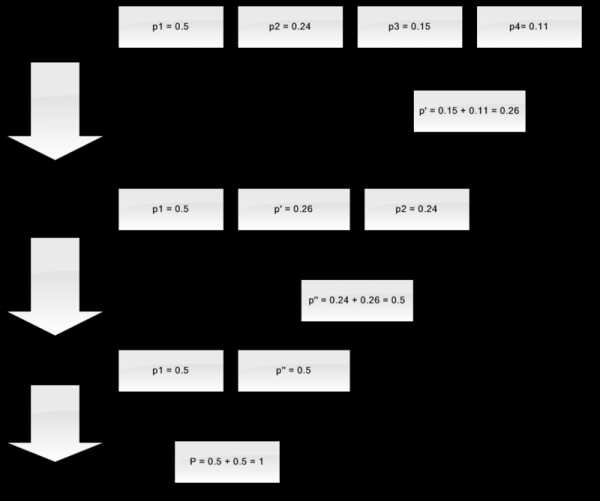
Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
a1 = 0
a2 = 11
a3 = 100
a4 = 101
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Литература
- Ватолин Д., Ратушняк А., Смирнов М. Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео; ISBN 5-86404-170-X; 2003 г.
- Д. Сэломон. Сжатие данных, изображения и звука; ISBN 5-94836-027-Х; 2004г.
- www.wikipedia.org
Тестирование алгоритмов сжатия некоторых архиваторов (дополнено)
Введение
Архиваторами мы пользуемся постоянно. На нашем сайте имеется подробное (пусть и давно написанное) описание наиболее популярных программ-архиваторов (Архиваторы: Взгляд со стороны), которое мы здесь повторять не будем, а займемся только алгоритмами сжатия, которые применяются в этих программах. В чем здесь проблема? Современные архиваторы предоставляют нам возможность на выбор использовать несколько алгоритмов сжатия. Вот, например, характеристики некоторых программ...
Форматы, поддерживаемые архиваторами
| Архиватор | Упаковка и распаковка | Только распаковка |
|---|---|---|
| WinZip | ZIP | TAR, GZIP, BH, ARJ, LZH, ARC |
| WinRar | RAR, ZIP | CAB, ARJ, LZH,TAR, GZ, ACE, UUE, BZ2, JAR, JSO |
| WinAce | ACE, ZIP, LHA, MSCAB | RAR, ARC, ATJ, GZIP, TAR ZOO |
| 7-Zip | 7Z, ZIP, GZIP, TAR, BZIP2 | RAR, CAB, ARJ, CPIO, RPM, DEB, SPLIT |
| Power Archiver | TAR, BH, CAB, LHA, ZIP | RAR, ACE, ARJ, GZIP, BZIP2, ARC, ZOO |
В зависимости от обстоятельств, мы применяем архиватор как компрессор, от которого требуется сжать информацию для более быстрой передачи по каналам связи (почта и Интернет). В других случаях большее значение имеет функция собственно архивации, то есть преобразование информации в компактный вид (один файл), чтобы избавиться от разукомплектации и, кроме того, сократить место, занимаемое на диске за счет файловой таблицы. Соответственно, большой интерес представляет показатель сжатия исходной информации и показатель скорости переработки исходной информации. Целью нашего исследования является определение абсолютных и относительных показателей степени сжатия и быстродействия алгоритмов (форматов), которые предоставляются в наше распоряжение архиваторами, указанными в таблице...
Содержание исследования планируется в следующем виде:
1. Создание комплексного и частных (по типам файлов) наборов информации (папок) для проведения испытаний (тестов).
2. Проведение предварительных тестов на комплексном наборе и уточнение (по результатам) плана дальнейших локальных испытаний.
3. Обработка и анализ результатов с обоснованием рекомендаций по практическому применению разных алгоритмов (форматов) архивации.
В качестве показателя степени сжатия принимается процентное отношение размера сжатой папки к ее исходному размеру, а в качестве показателя быстродействия - скорость переработки как частное от деления исходного размера в килобайтах на время переработки в секундах. Собственно, измерения выполняются только в отношении времени (секундомером). Ошибка измерения времени может исказить показатель быстродействия, когда этот показатель очень большой (более 1000 кб/сек). В других случаях ошибкой можно пренебречь.
Определение общих характеристик основных архивных форматов
Для испытаний использовался материал, имитирующий некоторую "пользовательскую корзину", составленную из файлов формата DOC, HTM, JPG, MP3, PDF, TXT. Всего корзина содержит 359 папок и 3337 файлов, и имеет суммарный размер 208893 Кбайт (около 204 Мбайт). Состав этого набора приведен в следующей таблице:
Состав набора файлов для испытаний
| Тип | Количество папок | Количество файлов | Размер, Кбайт | На диске, Кбайт |
|---|---|---|---|---|
| TXT | 0 | 2 | 34781 | 34783 |
| HTM | 329 | 2869 | 30913 | 36962 |
| DOC | 3 | 24 | 31443 | 31474 |
| 0 | 1 | 33691 | 33694 | |
| JPG | 26 | 430 | 40493 | 41382 |
| MP3 | 1 | 11 | 37571 | 37589 |
| | ||||
| Итого | 359 | 3337 | 208893 | 215884 |
Каждое испытание заключалось в проведении цикла архивации с фиксацией времени работы архиватора от момента нажатия кнопки Add до момента открытия окна с содержанием полученного архивного файла.
Тестировавшиеся программы:
WinZip 8.1 SR-1
WinRar 3.30
WinAce 2.5
7Zip 3.13
Power Archiver 8.70 07b
Информация о конфигурации системы
Процессор Intel Celeron 1700MHz
256 Mb (DDR SDRAM)
HDD ST360015A (60 Gb, 7200PRM)
Windows 2000 Pro, SP3
Результаты испытаний приведены в следующих таблицах:
Результаты тестирования для формата ZIP
| Архиватор / Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| | ||||
| WinZip | | |||
| Без сжатия | 208893 | - | - | - |
| Норма | 146408 | 2-00 | 70.0% | 1740 |
| Максимум | 145884 | 2-45 | 69.8% | 1266 |
| Быстро | 147690 | 1-58 | 70.7% | 1770 |
| Очень быстро | 149450 | 1-50 | 71.5% | 1899 |
| | ||||
| WinRar | | |||
| Обычно | 146 078 | 2-22 | 69.9% | 1471 |
| Максимум | 145881 | 3-07 | 69.8% | 1117 |
| | ||||
| WinAce | | |||
| Норма | 146 418 | 2-28 | 70.1% | 1411 |
| Максимум | 145844 | 2-40 | 69.8% | 1305 |
| | ||||
| 7-Zip | | |||
| Норма/Deflate | 145 480 | 3-22 | 69.6% | 1034 |
| Ультра/Deflate | 145 341 | 5-55 | 69.6% | 588 |
| Ультра/Deflate64 | 144924 | 6-10 | 69.4% | 565 |
| | ||||
| Power Archiver | | |||
| Норма | 146074 | 3-40 | 69.9% | 950 |
| Максимум | 145948 | 3-42 | 69.9% | 941 |
В целом, сжатие, получаемое форматом ZIP, примерно одного порядка, и мало зависит от архиватора - за исключением архиватора 7-ZIP, в котором с помощью изменения метода сжатия можно несколько улучшить показатель и для формата ZIP. Размер словарей (архиваторы WinRar и 7-ZIP) специально в данной серии испытаний не изменялся, а устанавливался автоматически (по умолчанию).
Результаты тестирования формата RAR
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| Store | 209129 | 0-58 | 100.1% | 3601 |
| Fastest | 144017 | 6-00 | 68.9% | 580 |
| Fast | 143281 | 6-22 | 68.6% | 547 |
| Normal | 142830 | 6-40 | 68.4% | 522 |
| Good | 139826 | 6-58 | 66.9% | 499 |
| Best | 140023 | 7-25 | 67.0% | 469 |
| Best (64kb) | 140685 | 5-40 | 67.3% | 614 |
В настройке режима возможно изменение размера словаря в пределах 64 - 4096 килобайт. По умолчанию устанавливается максимальный размер (4096 Кб), с которым и получены результаты в данной таблице. Только в строке Best (64kb) был установлен минимальный размер - 64 килобайта. Очевидно, что полученное изменение сжатия и быстродействия может служить аналогом для всех других строк этой таблицы.
Строки Good и Best проверялись, и их значения полностью подтвердились, поэтому нелогичный переход между ними нельзя считать следствием ошибок при тестировании.
Результаты тестирования формата ACE
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| Normal | 132978 | 8-30 | 63.7% | 410 |
| Maximum | 132918 | 8-42 | 63.6% | 400 |
| Good | 132925 | 9-50 | 63.6% | 354 |
| Fast | 133216 | 8-53 | 63.8% | 397 |
| Super Fast | 133273 | 8-46 | 63.8% | 397 |
| Store | 209136 | 1-48 | 100.1% | 1934 |
Изменения режима работы архиватора WinAce в нашем случае мало влияют на показатели сжатия - разброс находится в пределах десятых долей процента.
Результаты тестирования формата 7z
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| Нормальный | 130964 | 9-24 | 64.2% | 362 |
| Максимальный | 130000 | 13-51 | 63.7% | 246 |
| Быстрый | 141922 | 4-16 | 69.6% | 797 |
| Ультра (1 Мб) | 131392 | 8-47 | 64.4% | 387 |
| Ультра (6 Мб) | 130101 | 11-40 | 63.8% | 291 |
| Ультра (12 мб) | 129871 | 12-47 | 63.7% | 266 |
| Ультра (24 мб) | - | - | - | - |
| Ультра (Deflate) | 141171 | 3-15 | 69.2% | 1046 |
| Ультра (PPMd) | 140171 | 8-45 | 68.7% | 389 |
| Ультра (Bzip2) | 135342 | 7-32 | 66.4% | 451 |
Примечание: в режиме Ультра (LZMA) при задании размера Словаря в 24 мегабайт скорость снизилась настолько, что проведение теста стало невозможным.
Для формата 7z архиватор позволяет устанавливать:
- Уровень (Быстрый, Нормальный, Максимальный, Ультра),
- Метод (LZMA, PPMd, Bzip2, Deflate),
- Размер словаря (32кб - 192 мб),
- Размер слова (8 - 255).
Как видим, возможно очень большое число комбинаций настройки режима работы архиватора, что может сбить пользователя с толку. Можно руководствоваться следующими посылками:
- Чем больше размер словаря, тем больше сжатие и время упаковки. Сжатие возрастает медленно, а время упаковки - вырастает очень сильно.
- То же самое - в отношении размера слова.
- Оптимальные настройки устанавливаются сами (настройки по умолчанию), и без надобности их можно не сбивать.
Результаты тестирования формата CAB
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| | ||||
| PowerArchiver | | |||
| Medium | 140444 | 9-55 | 67.2% | 351 |
| Maximum | 137152 | 15-55 | 65.6% | 219 |
| | ||||
| WinAce | | |||
| Норма | 144374 | 3-24 | 69.1% | 1024 |
| Максимум | 138538 | 12-54 | 66.3% | 270 |
Формат CAB (cabinet file) основан на алгоритмах MS-Zip и LZX, поддерживается и применяется фирмой Microsoft. Распаковщики формата имеются в Windows 98 и выше. Алгоритм имеет открытый код и может свободно применяться всеми программистами.
Результаты тестирования форматов BH и LHA
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| | ||||
| PowerArchiver, формат LHA | | |||
| Norma | 147518 | 4-40 | 70.6% | 746 |
| Maximum | 147518 | 4-47 | 70.6% | 728 |
| | ||||
| PowerArchiver, формат BH | | |||
| Norma | 145912 | 2-16 | 69.8% | 1536 |
| Maximum | 145718 | 2-34 | 69.8% | 1356 |
Показатели архивных форматов LHA и BH имеют уровень показателей архивного формата ZIP, и каких-то преимуществ не просматривается.
В общем, как видно, наилучшие показатели сжатия обеспечиваются форматами ACE и 7Z. Лучшие показатели быстродействия - показали форматы ZIP и BH. Дальнейшие испытания планируется провести по такой же принципиальной схеме, но с "корзинами" однородного состава, с форматами файлов: TXT, HTML, DOC, JPG, MP3, PDF.
Определение сжимаемости файлов разных форматов
Для обеспечения этой серии испытаний были составлены совершенно однородные по форматам файлов наборы, причем, повторяющиеся файлы в наборе исключались. Файлы EXE и DLL брались из системной папки Windows без всякого отбора. Дело в том, что файлы формата EXE бывают уже сжатыми и дальнейшее их сжатие - не имеет смысла. Характеристики наборов приводятся в следующей таблице:
Форматы файлов в наборах для испытаний
| Формат | Кол-во папок | Кол-во файлов | Суммарный размер, Кбайт |
|---|---|---|---|
| TXT | 0 | 27 | 35096 |
| HTM | 7 | 1371 | 25076 |
| DOC | 1 | 33 | 37211 |
| 0 | 1 | 33691 | |
| JPG | 26 | 430 | 40493 |
| MP3 | 2 | 11 | 37571 |
| EXE | 0 | 316 | 32446 |
| DLL | 0 | 184 | 40323 |
| XLS | 6 | 15 | 17228 |
| CHM | 0 | 69 | 33940 |
| MPEG | 0 | 24 | 46606 |
| WAV | 0 | 1 | 30804 |
| BMP | 0 | 15 | 31713 |
| AVI | 0 | 89 | 9261 |
При испытаниях использовался только нормальный (обычный) режим работы архиватора. При этом, каждый формат архива создавался собственным архиватором (WinZip, WinRar, WinAce, 7-Zip), для упаковки в формат CAB использовался Power Archiver, который своего (фирменного) формата не имеет.
Сжимаемость файлов в зависимости от формата архива
| Формат | ZIP | RAR | ACE | 7Z | CAB |
|---|---|---|---|---|---|
| TXT | 43.7% | 37.8% | 37.4% | 34.3% | 36.3% |
| HTM | 29.2% | 28.3% | 9.09% | 7.75% | 15.0% |
| DOC | 8.76% | 6.39% | 5.47% | 5.21% | 6.49% |
| 97.7% | 97.4% | 97.8% | 97.5% | 97.3% | |
| JPG | 98.5% | 98.5% | 85.0% | 85.1% | 97.9% |
| MP3 | 98.1% | 97.9% | 98.1% | 97.9% | 97.7% |
| EXE | 46.9% | 42.1% | 37.8% | 32.7% | 39.3% |
| DLL | 45.6% | 39.6% | 37.6% | 34.3% | 39.6% |
| XLS | 11.8% | 8.27% | 7.44% | 5.97% | 8.49% |
| CHM | 98.6% | 98.8% | 99.0% | 99.6% | 98.6% |
| MPEG | 95.3% | 94.7% | 94.8% | 94.5% | 94.4% |
| AVI | 86.1% | 84.1% | 84.5% | 82.7% | 83.4% |
| WAV | 92.2% | 62.8% | 62.6% | 87.0% | 92.1% |
| BMP | 63.5% | 31.9% | 30.6% | 51.5% | 56.2% |
| | |||||
| Средний показатель | 65.5% | 59.2% | 56.2% | 58.3% | 61.6% |
В качестве комментария к таблице можно отметить следующее:
- Наилучшее сжатие по основным форматам исходных файлов обеспечивается архивным форматом 7z.
- Лучший показатель в среднем имеет архивный формат ACE за счет рекордного сжатия форматов WAV и BMP.
Если говорить о сжимаемости исходных файлов, то можно отметить следующее: показатель сжатия зависит от исходного формата файлов, иногда подразумевающего внутреннее сжатие данных. Если файл предварительно уплотнен по своим алгоритмам, то сжимаемость его архиватором - небольшая. Например, файл формата CHM является уплотненным вариантом файла формата HTML и, соответственно, сжимаемость их - разная. То же мы видим в отношении Wav и MP3, BMP и JPG и так далее.
Скорость работы архиватора, Кбайт/с
| Формат | ZIP | RAR | ACE | 7Z | CAB |
|---|---|---|---|---|---|
| TXT | 2064 | 408 | 386 | 217 | 226 |
| HTM | 2507 | 836 | 627 | 643 | 411 |
| DOC | 7400 | 2862 | 1550 | 1378 | 886 |
| 2246 | 293 | 370 | 387 | 370 | |
| JPG | 2670 | 587 | 337 | 368 | 287 |
| MP3 | 2348 | 458 | 368 | 335 | 332 |
| EXE | 2318 | 773 | 601 | 416 | 433 |
| DLL | 2016 | 858 | 672 | 474 | 434 |
| XLS | 4300 | 1436 | 1148 | 507 | 224 |
| CHM | 1886 | 556 | 365 | 357 | 323 |
| MPEG | 2453 | 583 | 416 | 370 | 338 |
| AVI | 1852 | 617 | 463 | 370 | 356 |
| WAV | 2370 | 1711 | 1184 | 354 | 288 |
| BMP | 2883 | 1269 | 933 | 401 | 373 |
| | |||||
| Средний показатель | 2838 | 856 | 609 | 485 | 385 |
Эта таблица демонстрирует очевидное правило - за лучшее сжатие почти всегда необходимо платить скоростью упаковки.
Сжимаемость разных форматов файлов. Дополнение
| Формат | ZIP | RAR | ACE | 7Z |
|---|---|---|---|---|
| VXD | 55.1% | 52.5% | 43.3% | 40.8% |
| INF | 14.9% | 13.3% | 13.2% | 12.3% |
| VBP | 78.3% | 72.6% | 26.0% | 18.5% |
| GIF | 90.0% | 94.3% | 87.2% | 86.1% |
| SCR | 88.8% | 88.0% | 88.1% | 87.9% |
| DAT | 23.1% | 20.1% | 20.5% | 18.0% |
| INI | 35.6% | 33.2% | 32.5% | 30.2% |
| | ||||
| Средний показатель | 55.1% | 53.4% | 44.4% | 42.0% |
Эта таблица содержит дополнительные данные по сжимаемости файловых форматов. Здесь тестирование проводилось без фиксации времени на наборах небольшого объема (100-200 кб). Как видно, по всем форматам наилучшее сжатие дает архивный формат 7z.
Далее, в качестве примера приведу результаты упаковки реального дистрибутива программы Norton Antivirus. Упаковка выполнялась в нормальном режиме, дополнительно получены самораспаковывающиеся варианты этих же архивов. Результат этого испытания приведен в следующей таблице (последняя колонка - примерное время загрузки упакованного дистрибутива по сети при обычном модемном соединении при скорости 2.7 Кбайт в секунду):
Пример упаковки дистрибутива Norton Antivirus
| Формат архива | Размер, Кбайт | Время | Сжатие | Время загрузки, час.-мин. |
|---|---|---|---|---|
| Без сжатия | 47410 | - | - | 4-53 |
| ZIP | 29045 | 0-21 | 61.3% | 2-59 |
| RAR | 26619 | 1-15 | 56.1% | 2-44 |
| ACE | 23838 | 1-30 | 50.3% | 2-27 |
| 7Z | 22871 | 1-50 | 48.2% | 2-21 |
| CAB | 26804 | 2-22 | 56.5% | 2-45 |
| EXE (RAR) | 26671 | 1-15 | 56.3% | 2-45 |
| EXE (ACE) | 23903 | 1-30 | 50.4% | 2-28 |
| EXE (7Z) | 22941 | 1-52 | 48.4% | 2-22 |
Результаты таблицы наглядно демонстрируют, что:
При передачи файлов по сети - упаковка практически обязательна.
Упаковка с хорошим сжатием может сократить время передачи файла, в нашем случае - на полчаса.
Применение перспективных форматов ACE и 7Z вполне оправдано уже сейчас в виде самораспаковывающихся архивов. Это обстоятельство желательно учитывать распространителям программной продукции по сети Интернет.
Архиватор 7-ZIP является хорошей программой с высокой степенью сжатия и обладает необходимым минимумом пользовательских удобств. Можно, в частности, удалять и просматривать отдельные файлы без общей распаковки архива. При этом, файлы открываются ассоциативными приложениями системы. Можно дополнять архив отдельными файлами.
Заключение
Программы-архиваторы остаются незаменимым средством упаковки и сжатия цифровой информации. Обработанная информация существенно экономит место на хранителях и время передачи по каналам связи в сети. Наиболее популярными и применяемыми являются сейчас форматы упаковки ZIP и RAR. Другие форматы, например, ARJ, ICE, PAC, ARC и некоторые еще - постепенно вытеснились и подзабылись. Но технология упаковки не стоит на месте. Архиваторы - востребованы, поэтому программисты непрерывно ведут поиск более эффективных методов сжатия. Об этом свидетельствуют и результаты нашего эксперимента. Реально существуют, по крайней мере, два архивных формата (ACE и 7z), которые по сжатию существенно превосходят привычные ZIP и RAR. Применение этих форматов позволит заметно сократить время передачи файлов по сети Интернет, что соответствует интересам многочисленных пользователей...
Дополнение от 24 мая 2004 г.
В этом разделе мы рассмотрим влияние опции Solid на показатели работы архиваторов. Напомним, что упаковка с опцией Solid приводит к тому, что в архив нельзя добавить файл и нельзя из него извлечь отдельный файл, архив упаковывается и распаковывается только целиком. В общем случае это может вызывать определенные неудобства при использовании таких архивов. Но иногда такие неудобства могут иметь второстепенное значение в сравнении с преимуществами.
Дополнительное тестирование проделано в точности так, как это описано в основном разделе на тех же самых наборах материала. С учетом дополнительного тестирования таблица "Результаты тестирования формата RAR" основного текста стала выглядеть так...
Результаты тестирования формата RAR
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| Store | 209129 | 0-58 | 100.1% | 3601 |
| Fastest | 144017 | 6-00 | 68.9% | 580 |
| Fast | 143281 | 6-22 | 68.6% | 547 |
| Normal | 142830 | 6-40 | 68.4% | 522 |
| Normal (Solid) | 131664 | 9-14 | 63.0% | 377 |
| Good | 139826 | 6-58 | 66.9% | 499 |
| Good (Solid) | 129314 | 8-24 | 61.9% | 414 |
| Best | 140023 | 7-25 | 67.0% | 469 |
| Best (Solid) | 129527 | 8-36 | 62.0% | 405 |
| Best (64kb) | 140685 | 5-40 | 67.3% | 614 |
Настройка архиватора WinRar включает в себя:
1. Выбор способа сжатия (Normal, Store, Fastest, Fast, Good, Best).
2. Выбор модификации:
- Add and replace files,
- Add and update files,
- Fresh existing files only,
- Syncronize axchive contents.
3. Выбор опции:
- Deleting files after archiving,
- Create SFX archive,
- Create solid archive,
- Put autohenlicity verification,
- Put recovery record,
- Test archived files,
- Lock archive.
Нетрудно заметить, что возможно более сотни комбинаций настроек, определяющих режим работы архиватора. Соответственно и диапазон результатов для этого формата и этого архиватора получился достаточно большим - степень сжатия: 61.9 - 68.9%, скорость: 377 - 614 Кбайт/сек.
Опцию Solid имеет также архиватор WinAce. Но в этом архиваторе опция (Make solid archive) включена постоянно (по умолчанию) и поэтому вошла в результаты тестирования. Таким образом, несправедливость была допущена только для формата RAR и архиватора WinRar.
С учетом новых обстоятельств таблица лидеров по степени сжатия выглядит так:
1. RAR (Good, Solid) - 61.9%.
2. 7-Zip (Максимум) - 62.2%.
3. ACE (Good) - 63.6%.
Дополненная таблица результатов упаковки реального дистрибутива программы Norton Antivirus ("Пример упаковки дистрибутива Norton Antivirus") стала выглядеть так...
Пример упаковки дистрибутива Norton Antivirus
| Формат архива | Размер, Кбайт | Время | Сжатие | Время загрузки, час.-мин. |
|---|---|---|---|---|
| Без сжатия | 47410 | - | - | 4-53 |
| ZIP | 29045 | 0-21 | 61.3% | 2-59 |
| RAR | 26619 | 1-15 | 56.1% | 2-44 |
| RAR (Normal, Solid) | 22745 | 1-21 | 48.0% | 2-20 |
| RAR (Good, Solid) | 22680 | 1-28 | 47.8% | 2-20 |
| ACE | 23838 | 1-30 | 50.3% | 2-27 |
| 7Z | 22871 | 1-50 | 48.2% | 2-21 |
| CAB | 26804 | 2-22 | 56.5% | 2-45 |
| EXE (RAR) | 26671 | 1-15 | 56.3% | 2-45 |
| EXE (RAR, Normal, Solid) | 22797 | 1-29 | 48.1% | 2-21 |
| EXE (ACE) | 23903 | 1-30 | 50.4% | 2-28 |
| EXE (7Z) | 22941 | 1-52 | 48.4% | 2-22 |
Результаты этой таблицы также подтверждают, что архиватор WinRar может обеспечить максимальное сжатие, и по этому показателю является лидером. В сравнении с форматом ZIP загрузка этого же дистрибутива в формате RAR может осуществлена на 39 минут короче...
В таблице с результатами тестирования формата 7z наш читатель Александр Рыхлов обнаружил ошибку в расчете показателя сжатия. Александру большое спасибо, а исправленная таблица "Результаты тестирования формата 7z" стала выглядеть так...
Результаты тестирования формата 7z
| Режим | Размер, Кбайт | Время, мин.-сек. | Сжатие | Скорость, Кбайт/с |
|---|---|---|---|---|
| Без сжатия | 208893 | - | - | - |
| Нормальный | 130964 | 9-24 | 62.7% | 362 |
| Максимальный | 130000 | 13-51 | 62.2% | 246 |
| Быстрый | 141922 | 4-16 | 67.9% | 797 |
| Ультра (1 Мб) | 131392 | 8-47 | 62.9% | 387 |
| Ультра (6 Мб) | 130101 | 11-40 | 62.3% | 291 |
| Ультра (12 мб) | 129871 | 12-47 | 62.2% | 266 |
| Ультра (24 мб) | - | - | - | - |
| Ультра (Deflate) | 141171 | 3-15 | 67.6% | 1046 |
| Ультра (PPMd) | 140171 | 8-45 | 67.1% | 389 |
| Ультра (Bzip2) | 135342 | 7-32 | 64.8% | 451 |
Примечание: в режиме Ультра (LZMA) при задании размера Словаря в 24 мегабайт скорость снизилась настолько, что проведение теста стало невозможным.
Заключение
Назревавшая было сенсация о том, что архиватор WinRar не настолько хорош, как это считают многие пользователи, не состоялась. Наше тестирование подтвердило, что технические характеристики этого архиватора действительно на сегодняшний день самые высокие. Очень близкие показатели имеет архиватор 7-Zip, но по степени отработки и ползовательским качествам последний пока несколько уступает лидеру. Для получения максимального сжатия в архиваторе WinRar необходимо включать опцию Solid (по умолчанию она отключена), другие настройки (Normal, Good и т.д.) - имеют меньшее значение.
c # - Как определить эффективность сжатия с использованием кодирования Хаффмана?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд
- влияет ли порядок данных в текстовом файле на степень его сжатия?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
новейших вопросов о сжатии - Stack overflow на русском
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
иначе
returnType = 'bytes';
.Введение в инструменты сжатия файлов на серверах Linux
× Содержание
× Поделиться этим учебником
Куда бы вы хотели этим поделиться?
- Хакерские новости
Поделиться ссылкой
Ссылка на руководство× Поделиться этим учебником
Куда бы вы хотели этим поделиться?
Вычислить прогресс сжатия в SharpZipLib c # и время сжатия
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами