Как указать путь к файлу python
Python путь к файлу и расширение — Получение имени из полного пути
Достаточно часто возникают ситуации, когда у нас есть полное имя файла, а требуется узнать его расширение. Или добавить нужное расширение, когда не известно, ввел его пользователь или нет. Иногда у нас есть относительный путь до файла, а требуется узнать абсолютный. Про основные методы работы с именем файла и будет эта статья.
Абсолютный путь к файлу
Для того чтобы узнать в Python абсолютный путь к файлу, потребуется воспользоваться библиотекой os. Её подключаем с помощью команды import os. В классе path есть метод abspath. Вот пример использования.
import os
p = os.path.abspath('file.txt ')
print(p)
C:\python3\file.txt Так же можно воспользоваться и стандартной библиотекой pathlib. Она вошла в состав основных библиотек, начиная с версии Python 3.4. До этого надо было ее инсталлировать с помощью команды pip install pathlib. Она предназначена для работы с путями файловой системы в разных ОС и отлично подойдет для решения данной задачи.
import pathlib
p = pathlib.Path('file.txt ')
print(p)
C:\python3\file.txt Имя файла
Чтобы узнать имя файла из полной строки с путем, воспользуемся методом basename модуля os.
import os name = os.path.basename(r'C:\python3\file.txt ') print(name) file.txt
Здесь перед строкой вставил r, чтобы подавить возможное возникновение служебных символов. Например, в данном случае если не указать r, то \f считалось бы символом перевода страницы.
Без расширения
Теперь разберемся, как в Python узнать имя файла без расширения. Воспользуемся методом splittext. В этот раз для примера возьмем файл с двойным расширением, чтобы проверить, как будут в этой ситуации работать стандартны функции.
from os import path full_name = path.basename(r'C:\python3\file.tar.gz ') name = path.splitext(full_name)[0] print(name) file.tar
Видно, что последнее расширение архиватора gz было отброшено, в то время как расширение несжатого архива tar осталось в имени.
Если же нам нужно только имя, то можно отбросить все символы полученной строки, которые идут после первой точки. Символ точки тоже отбросим.
Дополним предыдущий пример следующим кодом:
index = name.index('.')
print(name[:index])
file Расширение файла
В Python получить расширение файла можно аналогичным образом с помощью той же функции splitext. Она возвращает кортеж. Первый элемент кортежа имя, а второй – расширение. В данном случае нам нужен второй элемент. Индекс второго элемента равен единице, так как отсчет их идет от нуля.
from os import path full_name = path.basename(r'C:\python3\file.tar.gz ') name = path.splitext(full_name)[1] print(name) .gz
Аналогично можно воспользоваться библиотекой pathlib. Воспользуемся методом suffix.
from pathlib import Path print(Path(r'C:\python3\file.tar.gz ').suffix) .gz
Но в нашем случае два расширения. Их можно узнать с помощью функции suffixes. Она возвращает список, элементами которого и будут расширения. Ниже приведен пример получения списка расширений.
from pathlib import Path print(Path(r'C:\python3\file.tar.gz ').suffixes) ['.tar', '.gz ']
Для того, чтобы получить имя файла или расширение из полного пути или для получения абсолютного пути к файлу используйте библиотеки os и pathlib. Лучше воспользоваться готовым решением из стандартой библиотеками, чем писать свое решение.
Работа с файлами в Python
В данном материале мы рассмотрим, как читать и вписывать данные в файлы на вашем жестком диске. В течение всего обучения, вы поймете, что выполнять данные задачи в Python – это очень просто. Начнем же.
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
This is test file line 2 line 3 this line intentionally left lank
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
handle = open("test.txt") handle = open(r"C:\Users\mike\py101book\data\test.txt", "r")
handle = open("test.txt") handle = open(r"C:\Users\mike\py101book\data\test.txt", "r") |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов. Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt. Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
>>> print("C:\Users\mike\py101book\data\test.txt") C:\Users\mike\py101book\data est.txt >>> print(r"C:\Users\mike\py101book\data\test.txt") C:\Users\mike\py101book\data\test.txt
>>> print("C:\Users\mike\py101book\data\test.txt") C:\Users\mike\py101book\data est.txt
>>> print(r"C:\Users\mike\py101book\data\test.txt") C:\Users\mike\py101book\data\test.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь. Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
handle = open("test.txt", "r") data = handle.read() print(data) handle.close()
handle = open("test.txt", "r") data = handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям. Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов.
handle = open("test.txt", "r") data = handle.readline() # read just one line print(data) handle.close()
handle = open("test.txt", "r") data = handle.readline() # read just one line print(data) handle.close() |
Если вы используете данный пример, будет прочтена и распечатана только первая строка текстового файла. Это не очень полезно, так что воспользуемся методом readlines() в дескрипторе:
handle = open("test.txt", "r") data = handle.readlines() # read ALL the lines! print(data) handle.close()
handle = open("test.txt", "r") data = handle.readlines() # read ALL the lines! print(data) handle.close() |
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Как читать файл по частям
Самый простой способ для выполнения этой задачи – использовать цикл. Сначала мы научимся читать файл строку за строкой, после этого мы будем читать по килобайту за раз. В нашем первом примере мы применим цикл:
handle = open("test.txt", "r") for line in handle: print(line) handle.close()
handle = open("test.txt", "r")
for line in handle: print(line)
handle.close() |
Таким образом мы открываем файл в дескрипторе в режиме «только чтение», после чего используем цикл для его повторения. Стоит обратить внимание на то, что цикл можно применять к любым объектам Python (строки, списки, запятые, ключи в словаре, и другие). Весьма просто, не так ли? Попробуем прочесть файл по частям:
handle = open("test.txt", "r") while True: data = handle.read(1024) print(data) if not data: break
handle = open("test.txt", "r")
while True: data = handle.read(1024) print(data)
if not data: break |
В данном примере мы использовали Python в цикле, пока читали файл по килобайту за раз. Как известно, килобайт содержит в себе 1024 байта или символов. Теперь давайте представим, что мы хотим прочесть двоичный файл, такой как PDF.
Как читать бинарные (двоичные) файлы
Это очень просто. Все что вам нужно, это изменить способ доступа к файлу:
handle = open("test.pdf", "rb")
handle = open("test.pdf", "rb") |
Мы изменили способ доступа к файлу на rb, что значит read-binaryy. Стоит отметить то, что вам может понадобиться читать бинарные файлы, когда вы качаете PDF файлы из интернете, или обмениваетесь ими между компьютерами.
Пишем в файлах в Python
Как вы могли догадаться, следуя логике написанного выше, режимы написания файлов в Python это “w” и “wb” для write-mode и write-binary-mode соответственно. Теперь давайте взглянем на простой пример того, как они применяются.
ВНИМАНИЕ: использование режимов “w” или “wb” в уже существующем файле изменит его без предупреждения. Вы можете посмотреть, существует ли файл, открыв его при помощи модуля ОС Python.
handle = open("output.txt", "w") handle.write("This is a test!") handle.close()
handle = open("output.txt", "w") handle.write("This is a test!") handle.close() |
Вот так вот просто. Все, что мы здесь сделали – это изменили режим файла на “w” и указали метод написания в файловом дескрипторе, чтобы написать какой-либо текст в теле файла. Файловый дескриптор также имеет метод writelines (написание строк), который будет принимать список строк, который дескриптор, в свою очередь, будет записывать по порядку на диск.
Выбирайте дешевые лайки на видео в YouTube на сервисе https://doctorsmm.com/. Здесь, при заказе, Вам будет предоставлена возможность подобрать не только недорогую цену, но и выгодные персональные условия приобретения. Торопитесь, пока на сайте действуют оптовые скидки!
Использование оператора «with»
В Python имеется аккуратно встроенный инструмент, применяя который вы можете заметно упростить чтение и редактирование файлов. Оператор with создает диспетчер контекста в Пайтоне, который автоматически закрывает файл для вас, по окончанию работы в нем. Посмотрим, как это работает:
with open("test.txt") as file_handler: for line in file_handler: print(line)
with open("test.txt") as file_handler: for line in file_handler: print(line) |
Синтаксис для оператора with, на первый взгляд, кажется слегка необычным, однако это вопрос недолгой практики. Фактически, все, что мы делаем в данном примере, это:
handle = open("test.txt")
handle = open("test.txt") |
Меняем на это:
with open("test.txt") as file_handler:
with open("test.txt") as file_handler: |
Вы можете выполнять все стандартные операции ввода\вывода, в привычном порядке, пока находитесь в пределах блока кода. После того, как вы покинете блок кода, файловый дескриптор закроет его, и его уже нельзя будет использовать. И да, вы все прочли правильно. Вам не нужно лично закрывать дескриптор файла, так как оператор делает это автоматически. Попробуйте внести изменения в примеры, указанные выше, используя оператор with.
Выявление ошибок
Иногда, в ходе работы, ошибки случаются. Файл может быть закрыт, потому что какой-то другой процесс пользуется им в данный момент или из-за наличия той или иной ошибки разрешения. Когда это происходит, может появиться IOError. В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
try: file_handler = open("test.txt") for line in file_handler: print(line) except IOError: print("An IOError has occurred!") finally: file_handler.close()
try: file_handler = open("test.txt") for line in file_handler: print(line) except IOError: print("An IOError has occurred!") finally: file_handler.close() |
В описанном выше примере, мы помещаем обычный код в конструкции try/except. Если ошибка возникнет, следует открыть сообщение на экране. Обратите внимание на то, что следует удостовериться в том, что файл закрыт при помощи оператора finally. Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
try: with open("test.txt") as file_handler: for line in file_handler: print(line) except IOError: print("An IOError has occurred!")
try: with open("test.txt") as file_handler: for line in file_handler: print(line) except IOError: print("An IOError has occurred!") |
Как вы можете догадаться, мы только что переместили блок with туда же, где и в предыдущем примере. Разница в том, что оператор finally не требуется, так как контекстный диспетчер выполняет его функцию для нас.
Подведем итоги
С данного момента вы уже должны легко работать с файлами в Python. Теперь вы знаете, как читать и вносить записи в файлы двумя способами. Теперь вы сможете с легкостью ориентироваться в данном вопросе.
Работа с файлами в Python.
Чтение, запись и обработка файлов в Python.
При доступе к файлу в операционной системе требуется правильно указать путь к файлу. Путь к файлу - это строка, которая представляет местоположение файла.
# Unix /path/to/file/text.txt # Windows c:\path\to\file\text.txt
Он разбит на три основные части:
- Путь к файлу
/path/to/file/: расположение директории в файловой системе, где папки разделены прямой косой чертой'/'в Unix подобных системах или обратной косой чертой'\'в Windows. - Имя файла
text: фактическое имя файла. - Расширение
.txt: используется для указания типа файла.
Для чтения или записи в файл нам необходимо его открыть, а для этого нужно передать путь к нужному файлу в качестве строки функции open(). Для Unix подобных систем это делается просто:
>>> full_path = '/path/to/file/text.txt' >>> print(full_path) # /path/to/file/text.txt
В системе Windows путь включает в себя обратную косую черту '\'. Этот символ в строках на Python используется для экранирования escape-последовательностей, таких как новая строка '\n'.
>>> full_path = 'c:\path\to\file\text.txt' >>> print(full_path) # c:\path o # ile ext.txt
Что бы избежать Windows системах такого безобразия, нам нужно вручную экранировать обратную косую черту '\\' или передавать в функции open() сырую (необработанную) строку, указав перед первой кавычкой строковой литерал 'r':
# экранируем обратную косую черту >>> full_path = 'c:\\path\\to\\file\\text.txt' >>> print(full_path) # c:\path\to\file\text.txt # строковой литерал raw строки >>> full_path = r'c:\path\to\file\text.txt' >>> print(full_path) # c:\path\to\file\text.txt
Открытие/закрытие файла для чтения/записи в Python.
Прежде чем начать работать с файлом, первое, что нужно сделать, это открыть его. Это делается путем вызова встроенной функции open(). Она имеет единственный обязательный аргумент, который представляет путь к файлу filename
Добавление данных в открытый файл в Python..Иногда может понадобиться добавить данные в файл или начать запись в конце уже заполненного файла. Это легко сделать, используя символ 'a' для аргумента mode функции open():
Сохранение словарей в формат JSON в Python.Для сохранения сложных типов данных в файлы, Python позволяет использовать популярный формат обмена данными, называемый JSON. pickle - это протокол, который позволяет сериализовать произвольно сложные объекты Python.
Работа с папками и создание путей с модулем OS в Python
Модуль Python OS используется для работы с операционной системой и является достаточно большим, что бы более конкретно описать его применение. С помощью его мы можем получать переменные окружения PATH, названия операционных систем, менять права на файлах и многое другое. В этой статье речь пойдет про работу с папками и путями, их создание, получение списка файлов и проверка на существование. Примеры приведены с Python 3, но и с предыдущими версиями ошибок быть не должно.
Модуль OS не нуждается в дополнительной установке, так как поставляется вместе с инсталлятором Python.
Есть несколько способов вернуть список каталогов и файлов по указанному пути. Первый способ используя os.walk, который возвращает генератор:
import os
path = 'C:/windows/system32/drivers/'
print(path)
Такие объекты можно итерировать для понятного отображения структуры:
import os
path = 'C:/Folder1'
for el in os.walk(path):
print(el)
Сам кортеж делится на 3 объекта: текущая директория, имя вложенных папок (если есть), список файлов. Я так же разделил их на примере ниже:
import os
path = 'C:/Folder1'
for dirs,folder,files in os.walk(path):
print('Выбранный каталог: ', dirs)
print('Вложенные папки: ', folder)
print('Файлы в папке: ', files)
print('\n')
Os.walk является рекурсивным методом. Это значит, что для поиска файлов в конкретной директории вы будете итерировать и все вложенные папки. Обойти это с помощью самого метода нельзя, но вы можете использовать break так как os.walk возвращает указанную директорию первой. Можно так же использовать next():
import os
path = 'C:/Folder1'
for dirs,folder,files in os.walk(path):
print('Выбранный каталог: ', dirs)
print('Вложенные папки: ', folder)
print('Файлы в папке: ', files)
print('\n')
# Отобразит только корневую папку и остановит цикл
break
# Отобразит первый итерируемый объект
directory = os.walk(path)
print(next(directory))
Получение файлов через listdir
Есть еще один метод получения файлов используя listdir. Отличия от предыдущего метода в том, что у нас не будет разделения файлов и папок. Он так же не является рекурсивным:
import os
path = 'C:/Folder1'
directory = os.listdir(path)
print(directory)
Получение полного абсолютного пути к файлам
Для последующего чтения файла нам может понадобится абсолютный путь. Мы можем использовать обычный метод сложения строк или метод os.path.join, который сделает то же самое, но и снизит вероятность ошибки если программа работает на разных ОС:
import os
path = 'C:/Folder1'
for dirs,folder,files in os.walk(path):
print('Выбранный каталог: ', dirs)
print('Вложенные папки: ', folder)
print('Файлы в папке: ', files)
print('Полный путь к файлу: ', os.path.join(dirs, files))
Исключение каталогов или файлов из списка
У нас может быть список полных путей, например из списка выше, из которого мы хотим исключить папки или файлы. Для этого используется os.path.isfile:
import os
path = ['C:/Folder1',
'C:/Folder1/Folder2/file2.txt']
for el in path:
if os.path.isfile(el):
print('Это файл: ', el)
else:
print('Это папка: ', el)
Такой же принцип имеют следующие методы:
- os.path.isdir() - относится ли путь к папке;
- os.path.islink() - относится ли путь к ссылке;
Получение расширения файлов
Расширение файла можно получить с помощью os.path.splittext(). Этот метод вернет путь до расширения и само расширение. Этот метод исключает ситуацию, когда точка может стоять в самом пути. Если в качестве пути мы выберем каталог (который не имеет расширения) , результатом будет пустая строка:
import os
path = ['C:/Folder1',
'C:/Folder1/Folder2/file2.txt']
for el in path:
print(os.path.splitext(el))
os.path.basename(path) - вернет имя файла и расширение.
Методы по изменению папок следующие:
- os.mkdir() - создаст папку;
- os.rename() - переименует;
- os.rmdir() - удалит.
import os
# Имя новой папки
path = 'C:/Folder1/NewFolder'
# Ее создание
os.mkdir(path)
# Переименуем папку
os.rename(path, 'C:/Folder1/NewFolder2')
# Удалим
os.rmdir('C:/Folder1/NewFolder2')
Если попытаться создать несколько вложенных папок сразу, используя предыдущий пример, появится ошибка FileNotFoundError. Создание папок включая промежуточные выполняется с os.makedirs():
import os
path = 'C:/Folder1/Folder1/Folder1/'
os.makedirs(path)
Проверка директорий и файлов на существование
Если мы пытаемся создать папку с существующим именем, то получим ошибку FileExistsError. Один из способов этого избежать - использование os.path.exists(), который вернет True в случае существования файла или папки:
import os
path = ['C:/Folder1/file1.txt',
'C:/Folder1/NotExistFolder']
for el in path:
if os.path.exists(el):
print('Такой путь существует: ', el)
else:
print('Такого пути нет', el)
Запуская любую программу или консоль, например CMD, мы это делаем из определенной директории. С этой и соседней директорией мы можем работать без указания полного пути. Для того что бы узнать такую директорию в Python используется метод os.getcwd():
import os
current_dir = os.getcwd()
print(current_dir)
В директории 'D:\' сохранен мой файл, с которого я запускаю методы. Вы можете изменить такую директорию с os.chdir() . Такой подход удобен, когда файлы, с которыми вы работаете в основном находятся в другом месте и вы сможете избежать написания полного пути:
import os
current_dir = os.getcwd()
print(current_dir)
new_dir = os.chdir('D:/newfolder/')
print(os.getcwd())
Так же как и в любых языках, в любых методах описанных выше, вы можете использовать '..' для работы с директорией выше или '/' для работы со внутренней:
import os
# Текущая директория
print(os.getcwd())
# Переход во внутреннюю
old_dir = os.chdir('/newfolder/')
print(os.getcwd())
# Переход на уровень выше
new_dir = os.chdir('..')
print(os.getcwd())
...
Теги: #python #os
Python 3: файлы - чтение и запись: open, read, write, seek, readline, dump, load, pickle
На этом занятии мы поговорим, как в Python можно считывать информацию из файлов и записывать ее в файлы. Что такое файлы и зачем они нужны, думаю объяснять не надо, т.к. если вы дошли до этого занятия, значит, проблем с пониманием таких базовых вещей у вас нет. Поэтому сразу перейдем к функции
open(file [, mode=’r’, encoding=None, …])
через которую и осуществляется работа с файлами. Здесь
- file – это путь к файлу вместе с его именем;
- mode – режим доступа к файлу;
- encoding – кодировка файла.
Для начала определимся с понятием «путь к файлу». Представим, что наш файл ex1.py находится в каталоге app:
Тогда, чтобы обратиться к файлу my_file.txt путь можно записать так:
"my_file.txt"
или
"d:\\app\\my_file.txt"
или так:
"d:/app/my_file.txt"
Последние два варианта представляют собой абсолютный путь к файлу, то есть, полный путь, начиная с указания диска. Причем, обычно используют обратный слеш в качестве разделителя: так короче писать и такой путь будет корректно восприниматься как под ОС Windows, так и Linux. Первый же вариант – это относительный путь, относительно рабочего каталога.
Теперь, предположим, мы хотим обратиться к файлу img.txt. Это можно сделать так:
"images/img.txt"
или так:
"d:/app/images/img.txt"
Для доступа к out.txt пути будут записаны так:
"../out.txt"
"d:/out.txt"
Обратите внимание, здесь две точки означают переход к родительскому каталогу, то есть, выход из каталога app на один уровень вверх.
И, наконец, для доступа к файлу prt.dat пути запишутся так:
"../parent/prt.dat"
"d:/ parent/prt.dat"
Вот так следует прописывать пути к файлам. В нашем случае мы имеем текстовый файл «myfile.txt», который находится в том же каталоге, что и программа ex1.py, поэтому путь можно записать просто указав имя файла:
file = open("myfile.txt") В результате переменная file будет ссылаться на файловый объект, через который и происходит работа с файлами. Если указать неверный путь, например, так:
file = open("myfile2.txt") то возникнет ошибка FileNotFoundError. Это стандартное исключение и как их обрабатывать мы с вами говорили на предыдущем занятии. Поэтому, запишем этот критический код в блоке try:
try: file = open("myfile2.txt") except FileNotFoundError: print("Невозможно открыть файл") Изменим имя файла на верное и посмотрим, как далее можно с ним работать. По умолчанию функция open открывает файл в текстовом режиме на чтение. Это режим
mode = "r"
Если нам нужно поменять режим доступа к файлу, например, открыть его на запись, то это явно указывается вторым параметром функции open:
file = open("out.txt", "w") В Python имеются следующие режимы доступа:
|
Название |
Описание |
|
'r' |
открытие на чтение (значение по умолчанию) |
|
'w' |
открытие на запись (содержимое файла удаляется, а если его нет, то создается новый) |
|
'x' |
открытие файла на запись, если его нет генерирует исключение |
|
'a' |
открытие на дозапись (информация добавляется в конец файла) |
|
Дополнения |
|
|
'b' |
открытие в бинарном режиме доступа к информации файла |
|
't' |
открытие в текстовом режиме доступа (если явно не указывается, то используется по умолчанию) |
|
'+' |
открытие на чтение и запись одновременно |
Здесь мы имеем три основных режима доступа: на чтение, запись и добавление. И еще три возможных расширения этих режимов, например,
- 'rt' – чтение в текстовом режиме;
- 'wb' – запись в бинарном режиме;
- 'a+' – дозапись или чтение данных из файла.
Чтение информации из файла
В чем отличие текстового режима от бинарного мы поговорим позже, а сейчас откроем файл на чтение в текстовом режиме:
file = open("myfile.txt") и прочитаем его содержимое с помощью метода read:
В результате, получим строку, в которой будет находиться прочитанное содержимое. Действительно, в этом файле находятся эти строчки из поэмы Пушкина А.С. «Медный всадник». И здесь есть один тонкий момент. Наш текстовый файл имеет кодировку Windows-1251 и эта кодировка используется по умолчанию в функции read. Но, если изменить кодировку файла, например, на популярную UTF-8, то после запуска программы увидим в консоли вот такую белиберду. Как это можно исправить, не меняя кодировки самого файла? Для этого следует воспользоваться именованным параметром encoding и записать метод open вот так:
file = open("myfile.txt", encoding="utf-8" ) Теперь все будет работать корректно. Далее, в методе read мы можем указать некий числовой аргумент, например,
Тогда из файла будут считаны первые два символа. И смотрите, если мы запишем два таких вызова подряд:
print( file.read(2) ) print( file.read(2) )
то увидим, что при следующем вызове метод read продолжил читать следующие два символа. Почему так произошло? Дело в том, что у файлового объекта, на который ссылается переменная file, имеется внутренний указатель позиции (file position), который показывает с какого места производить считывание информации.
Когда мы вызываем метод read(2) эта позиция автоматически сдвигается от начала файла на два символа, т.к. мы именно столько считываем. И при повторном вызове read(2) считывание продолжается, т.е. берутся следующие два символа. Соответственно, позиция файла сдвигается дальше. И так, пока не дойдем до конца.
Но мы в Python можем управлять этой файловой позицией с помощью метода
seek(offset[, from_what])
Например, вот такая запись:
будет означать, что мы устанавливаем позицию в начало и тогда такие строчки:
print( file.read(2) ) file.seek(0) print( file.read(2) )
будут считывать одни и те же первые символы. Если же мы хотим узнать текущую позицию в файле, то следует вызвать метод tell:
pos = file.tell() print( pos )
Следующий полезный метод – это readline позволяет построчно считывать информацию из текстового файла:
s = file.readline() print( s )
Здесь концом строки считается символ переноса ‘\n’, либо конец файла. Причем, этот символ переноса строки будет также присутствовать в строке. Мы в этом можем убедиться, вызвав дважды эту функцию:
print( file.readline() ) print( file.readline() )
Здесь в консоли строчки будут разделены пустой строкой. Это как раз из-за того, что один перенос идет из прочитанной строки, а второй добавляется самой функцией print. Поэтому, если их записать вот так:
print( file.readline(), end="" ) print( file.readline(), end="" )
то вывод будет построчным с одним переносом.
Если нам нужно последовательно прочитать все строчки из файла, то для этого обычно используют цикл for следующим образом:
for line in file: print( line, end="" )
Этот пример показывает, что объект файл является итерируемым и на каждой итерации возвращает очередную строку.
Или же, все строчки можно прочитать методом
и тогда переменная s будет ссылаться на упорядоченный список с этими строками:
Однако этот метод следует использовать с осторожностью, т.к. для больших файлов может возникнуть ошибка нехватки памяти для хранения полученного списка.
По сути это все методы для считывания информации из файла. И, смотрите, как только мы завершили работу с файлом, его следует закрыть. Для этого используется метод close:
Конечно, прописывая эту строчку, мы не увидим никакой разницы в работе программы. Но, во-первых, закрывая файл, мы освобождаем память, связанную с этим файлом и, во-вторых, у нас не будет проблем в потере данных при их записи в файл. А, вообще, лучше просто запомнить: после завершения работы с файлом, его нужно закрыть. Причем, организовать программу лучше так:
try: file = open("myfile.txt") try: s = file.readlines() print( s ) finally: file.close() except FileNotFoundError: print("Невозможно открыть файл") Мы здесь создаем вложенный блок try, в который помещаем критический текст программы при работе с файлом и далее блок finally, который будет выполнен при любом стечении обстоятельств, а значит, файл гарантированно будет закрыт.
Или же, забегая немного вперед, отмечу, что часто для открытия файла пользуются так называемым менеджером контекста, когда файл открывают при помощи оператора with:
try: with open("myfile.txt", "r") as file: # file = open("myfile.txt") s = file.readlines() print( s ) except FileNotFoundError: print("Невозможно открыть файл") При таком подходе файл закрывается автоматически после выполнения всех инструкций внутри этого менеджера. В этом можно убедиться, выведем в консоль флаг, сигнализирующий закрытие файла:
finally: print(file.closed)
Запустим программу, видите, все работает также и при этом файл автоматически закрывается. Даже если произойдет критическая ошибка, например, пропишем такую конструкцию:
то, как видим, файл все равно закрывается. Вот в этом удобство такого подхода при работе с файлами.
Запись информации в файл
Теперь давайте посмотрим, как происходит запись информации в файл. Во-первых, нам нужно открыть файл на запись, например, так:
file = open("out.txt", "w") и далее вызвать метод write:
file.write("Hello World!") В результате у нас будет создан файл out.txt со строкой «Hello World!». Причем, этот файл будет располагаться в том же каталоге, что и файл с текстом программы на Python.
Далее сделаем такую операцию: запишем метод write следующим образом:
И снова выполним эту программу. Смотрите, в нашем файле out.txt прежнее содержимое исчезло и появилось новое – строка «Hello». То есть, когда мы открываем файл на запись в режимах
w, wt, wb,
то прежнее содержимое файла удаляется. Вот этот момент следует всегда помнить.
Теперь посмотрим, что будет, если вызвать метод write несколько раз подряд:
file.write("Hello1") file.write("Hello2") file.write("Hello3") Смотрите, у нас в файле появились эти строчки друг за другом. То есть, здесь как и со считыванием: объект file записывает информацию, начиная с текущей файловой позиции, и автоматически перемещает ее при выполнении метода write.
Если мы хотим записать эти строчки в файл каждую с новой строки, то в конце каждой пропишем символ переноса строки:
file.write("Hello1\n") file.write("Hello2\n") file.write("Hello3\n") Далее, для дозаписи информации в файл, то есть, записи с сохранением предыдущего содержимого, файл следует открыть в режиме ‘a’:
file = open("out.txt", "a") Тогда, выполняя эту программу, мы в файле увидим уже шесть строчек. И смотрите, в зависимости от режима доступа к файлу, мы должны использовать или методы для записи, или методы для чтения. Например, если вот здесь попытаться прочитать информацию с помощью метода read:
то возникнет ошибка доступа. Если же мы хотим и записывать и считывать информацию, то можно воспользоваться режимом a+:
file = open("out.txt", "a+") Так как здесь файловый указатель стоит на последней позиции, то для считывания информации, поставим его в самое начало:
file.seek(0) print( file.read() )
А вот запись данных всегда осуществляется в конец файла.
Следующий полезный метод для записи информации – это writelines:
file.writelines(["Hello1\n", "Hello2\n"])
Он записывает несколько строк, указанных в коллекции. Иногда это бывает удобно, если в процессе обработки текста мы имеем список и его требуется целиком поместить в файл.
Чтение и запись в бинарном режиме доступа
Что такое бинарный режим доступа? Это когда данные из файла считываются один в один без какой-либо обработки. Обычно это используется для сохранения и считывания объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books = [ ("Евгений Онегин", "Пушкин А.С.", 200), ("Муму", "Тургенев И.С.", 250), ("Мастер и Маргарита", "Булгаков М.А.", 500), ("Мертвые души", "Гоголь Н.В.", 190) ] Откроем файл на запись в бинарном режиме:
file = open("out.bin", "wb") Далее, для работы с бинарными данными подключим специальный встроенный модуль pickle:
И вызовем него метод dump:
Все, мы сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на чтение в бинарном режиме:
file = open("out.bin", "rb") и далее вызовем метод load модуля pickle:
Все, теперь переменная bs ссылается на эквивалентный список:
Аналогичным образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle book1 = ["Евгений Онегин", "Пушкин А.С.", 200] book2 = ["Муму", "Тургенев И.С.", 250] book3 = ["Мастер и Маргарита", "Булгаков М.А.", 500] book4 = ["Мертвые души", "Гоголь Н.В.", 190] try: file = open("out.bin", "wb") try: pickle.dump(book1, file) pickle.dump(book2, file) pickle.dump(book3, file) pickle.dump(book4, file) finally: file.close() except FileNotFoundError: print("Невозможно открыть файл") А, затем, считывание в том же порядке:
file = open("out.bin", "rb") b1 = pickle.load(file) b2 = pickle.load(file) b3 = pickle.load(file) b4 = pickle.load(file) print( b1, b2, b3, b4, sep="\n" ) Вот так в Python выполняется запись и считывание данных из файла.
Задания для самоподготовки
1. Выполните считывание данных из текстового файла через символ и записи прочитанных данных в другой текстовый файл. Прочитывайте так не более 100 символов.
2. Пользователь вводит предложение с клавиатуры. Разбейте это предложение по словам (считать, что слова разделены пробелом) и сохраните их в столбец в файл.
3. Пусть имеется словарь:
d = {"house":
"дом", "car": "машина",
"tree":
"дерево", "road": "дорога",
"river":
"река"}
Необходимо каждый элемент этого словаря сохранить в бинарном файле как объект. Затем, прочитать этот файл и вывести считанные объекты в консоль.
создание полного пути к файлу в python,
это прекрасно работает:
os.path.join(dir_name, base_filename + "." + filename_suffix) имейте в виду, что os.path.join() существует только потому, что разные операционные системы используют разные символы разделителя путей. Это сглаживает эту разницу, поэтому кросс-платформенный код не должен быть загроможден специальными случаями для каждой ОС. Нет необходимости делать это для имен файлов "расширения" (см. сноску), потому что они всегда отделены от остальной части имени одним и тем же символом точки На каждой ОС.
при использовании функции в любом случае, вы чувствуете себя лучше (и вам нравится бессмысленно усложнять свой код), вы можете сделать это:
os.path.join(dir_name, '.'.join((base_filename, filename_suffix))) если вы предпочитаете, чтобы ваш код был чистым, просто включите точку в суффикс:
suffix = '.pdf' os.path.join(dir_name, base_filename + suffix) сноска: нет такой вещи, как имя файла "расширение" на не-Micorsoft операционных систем. Его присутствие в Windows происходит от MS-DOS и FAT, который заимствовал его из CP/M, который был мертв в течение десятилетий. Точка-плюс-три-буквы, которыми многие из нас являются. привыкли видеть только часть имени файла на любой другой современной ОС, где он не имеет встроенного значения.
python - Как мне получить полный путь к каталогу текущего файла?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
Как получить абсолютный путь к файлу в Python
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
python - Как создать файл по определенному пути?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд
python - Как правильно указать путь к файлу ввода / вывода?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд
Учебное пособие по Python: файлы Python и os.path
Файлы Python и os.path
bogotobogo.com поиск по сайту:
Справочники
Модуль os содержит функции для получения информации о локальных каталогах, файлах, процессах и переменных среды.
os.getcwd ()
Текущий рабочий каталог - это свойство, которое Python постоянно хранит в памяти.Всегда существует текущий рабочий каталог, независимо от того, находимся ли мы в оболочке Python, запускаем собственный сценарий Python из командной строки и т. Д.
>>> import os >>> печать (os.getcwd ()) C: \ Python32 >>> os.chdir ('/ тест') >>> печать (os.getcwd ()) C: \ test Мы использовали функцию os.getcwd () , чтобы получить текущий рабочий каталог. Когда мы запускаем графическую оболочку Python, текущий рабочий каталог начинается как каталог, в котором находится исполняемый файл оболочки Python.В Windows это зависит от того, где мы установили Python; каталог по умолчанию - c: \ Python32. Если мы запустим оболочку Python из командной строки, текущий рабочий каталог запускается как каталог, в котором мы находились при запуске python3.
Затем мы использовали функцию os.chdir () , чтобы изменить текущий рабочий каталог. Обратите внимание, что когда мы вызывали функцию os.chdir () , мы использовали путь в стиле Linux (косая черта, без буквы диска), даже если мы находимся в Windows. Это одно из мест, где Python пытается скрыть различия между операционными системами.
os.path.join ()
os.path содержит функции для управления именами файлов и именами каталогов.
>>> import os >>> print (os.path.join ('/ test /', 'myfile')) / test / myfile >>> print (os.path.expanduser ('~')) C: \ Пользователи \ K >>> print (os.path.join (os.path.expanduser ('~'), 'dir', 'subdir', 'k.py')) C: \ Users \ K \ dir \ subdir \ k.py Функция os.path.join () создает имя пути из одного или нескольких частичных имен путей.В этом случае он просто объединяет строки. Вызов функции os.path.join () добавит дополнительную косую черту к имени пути перед присоединением его к имени файла.
Функция os.path.expanduser () расширит путь, который использует ~ для представления домашнего каталога текущего пользователя. Это работает на любой платформе, где у пользователей есть домашний каталог, включая Linux, Mac OS X и Windows. Возвращаемый путь не имеет завершающей косой черты, но os.Функция path.join () не против.
Комбинируя эти методы, мы можем легко создать пути для каталогов и файлов в домашнем каталоге пользователя. Функция os.path.join () может принимать любое количество аргументов.
Примечание: нам нужно быть осторожными со строкой, когда мы используем os.path.join . Если мы используем «/», он сообщает Python, что мы используем абсолютный путь, и переопределяет путь перед ним:
>>> import os >>> print (os.путь.join ('/ тест /', '/ мой файл')) /мой файл Как мы видим, пути "/ test /" больше нет!
os.path.split ()
os.path также содержит функции для разделения полных путей, имен каталогов и имен файлов на их составные части.
>>> pathname = "/Users/K/dir/subdir/k.py" >>> os.path.split (путь) ('/ Пользователи / K / каталог / подкаталог', 'k.py') >>> (имя каталога, имя файла) = os.path.split (путь) >>> dirname '/ Users / K / dir / subdir' >>> путь '/ Пользователи / K / dir / subdir / k.py ' >>> имя файла 'k.py' >>> (короткое имя, расширение) = os.path.splitext (имя файла) >>> короткое имя 'k' >>> расширение '.py' Функция split () разделяет полное имя пути и возвращает кортеж , содержащий путь и имя файла. Функция os.path.split () действительно возвращает несколько значений. Мы присваиваем возвращаемое значение функции разделения кортежу из двух переменных. Каждая переменная получает значение соответствующего элемента возвращаемого кортежа.Первая переменная, dirname , получает значение первого элемента кортежа, возвращаемого функцией os.path.split () , путь к файлу. Вторая переменная, filename , получает значение второго элемента кортежа, возвращенного функцией os.path.split () , имя файла.
os.path также содержит функцию os.path.splitext () , которая разбивает имя файла и возвращает кортеж, содержащий имя файла и расширение файла.Мы использовали ту же технику, чтобы назначить каждую из них отдельным переменным.
glob.glob ()
Модуль glob - еще один инструмент в стандартной библиотеке Python. Это простой способ получить содержимое каталога программно, и в нем используются символы подстановки, с которыми мы, возможно, уже знакомы по работе в командной строке.
>>> import glob >>> os.chdir ('/ тест') >>> import glob >>> glob.glob ('subdir / *. py') ['subdir \\ tes3.py ',' subdir \\ test1.py ',' subdir \\ test2.py '] Модуль glob принимает подстановочный знак и возвращает путь ко всем файлам и каталогам, соответствующим подстановочному знаку.
Метаданные файла
Каждая файловая система хранит метаданных о каждом файле: дата создания, дата последнего изменения, размер файла и так далее. Python предоставляет единый API для доступа к этим метаданным. Нам не нужно открывать файл, все, что нам нужно, это имя файла.
>>> import os >>> print (os.getcwd ()) C: \ test >>> os.chdir ('subdir') >>> печать (os.getcwd ()) C: \ test \ subdir >>> метаданные = os.stat ('test1.py') >>> metadata.st_mtime 1359868355.9555483 >>> время импорта >>> time.localtime (metadata.st_mtime) time.struct_time (tm_year = 2013, tm_mon = 2, tm_mday = 2, tm_hour = 21, tm_min = 12, tm_sec = 35, tm_wday = 5, tm_yday = 33, tm_isdst = 0) >>> metadata.st_size 1844 г. Вызов функции os.stat () возвращает объект, который содержит несколько различных типов метаданных о файле. st_mtime - время модификации, но в формате, который не очень полезен. Фактически, это количество секунд, прошедшее с Эпохи, которая определяется как первая секунда 1 января 1970 года.
Модуль time является частью стандартной библиотеки Python. Он содержит функции для преобразования между различными представлениями времени, форматирования значений времени в строки и работы с часовыми поясами.
Функция time.localtime () преобразует значение времени из секунд с начала эпохи (из свойства st_mtime , возвращенного из os.stat () ) в более удобную структуру года, месяца, дня, часа, минуты, секунды и так далее. В последний раз этот файл был изменен 2 февраля 2013 г., около 21:12.
Функция os.stat () также возвращает размер файла в свойстве st_size . Размер файла test1.py составляет 1844 байта.
os.path.realpath () - Абсолютный путь
Функция glob.glob () вернула список относительных путей к . Если мы хотим создать абсолютный путь - i.е. тот, который включает все имена каталогов обратно в корневой каталог или букву диска - тогда нам понадобится функция os.path.realpath () .
>>> import os >>> печать (os.getcwd ()) C: \ test \ subdir >>> print (os.path.realpath ('test1.py')) C: \ test \ subdir \ test1.py os.path.expandvars () - Env. переменная
Функция expandvars вставляет переменные среды в имя файла.
>>> import os >>> os.Environment ['SUBDIR'] = 'subdir' >>> print (os.path.expandvars ('/ home / users / K / $ SUBDIR')) / home / users / K / subdir Открытие файлов
Чтобы открыть файл, мы используем встроенную функцию open () :
myfile = open ('mydir / myfile.txt', 'ш') Функция open () принимает в качестве аргумента имя файла . Здесь имя файла - mydir / myfile.txt , а следующий аргумент - это режим обработки . Обычно это строка 'r', для открытия ввода текста (это режим по умолчанию), 'w' для создания и открытия для вывода текста.Строка 'a' открывается для добавления текста в конец. Аргумент режима может указывать дополнительные параметры: добавление 'b' к строке режима позволяет использовать двоичные данные , а добавление + открывает файл для как для ввода, так и для вывода .
В таблице ниже перечислены несколько комбинаций режимов обработки:
| Режим | Описание |
|---|---|
| r | Открывает файл только для чтения.Указатель файла помещается в начало файла. Это режим "по умолчанию". |
| руб | Открывает файл для чтения только в двоичном формате. Указатель файла помещается в начало файла. Это режим "по умолчанию". |
| р + | Открывает файл для чтения и записи. Указатель файла будет в начале файла. |
| руб. + | Открывает файл для чтения и записи в двоичном формате.Указатель файла будет в начале файла. |
| Вт | Открывает файл только для записи. Заменяет файл, если он существует. Если файл не существует, создает новый файл для записи. |
| ВБ | Открывает файл для записи только в двоичном формате. Заменяет файл, если он существует. Если файл не существует, создает новый файл для записи. |
| Вт + | Открывает файл для записи и чтения.Заменяет существующий файл, если он существует. Если файл не существует, создает новый файл для чтения и записи. |
| Открывает файл для добавления. Указатель файла находится в конце файла, если файл существует. То есть файл находится в режиме добавления. Если файл не существует, создается новый файл для записи. | |
| ab | Открывает файл для добавления в двоичном формате. Указатель файла находится в конце файла, если файл существует.То есть файл находится в режиме добавления. Если файл не существует, создается новый файл для записи. |
| а + | Открывает файл для добавления и чтения. Указатель файла находится в конце файла, если файл существует. Файл открывается в режиме добавления. Если файл не существует, создается новый файл для чтения и записи. |
| ab + | Открывает файл в двоичном формате для добавления и чтения. Указатель файла находится в конце файла, если файл существует.Файл открывается в режиме добавления. Если файл не существует, создается новый файл для чтения и записи. |
Есть вещи, которые мы должны знать об имени файла :
- Это не просто имя файла. Это комбинация пути к каталогу и имени файла. В Python всякий раз, когда нам нужно имя файла , мы также можем включить часть или весь путь к каталогу.
- В пути к каталогу используется косая черта без упоминания операционной системы.Windows использует обратную косую черту для обозначения подкаталогов, а Linux - прямую косую черту. Но в Python косая черта всегда работает, даже в Windows.
- Путь к каталогу не начинается с косой черты или буквы диска, поэтому он называется относительным путем.
- Это строка. Все современные операционные системы используют Unicode для хранения имен файлов и каталогов. Python 3 полностью поддерживает пути, отличные от ASCII.
Кодировка символов
Строка - это последовательность символов Юникода.Файл на диске - это не последовательность символов Юникода, а последовательность байтов. Итак, если мы читаем файл с диска, как Python преобразует эту последовательность байтов в последовательность символов?
Внутренне Python декодирует байты в соответствии с определенным алгоритмом кодирования символов и возвращает последовательность символьной строки Unicode.
У меня есть файл ("Alone.txt"):
나 혼자 (Один) - Автор: Sistar 추억 이 이리 많을 까 넌 대체 뭐 할까 아직 난 이래 혹시 돌아 올까 봐
Попробуем прочитать файл:
>>> file = open ('Alone.текст') >>> str = file.read () Отслеживание (последний вызов последний): Файл "", строка 1, в str = file.read () Файл "C: \ Python32 \ lib \ encodings \ cp1252.py", строка 23, в декодировании return codecs.charmap_decode (input, self.errors, decoding_table) [0] UnicodeDecodeError: кодек charmap не может декодировать байт 0x90 в позиции 6: символы отображаются в >>> # 7> Что только что произошло?
Мы не указали кодировку символов, поэтому Python вынужден использовать кодировку по умолчанию.
Какая кодировка по умолчанию? Если мы внимательно посмотрим на трассировку, мы увидим, что она дает сбой в cp1252.py, что означает, что Python использует здесь CP-1252 в качестве кодировки по умолчанию. (CP-1252 - это обычная кодировка на компьютерах под управлением Microsoft Windows.) Набор символов CP-1252 не поддерживает символы, содержащиеся в этом файле, поэтому чтение завершается ошибкой UnicodeDecodeError .
На самом деле, когда я показываю корейский символ, мне приходилось помещать следующие строки html в раздел заголовка:
->
ASCII и Unicode
Существуют кодировки символов для всех основных языков мира.Поскольку каждый язык индивидуален, а память и дисковое пространство исторически были дорогими, каждая кодировка символов оптимизирована для конкретного языка. Каждая кодировка использует одни и те же числа ( 0-255 ) для представления символов этого языка. Например, кодировка ASCII , в которой английские символы хранятся в виде чисел от 0 до 127. ( 65, - заглавная, A, , 97, - строчная, a ). В английском языке очень простой алфавит, поэтому его можно полностью выразить менее чем в 128 числах.
западноевропейских языков, таких как французский, испанский и немецкий, содержат больше букв, чем английский. Наиболее распространенная кодировка для этих языков - CP-1252 . Кодировка CP-1252 разделяет символы с ASCII в диапазоне 0-127 , но затем расширяется до диапазона 128-255 для таких символов, как - , - и т. Д. Это все еще однобайтовая кодировка, хотя; максимально возможное число 255 по-прежнему умещается в одном байте.
Кроме того, существуют такие языки, как китайский и корейский, в которых так много символов, что для них требуются многобайтовые наборы символов.То есть каждый символ представлен двухбайтовым числом ( 0-65535 ). Но разные многобайтовые кодировки по-прежнему имеют ту же проблему, что и разные однобайтовые кодировки, а именно то, что каждая из них использует одни и те же числа для обозначения разных вещей. Просто диапазон чисел шире, потому что символов гораздо больше.
Unicode разработан для представления каждого символа любого языка. Юникод представляет каждую букву, символ или идеограмму как 4-байтовое число.Каждое число представляет собой уникальный символ, используемый как минимум в одном из языков мира. На каждый символ приходится ровно 1 число и ровно 1 символ на число. Каждое число всегда означает только одно; нет режимов , за которыми нужно следить. U + 0061 всегда 'a' , даже если в языке нет 'a' .
Кажется, это отличная идея. Одна кодировка, чтобы управлять ими всеми. Несколько языков в документе. Больше нет переключения режимов для переключения между кодировками в середине потока.Но четыре байта на каждый символ? Это действительно расточительно, особенно для таких языков, как английский и испанский, которым требуется менее одного байта (256 чисел) для выражения всех возможных символов.
Юникод - UTF-32
Существует кодировка Unicode, которая использует четыре байта на символ. Он называется UTF-32 , потому что 32 бита = 4 байта. UTF-32 - это простая кодировка; он принимает каждый символ Юникода (4-байтовое число) и представляет символ с тем же номером.Это имеет некоторые преимущества, наиболее важным из которых является то, что мы можем найти N-й символ строки за постоянное время, потому что N-й символ начинается с 4xN-го байта. У него также есть несколько недостатков, самый очевидный из которых состоит в том, что для хранения каждого чертового символа требуется четыре байта.
Юникод - UTF-16
Несмотря на то, что существует много символов Unicode, оказывается, что большинство людей никогда не будут использовать ничего, кроме первого 65535. Таким образом, существует другая кодировка Unicode, называемая UTF-16 (потому что 16 бит = 2 байта).UTF-16 кодирует каждый символ из 0-65535 как два байта , а затем использует некоторые грязные хаки, если нам действительно нужно представить редко используемые символы Unicode за пределами 65535. Наиболее очевидное преимущество: UTF-16 вдвое больше пробела - эффективен как UTF-32, потому что для хранения каждого символа требуется только два байта вместо четырех. И мы все еще можем легко найти N-й символ строки за постоянное время.
Но есть и неочевидные недостатки UTF-32 и UTF-16.В разных компьютерных системах отдельные байты хранятся по-разному. Это означает, что символ U + 4E2D может быть сохранен в UTF-16 как 4E 2D или 2D 4E, в зависимости от того, является ли система прямым или прямым порядком байтов. (Для UTF-32 существует еще больше возможных порядков байтов.)
Чтобы решить эту проблему, многобайтовые кодировки Unicode определяют Byte Order Mark , который представляет собой специальный непечатаемый символ, который мы можем включить в начало нашего документа, чтобы указать, в каком порядке находятся наши байты.Для UTF-16 метка порядка байтов - U + FEFF. Если мы получаем документ UTF-16, который начинается с байтов FF FE, мы знаем, что порядок байтов односторонний; если он начинается с FE FF, мы знаем, что порядок байтов обратный.
Тем не менее, UTF-16 не совсем идеален, особенно если мы имеем дело с большим количеством символов ASCII. Если подумать, даже китайская веб-страница будет содержать множество символов ASCII - все элементы и атрибуты, окружающие печатные китайские символы. Возможность найти N-й символ за постоянное время - это хорошо, но мы не можем гарантировать, что каждый символ имеет ровно два байта, поэтому мы не сможем найти N-й символ за постоянное время, если не будем поддерживать отдельный индекс.
Юникод - UTF-8
UTF-8 - это система кодирования переменной длины для Unicode. То есть разные символы занимают разное количество байтов. Для ASCII символов (A-Z) UTF-8 использует только один байт на символ. Фактически, он использует одни и те же байты; первые 128 символов (0–127) в UTF-8 неотличимы от ASCII. Расширенная латиница символов, таких как ñ и ü, занимают два байта . (Байты - это не просто кодовая точка Unicode, как в UTF-16; здесь присутствует серьезное искажение битов.) Китайские символы , такие как çŽ ‹, занимают три байта . Редко используемые символы астрального плана занимают четыре байта .
Недостатки : поскольку каждый символ может занимать разное количество байтов, поиск N-го символа представляет собой операцию O (N), то есть чем длиннее строка, тем больше времени требуется для поиска определенного символа. Кроме того, используется перестановка битов для кодирования символов в байты и декодирования байтов в символы.
Преимущества : сверхэффективное кодирование распространенных символов ASCII. Не хуже, чем UTF-16 для расширенных латинских символов. Лучше, чем UTF-32 для китайских иероглифов. Также нет проблем с порядком байтов. Документ, закодированный в utf-8, использует один и тот же поток байтов на любом компьютере.
Файловый объект
Функция open () возвращает объект файла , который имеет методы и атрибуты для получения информации о потоке символов и управления им.
>>> file = open ('Alone.txt') >>> file.mode 'р' >>> имя_файла "Alone.txt" >>> file.encoding 'cp1252' Если указать кодировку:
>>> # - * - кодировка: utf-8 - * - >>> file = open ('Alone.txt', кодировка = 'utf-8') >>> file.encoding 'utf-8' >>> str = file.read () >>> ул. '나 혼자 (В одиночестве) - By Sistar \ n 추억 이 이리 많을 까 넌 대체 뭐 할까 \ n 아직 난 이래 올까 봐 \ n' Первая строка - это объявление кодировки , которое необходимо для того, чтобы Python знал о корейском языке.
Атрибут name отражает имя, которое мы передали функции open () при открытии файла. Атрибут encoding отражает кодировку, которую мы передали в функцию open () . Если мы не указали кодировку при открытии файла, тогда атрибут кодировки будет отражать locale.getpreferredencoding () . Атрибут mode сообщает нам, в каком режиме был открыт файл. Мы можем передать необязательный параметр режима функции open () .Мы не указали режим при открытии этого файла, поэтому по умолчанию Python имеет значение 'r' , что означает, что открыт только для чтения в текстовом режиме . Файл mode служит нескольким целям; разные режимы позволяют нам записывать в файл, добавлять в файл или открывать файл в двоичном режиме.
читать ()
>>> file = open ('Alone.txt', кодировка = 'utf-8') >>> str = file.read () >>> ул. '나 혼자 (В одиночестве) - By Sistar \ n 추억 이 이리 많을 까 넌 대체 뭐 할까 \ n 아직 난 이래 올까 봐 \ n' >>> файл.читать() '' Повторное чтение файла не вызывает исключения. Python не считает чтение последнего конца файла ошибкой; он просто возвращает пустую строку.
>>> file.read () ''
Поскольку мы все еще находимся в конце файла, дальнейшие вызовы метода read () объекта потока просто возвращают пустую строку.
>>> file.seek (0) 0
Метод seek () перемещается к определенной позиции байта в файле.
>>> file.read (10) '나 혼자 (Алон' >>> file.seek (0) 0 >>> file.read (15) '나 혼자 (Один) -' >>> file.read (1) 'B' >>> file.read (10) 'y Sistar \ n 추' >>> file.tell () 34
Метод read () может принимать необязательный параметр, количество символов для чтения. Мы также можем читать по одному символу за раз. Методы seek (), и tell () всегда считают байты, но поскольку мы открыли этот файл как текст, метод read () считает символы.Для кодирования корейских символов в UTF-8 требуется несколько байтов. Для английских символов в файле требуется только один байт, поэтому мы можем ошибиться, полагая, что методы seek () и read () считают одно и то же. Но это верно только для некоторых персонажей.
закрыть ()
Важно закрыть файлы, как только мы закончим с ними, потому что открытые файлы потребляют системные ресурсы, и в зависимости от файлового режима другие программы могут не иметь к ним доступа.
>>> file.close () >>> file.read () Отслеживание (последний вызов последний): Файл "", строка 1, в file.read () ValueError: операция ввода-вывода для закрытого файла. >>> file.seek (0) Отслеживание (последний вызов последний): Файл "", строка 1, в file.seek (0) ValueError: операция ввода-вывода для закрытого файла. >>> file.tell () Отслеживание (последний вызов последний): Файл "", строка 1, в file.tell () ValueError: операция ввода-вывода для закрытого файла. >>> file.close () >>> файл.закрыто Правда # 39> # 38> # 37>
- Мы не можем читать из закрытого файла; что вызывает исключение IOError .
- Мы не можем искать и в закрытом файле.
- В закрытом файле нет текущей позиции, поэтому метод tell () также не работает.
- Вызов метода close () для объекта потока, файл которого был закрыт, не вызывает исключения. Это просто no-op .
- Закрытые объекты потока действительно имеют один полезный атрибут: закрытый атрибут подтверждает, что файл закрыт.
"с" выпиской
ОбъектыStream имеют явный метод close () , но что произойдет, если в нашем коде есть ошибка и произойдет сбой до того, как мы вызовем close () ? Теоретически этот файл может оставаться открытым дольше необходимого.
Возможно, мы могли бы использовать блок try..inally . Но у нас есть более чистое решение, которое сейчас является предпочтительным решением в Python 3: с оператором :
>>> с помощью open ('Alone.txt ', encoding =' utf-8 ') как файл: file.seek (16) char = file.read (1) печать (символ) 16 о Приведенный выше код никогда не вызывает file.close () . Оператор с оператором запускает блок кода, например оператор if или цикл for . Внутри этого блока кода мы можем использовать переменную file в качестве объекта потока , возвращенного в результате вызова open () . Доступны все обычные методы потокового объекта - seek () , read () , все, что нам нужно.Когда блок with заканчивается, Python автоматически вызывает file.close () .
Обратите внимание, что независимо от того, как и когда мы выходим из блока with, Python закроет этот файл, даже если мы выйдем из него через необработанное исключение. Другими словами, даже если наш код вызывает исключение и вся наша программа останавливается, этот файл будет закрыт. Гарантированно.
Фактически, оператор с оператором создает контекст выполнения . В этих примерах объект потока действует как диспетчер контекста.Python создает объект потока , файл и сообщает ему, что он входит в контекст выполнения. Когда блок кода with завершен, Python сообщает объекту потока, что он выходит из контекста времени выполнения, и объект потока вызывает свой собственный метод close () .
В операторе with нет ничего специфичного для файла; это просто общая структура для создания контекстов времени выполнения и сообщения объектам о том, что они входят в контекст выполнения и выходят из него. Если рассматриваемый объект является объектом потока, он автоматически закрывает файл.Но это поведение определяется в объекте потока, а не в инструкции with. Есть много других способов использования диспетчеров контекста, которые не имеют ничего общего с файлами.
Чтение строк по одной
Строка текста - это последовательность символов, разделенных чем именно? Что ж, это сложно, потому что текстовые файлы могут использовать несколько разных символов для обозначения конца строки. Каждая операционная система имеет свое собственное соглашение. Некоторые используют символ возврата каретки (\ r), другие используют символ перевода строки (\ n), а некоторые используют оба символа (\ r \ n) в конце каждой строки.
Однако Python по умолчанию автоматически обрабатывает окончания строк. Python определит, какой тип строки используется в конце текстового файла, и все это будет работать за нас.
# line.py lineCount = 0 с open ('Daffodils.txt', encoding = 'utf-8') в виде файла: для строки в файле: lineCount + = 1 print ('{: <5} {}'. format (lineCount, line.rstrip ())) Если запустить:
C: \ ТЕСТ> python line.py 1 Я блуждал одиноким, как облако 2 Что плывет по долинам и холмам, 3 Когда я вдруг увидел толпу, 4 Множество золотых нарциссов;
- Используя шаблон with, мы безопасно открываем файл и позволяем Python закрыть его за нас.
- Чтобы читать файл по одной строке за раз, используйте цикл for. Вот и все. Помимо явных методов, таких как read () , объект потока также является итератором, который выводит одну строку каждый раз, когда мы запрашиваем значение.
- Используя строковый метод format () , мы можем распечатать номер строки и саму строку. Спецификатор формата {: <5} означает, что печатает этот аргумент с выравниванием по левому краю в пределах 5 пробелов . Переменная a_line содержит всю строку, возврат каретки и все остальное.Строковый метод rstrip () удаляет завершающие пробелы, включая символы возврата каретки.
написать ()
Мы можем писать в файлы почти так же, как читаем из них. Сначала мы открываем файл и получаем объект файла, затем используем методы объекта потока для записи данных в файл, а затем закрываем файл.
Метод write () записывает строку в файл. Нет возвращаемого значения. Из-за буферизации strin
.Как найти информацию о пути в Python
- Программирование
- Python
- Как найти информацию о пути в Python
Автор Джон Пол Мюллер
Чтобы использовать код в модуле, Python должен иметь возможность найдите модуль и загрузите его в память. Информация о местоположении хранится в виде путей в Python. Когда вы запрашиваете у Python импорт модуля, Python просматривает все файлы в своем списке путей, чтобы найти его. Информация о пути поступает из трех источников:
-
Переменные среды: Переменные среды Python, такие как PYTHONPATH, сообщают Python, где искать модули на диске.
-
Текущий каталог: Вы можете изменить текущий каталог Python, чтобы он мог найти любые модули, используемые вашим приложением.
-
Каталоги по умолчанию: Даже если вы не определяете какие-либо переменные среды, а текущий каталог не дает каких-либо используемых модулей, Python все равно может найти свои собственные библиотеки в наборе каталогов по умолчанию, которые включены как часть его собственного пути Информация.
Полезно знать информацию о текущем пути, потому что отсутствие пути может привести к сбою вашего приложения.Следующие шаги демонстрируют, как получить информацию о пути:
-
Откройте оболочку Python.
Вы видите, что появляется окно Python Shell.
-
Введите import sys и нажмите Enter.
-
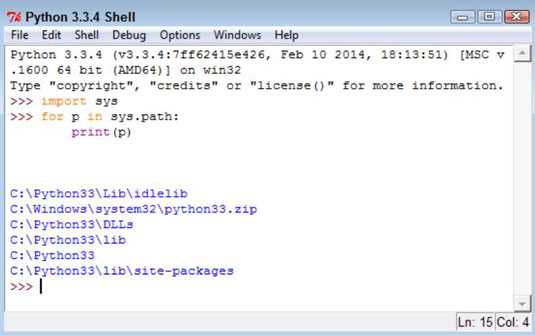
Введите p в sys.path: и нажмите Enter.
Python автоматически делает отступ для следующей строки. Атрибут sys.path всегда содержит список путей по умолчанию.
-
Введите print (p) и дважды нажмите Enter.
Вы видите список информации о пути. Ваш список может отличаться в зависимости от вашей платформы, установленной вами версии Python и установленных вами функций Python.
Атрибут sys.path надежен, но не всегда может содержать все пути, которые видит Python. Если вы не видите нужный путь, вы всегда можете проверить в другом месте, где Python ищет информацию. Следующие шаги показывают, как выполнить эту задачу:
-
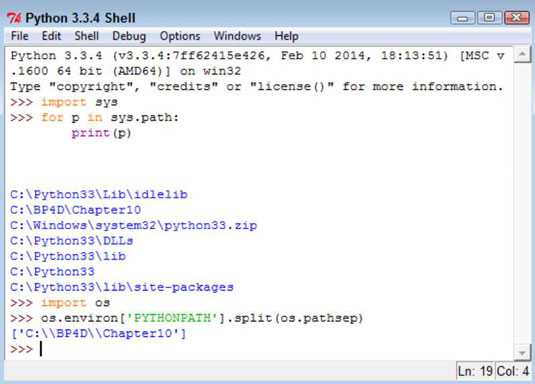
Введите import os и нажмите Enter.
-
Введите os.environ [‘PYTHONPATH’]. Split (os.pathsep) и нажмите Enter.
Когда у вас определена переменная среды PYTHONPATH, вы видите список путей. Однако, если у вас не определена переменная среды, вместо этого вы увидите сообщение об ошибке.
Атрибут sys.path не включает функцию split (), поэтому в примере с ним используется цикл for. Однако атрибут os.environ [‘PYTHONPATH’] действительно включает функцию split (), поэтому вы можете использовать ее для создания списка отдельных путей.
Вы должны предоставить split () значение, которое нужно искать при разбиении списка элементов. Константа os.pathsep (переменная с одним неизменяемым определенным значением) определяет разделитель путей для текущей платформы, так что вы можете использовать тот же код на любой платформе, поддерживающей Python.
-
Закройте оболочку Python.
Окно Python Shell закрывается.
Вы также можете добавлять и удалять элементы из sys.путь.
Об авторе книги
Джон Пол Мюллер - внештатный автор и технический редактор, на его счету более 107 книг и 600 статей. Его предметы варьируются от сетей и искусственного интеллекта до управления базами данных и программирования без головы. Он также консультирует и пишет сертификационные экзамены. Посетите его веб-сайт http://www.johnmuellerbooks.com/.
.