Как правильно составить файл robots txt
Как создать правильный файл robots.txt, настройка, директивы

Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt , для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
составляем правильный роботс для Wordpress и других систем
Содержание статьи
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
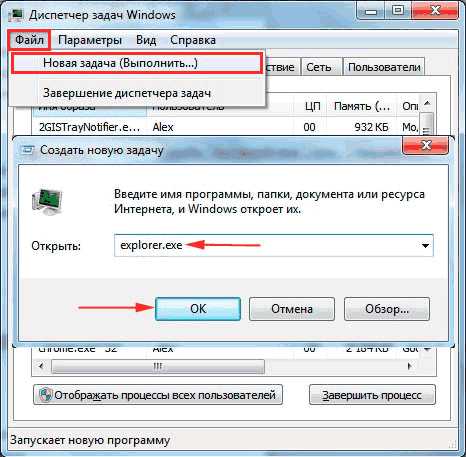
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: https://znet.ru/sitemap.xml
Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
User-agent: * Allow: /
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Яндекс: Yandex
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
User-agent: Yandex
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
User-agent: *
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: https://znet.ru/sitemap.xml
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow: /page.html
А если мне нужно закрыть все страницы, которые начинаются с https://znet.ru/instrumenty/? То есть страницы https://znet.ru/instrumenty/1.html, https://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Disallow: /instrumenty/
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу https://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.html
В таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example.html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: https://znet.ru/sitemap.xml
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.
А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
Robots.txt - Как создать правильный robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта — Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется "robots.txt", название написано только строчными буквами, "Robots.TXT" и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: "сайт.рф" — "xn--80aswg.xn--p1ai".
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву "disallow". Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег "noindex" или "none".
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — "noindex" или атрибута "rel" со значением "nofollow".
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или "nofollow" , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена "/robots.txt".
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру "noflashhtml" и "backhtml". Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте "noindex".
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
"*" — означает любую последовательность символов в файле.
"$" — ограничивает действия "*", представляет конец строки.
"/" — показывает, что закрывают для сканирования.
"/catalog/" — закрывают раздел каталога;
"/catalog" — закрывают все ссылки, которые начинаются с "/catalog".
"#" — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на ".pdf":
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата "Disallow: /about" без закрывающего "/" запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с "/about".
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с "/catalog", а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл "photo.html" разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам "site.com/catalog1/" и "site.com/catalog2/" но разрешить к "catalog2/subcatalog1/":
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
"www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123"
"www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123"
"www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123"
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
"www.example. com/some_dir/get_book.pl? book_id=123"
Для адресов вида:
"www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df"
"www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
"www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243"
"www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
"www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311"
"www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без "http://" и без закрывающего слэша "/".
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
 Графы инструмента для заполнения
Графы инструмента для заполнения Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Файл robots.txt - настройка и директивы robots.txt, запрещаем индексацию страниц
Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:
Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.
Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексацию страницы?
Как запретить индексацию зеркала?
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
Понравился пост? Сделай репост и подпишись!
как правильно составить и для чего он нужен
Поисковые роботы индексируют всё, что находят. Даже админпанель с личной информацией. Robots.txt — это специальный файл для ботов с правилами, по которым они начинают работать с вашим сайтом. В этом файле вы и прописываете всё, что разрешаете или запрещаете им делать.
Важный файл robots.txt
Для чего нужен
Для того, чтобы ваш сайт быстрее индексировался, в поиск не попадали ненужные страницы или приватная информация. «Ненужные страницы» — это дубликаты товарных категорий, личная информация, формы отправки данных, страницы с результатами поиска и т.п. Robots.txt устанавливает строгие правила для поисковиков, если же эти правила не указать, то вся ваша информация окажется в сети и удалить её из архивов интернета будет практически нереально.
Где писать этот файл и где его располагать
Писать можно в любом удобном для вас редакторе — в обычном встроенном блокноте для Windows, NotePad или Word — не суть. Главное, чтобы этот файл был сохранён в текстовом формате, то есть с расширением .txt.
В нашей системе вставить инструкцию для поисковых ботов на сайт очень просто: выберите в левой панели управления сайтом раздел «Реклама/SEO → Управление robots.txt».
Управление robots.txt находится в разделе «Реклама/SEO»
И в открывшееся поле вы просто вставляете готовую инструкцию (с помощью функции «копировать — вставить»).
На нашем сервисе файл robots.txt автоматически генерируется системой. В большинстве случаев он полностью отвечает всем требованиям поисковых роботов и закрывает от индексации те страницы, которые не должны быть на виду. Но вы можете создать свою инструкцию или внести любые изменения в готовый файл. В случае необходимости всегда можно восстановить первоначальный вариант.
Правила синтаксиса robots.txt
Поисковый робот учитывает только определённые выражения и алгоритмы. Поэтому инструкция составляется на понятном ему «языке». Вот основные команды, которые «понимает» робот:
- User-Agent: Имя бота поисковой системы. Для Яндекса это Yandex, для Google — Google-bot, для Mail.ru — Mail.ru. Весь список названий роботов-поисковиков перечислен на этой странице.
- Allow — команда «разрешить».
- Disallow — команда «запретить».
- Host — имя вашего хостера (на 1C-UMI это robot.umi.ru).
Директива Allow не является обязательной, а вот Disallow нужно указывать. По умолчанию файл robots.txt разрешает всё, поэтому прописывать нужно только запрещающие команды.
Правильный синтаксис написания: команда → двоеточие → пробел → слеш (/) → точное наименование страницы.
Точное наименование страницы — это весь путь, который ведёт на указанную страницу, начиная с главной: мойсайт.рф — мода — женская мода — верхняя одежда — пальто — чёрное пальто в горошек.
Пример:
- Вы разрешаете поисковому боту Яндекс индексировать всё, кроме страницы «Контакты»:
- User-Agent: Yandex
- Allow:
- Disallow: /contacts
- Если вы разрешаете индексировать сайт всем поисковым системам, то после User-Agent нужно поставить знак *:
- Если вы ничего не запрещаете к индексации, то после disallow ничего не ставите:
- Если вы запрещаете какому-то определённому боту индексировать свой сайт, то ставите его имя и запрещающую команду disallow вместе со слешем:
- User-Agent: googlebot-image (робот-поисковик по картинкам в Гугл)
- Disallow: /
Disallow относится только к тому боту, который указан перед командой. Для каждого робота нужно прописывать команды индивидуально.
Как не запутаться в названиях ботов и командах
Есть удобная функция «комментарий», которую вы можете использовать при составлении robots.txt. Всё, что вы хотите прокомментировать, оставить какое-либо уточнение, отмечайте символом #. Всё, что будет написано после этого знака, роботом не учитывается.
User-Agent: Yandex
Disallow: /Price/ #Не индексировать каталог с ценами.
Как установить период захода на сайт робота-поисковика
Чтобы уменьшить нагрузку на сервер, нужно использовать директиву (команду для робота-поисковика) Crawl-delay. Она устанавливает период, за который робот-поисковик должен обойти сайт, или время, за которое робот просмотрит все страницы сайта и внесёт их в индекс. Другими словами, эта директива позволяет ускорить обход сайта роботом. Обычно устанавливается на сайт-многостраничник. Если у вас страниц ещё немного, не больше двухсот, то этот параметр можно не указывать.
Прописывается это так:
- User-Agent: Yandex
- Disallow: /contacts
- Craw-delay: 2 #Тайм-аут обхода 2 секунды
Тайм-аут обхода вы можете указать любой. Это не гарантирует, что на ваш сайт робот будет заходить каждые 2 (3, 4, 5…) секунд, вы просто даёте ему приблизительное время обхода. Если ваш сайт уже хорошо ранжируется, то роботы будут заходить на него чаще, если сайт ещё молод, то реже. В справке Яндекс об этом параметре написано подробней.
Ошибки при составлении robots.txt
Рассмотрим самые популярные ошибки, которые совершают пользователи при создании файла.
|
Ошибки |
Правильно |
|
Путаница в инструкциях User-Agent: / Disallow: Googlebot |
User-Agent: Googlebot Disallow: / |
|
Несколько каталогов в одной строке Disallow Disallow: /moda/ hat/ images |
Disallow: /moda/ Disallow: /hat/ Disallow: /images/ |
|
Пустая строка в указании имени поискового робота User-Agent: Disallow: |
User-Agent: * Disallow: |
|
Заглавные буквы USER-AGENT: YANDEX ALLOW: |
User-Agent: Yandex Allow: |
|
Перечисление каждого файла в категории User-Agent: Googlebot Disallow: / moda/ krasnoe-palto.html Disallow: /moda/ sinee-palto.html Disallow: /moda/ zelenoe-palto.html Disallow: /moda/ seroe-palto.html Disallow: /price/ women.html Disallow: /price/ men.html |
User-Agent: Googlebot Disallow: / moda/ Disallow: /price/ |
Не забывайте про знак слеш (/). Если его не будет, то робот запретит к индексации все файлы и категории с таким же названием. Например, если вы не укажете слеш в директиве: “Disallow: moda”, то из индекса выпадут все страницы, рубрики и категории, где встречается это название.
Правила написания robots.txt
- Каждую команду надо писать с новой строки.
- В одной строке — одна директива.
- В начале строки не должно быть пробела.
- Команды не берут в кавычки.
- В конце директивы не ставится точка с запятой, запятая или точка.
- Disallow: равнозначно Allow: / (всё разрешено).
- Поисковые роботы чувствительны к регистру букв — прописывайте имена файлов и категорий точно так же, как они указаны на вашем сайте.
- Если у вас нет robots.txt, это сигнал для поисковиков, что запрещений нет, индексировать можно всё.
- В robots.txt используется только английский язык. Все другие языки игнорируются.
Как проверить robots.txt на правильность написания
Есть специальные сервисы, которые проверяют, правильно ли составлен разрешающий файл. Проверьте свой robots.txt на сайте Яндекс или в Гугл.
Автоматическое создание robots.txt
Если для вас сложно самостоятельно написать инструкцию для ботов, то создайте её автоматически. На сайте pr-cy файл будет сгенерирован за 10 секунд, просто укажите нужные вам параметры, потом скопируйте текст и вставьте его в поле для robots.txt на нашем сервисе.Директивы — базовая информация
Директивы – это своеобразный свод правил поведения на страничках сайта для robots.txt. Считывая их, поисковый агент и понимает, какой контент можно использовать для индексации сайта, а какой нельзя.Если директивы не прописать вовсе, поисковик скачает с вашего сайта всю информацию и проиндексирует. Последствием этих действий станет его медленная загрузка. Очевидно, что такие сайты меньше посещают пользователи и не помещают в вершинах выдачи поисковые системы.
Ниже перечислим разные типы директив, с пояснениями.
User-agent
Если перевести на простой язык, то «User-agent» - это призыв к некоему действию. После этого директива обычно прописывается наименование robots.txt, которому сообщается информация, а далее — уже сама информация. Иными словами, User-agent — самая важная директива для robots.txt.
Вот так выглядят директивы User-agent для разных поисковых машин:
- User-agent: *; - для всех видов роботов.
- User-agent: Yandex; - для роботов поисковика Яндекс.
- User-agent: Googlebot. - для роботов поисковика Google.
- User-agent: Mail.Ru. - для роботов Mail.ru
- User-agent: Slurp – для роботов Yahoo!
- User-agent: MSNBot – для роботов MSN
- User-agent: StackRambler – для роботов Рамблера.
Disallow
Директива, запрещающая индексировать те или иные странички веб-сайта. Веб-мастера советуют прописывать ее для следующих типов страниц:
- Корзине и всем сопутствующим оформлению заказа страничкам.
- Поисковым формам.
- Административной панели сайта.
- Ajax, Json - эти скрипты выводят всплывающие формы для заполнения, рекламные баннеры и так далее.
Allow
Это директива, наоборот, открывает страничку сайта для чтения роботом.
Sitemap
Простыми словами — директива, отображающая карту вашего сайта. Сообщая роботу структуру вашего сайта, вы ускоряете его индексацию.
Host
Указывает поисковому роботу на зеркало вашего сайта, куда будут попадать пользователи.
Crawl-delay
Помогает снижать нагрузку на сервер, задавая минимальный временной интервал между обращениями к сервису.
Общие рекомендации любых директив:
- Не прописывайте в одной строчке больше одной директивы.
- Убирайте пробелы в начале строк.
- Только полная директива без лишних символов будет работать.
- Код файла robots.txt немыслим без Disallow.
Robots.txt напрямую влияет на индексацию сайта, поэтому обязательно установите свои правила для поисковых ботов. Успешного вам продвижения!
Управление файлами Robots.txt и Sitemap
- 7 минут на чтение
В этой статье
Руслан Якушев
Набор инструментов поисковой оптимизации IIS включает функцию Исключение роботов , которую вы можете использовать для управления содержимым файла Robots.txt для вашего веб-сайта, а также включает функцию Sitemaps и Sitemap Indexes , которую вы можете использовать для управления своими карты сайта.В этом пошаговом руководстве объясняется, как и зачем использовать эти функции.
Фон
Сканеры поисковых систем будут тратить на ваш веб-сайт ограниченное время и ресурсы. Поэтому очень важно сделать следующее:
- Запретить поисковым роботам индексировать содержимое, которое не является важным или которое не должно отображаться на страницах результатов поиска.
- Направьте поисковые роботы на контент, который вы считаете наиболее важным для индексации.
Для решения этих задач обычно используются два протокола: протокол исключения роботов и протокол Sitemaps.
Протокол исключения роботов используется для указания сканерам поисковых систем, какие URL-адреса НЕ следует запрашивать при сканировании веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта. Большинство поисковых роботов обычно ищут этот файл и следуют содержащимся в нем инструкциям.
Протокол Sitemaps используется для информирования сканеров поисковых систем об URL-адресах, доступных для сканирования на вашем веб-сайте. Кроме того, файлы Sitemap используются для предоставления некоторых дополнительных метаданных об URL-адресах сайта, таких как время последнего изменения, частота изменений, относительный приоритет и т. Д.Поисковые системы могут использовать эти метаданные при индексировании вашего веб-сайта.
Предварительные требования
1. Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам понадобится размещенный веб-сайт IIS 7 или более поздней версии или веб-приложение, которым вы управляете. Если у вас его нет, вы можете установить его из галереи веб-приложений Microsoft. В этом пошаговом руководстве мы будем использовать популярное приложение для ведения блогов DasBlog.
2. Анализ веб-сайта
Если у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как обычная поисковая система будет сканировать его содержимое.Для этого выполните действия, описанные в статьях «Использование анализа сайта для сканирования веб-сайта» и «Использование отчетов анализа сайта». Когда вы проведете свой анализ, вы, вероятно, заметите, что у вас есть определенные URL-адреса, которые доступны для сканирования поисковыми системами, но что нет никакой реальной пользы от их сканирования или индексации. Например, страницы входа или страницы ресурсов даже не должны запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Управление файлом Robots.txt
Вы можете использовать функцию исключения роботов IIS SEO Toolkit для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не должны сканироваться или индексироваться. Следующие шаги описывают, как использовать этот инструмент.
- Откройте консоль управления IIS, набрав INETMGR в меню «Пуск».
- Перейдите на свой веб-сайт, используя древовидное представление слева (например, веб-сайт по умолчанию).
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Добавить новое правило запрета » в разделе Исключение роботов .
Добавление запрещающих и разрешающих правил
Диалоговое окно «Добавить запрещающие правила» откроется автоматически:
Протокол исключения роботов
использует директивы «Разрешить» и «Запрещать», чтобы информировать поисковые системы о путях URL, которые можно сканировать, и тех, которые нельзя сканировать.Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Древовидное представление пути URL-адреса используется для выбора запрещенных URL-адресов. Вы можете выбрать один из нескольких вариантов при выборе путей URL с помощью раскрывающегося списка «Структура URL»:
- Физическое расположение - вы можете выбрать пути из физической структуры файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) - вы можете выбрать пути из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта IIS.
- <Запустить новый анализ сайта ...> - вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда пути URL.
После выполнения шагов, описанных в разделе предварительных требований, вам будет доступен анализ сайта. Выберите анализ в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо скрыть от поисковых систем, установив флажки в дереве «Пути URL-адресов»:
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите OK.Вы увидите новые запрещающие записи в главном окне функций:
Также будет обновлен файл Robots.txt для сайта (или создан, если он не существует). Его содержимое будет выглядеть примерно так:
Агент пользователя: * Запретить: /EditConfig.aspx Запретить: /EditService.asmx/ Запретить: / images / Запретить: /Login.aspx Запретить: / scripts / Запретить: /SyndicationService.asmx/ Чтобы увидеть, как работает Robots.txt, вернитесь к функции анализа сайта и повторно запустите анализ сайта.На странице «Сводка отчетов» в категории « ссылок » выберите « ссылок, заблокированных файлом Robots.txt ». В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
Управление файлами карты сайта
Вы можете использовать функцию Sitemaps и Sitemap Indexes IIS SEO Toolkit для создания карт сайта на своем веб-сайте, чтобы информировать поисковые системы о страницах, которые следует сканировать и проиндексировать.Для этого выполните следующие действия:
- Откройте диспетчер IIS, набрав INETMGR в меню Пуск .
- Перейдите на свой веб-сайт с помощью древовидной структуры слева.
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Создать новую карту сайта » в разделе «Карты сайта и индексы файлов Sitemap ».
- Диалоговое окно Добавить карту сайта откроется автоматически.
- Введите имя файла карты сайта и нажмите ОК . Откроется диалоговое окно Добавить URL-адреса .
Добавление URL в карту сайта
Диалоговое окно Добавить URL-адреса выглядит так:
Файл Sitemap представляет собой простой XML-файл, в котором перечислены URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Используйте диалоговое окно Добавить URL-адреса для добавления новых записей URL-адресов в XML-файл Sitemap.Каждый URL-адрес в карте сайта должен иметь полный формат URI (т.е. он должен включать префикс протокола и имя домена). Итак, первое, что вам нужно указать, - это домен, который будет использоваться для URL-адресов, которые вы собираетесь добавить в карту сайта.
Древовидное представление пути URL-адреса используется для выбора URL-адресов, которые следует добавить в карту сайта для индексации. Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
- Физическое расположение - вы можете выбрать URL-адреса из физического макета файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) - вы можете выбрать URL-адреса из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта.
- <Запустить новый анализ сайта ...> - вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда URL-пути, которые вы хотите добавить для индексации.
После того, как вы выполнили шаги, указанные в разделе предварительных требований, вам будет доступен анализ сайта.Выберите его из раскрывающегося списка, а затем проверьте URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры Частота изменения , Дата последнего изменения и Приоритет , а затем нажмите ОК , чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
http: // myblog / 2009/03/11 / Поздравляю, вы установилиDasBlogWithWebDeploy.aspx 2009-06-03T16: 05: 02 еженедельно 0,5 http: //myblog/2009/06/02/ASPNETAndURLRewriting.aspx 2009-06-03T16: 05: 01 еженедельно 0,5 Добавление местоположения карты сайта в Robots.txt файл
Теперь, когда вы создали карту сайта, вам нужно сообщить поисковым системам, где она расположена, чтобы они могли начать ее использовать. Самый простой способ сделать это - добавить URL-адрес карты сайта в файл Robots.txt.
В функции Sitemaps и Sitemap Indexes выберите только что созданную карту сайта, а затем щелкните Добавить в Robots.txt на панели Actions :
Ваш файл Robots.txt будет выглядеть примерно так:
Агент пользователя: * Запретить: / EditService.asmx / Запретить: / images / Запретить: / scripts / Запретить: /SyndicationService.asmx/ Запретить: /EditConfig.aspx Запретить: /Login.aspx Карта сайта: http: //myblog/sitemap.xml Регистрация карты сайта в поисковых системах
Помимо добавления местоположения карты сайта в файл Robots.txt, рекомендуется отправить URL-адрес карты сайта в основные поисковые системы. Это позволит вам получать полезный статус и статистику о вашем веб-сайте с помощью инструментов для веб-мастеров поисковой системы.
Сводка
В этом пошаговом руководстве вы узнали, как использовать функции исключения роботов, файлов Sitemap и Sitemap Indexes набора инструментов поисковой оптимизации IIS для управления файлами Robots.txt и Sitemap на вашем веб-сайте. IIS Search Engine Optimization Toolkit предоставляет интегрированный набор инструментов, которые работают вместе, чтобы помочь вам создать и проверить правильность файлов Robots.txt и карты сайта, прежде чем поисковые системы начнут их использовать.
.Как оптимизировать ваш Robots.txt для SEO в WordPress (Руководство для начинающих)
Недавно один из наших читателей попросил нас дать советы о том, как оптимизировать файл robots.txt для улучшения SEO. Файл Robots.txt сообщает поисковым системам, как сканировать ваш сайт, что делает его невероятно мощным инструментом SEO. В этой статье мы покажем вам, как создать идеальный файл robots.txt для SEO.

Что такое файл robots.txt?
Robots.txt - это текстовый файл, который владельцы веб-сайтов могут создать, чтобы сообщить роботам поисковых систем, как сканировать и индексировать страницы на своем сайте.
Обычно он хранится в корневом каталоге, также известном как основная папка вашего веб-сайта. Базовый формат файла robots.txt выглядит так:
Пользовательский агент: [имя пользовательского агента] Disallow: [строка URL не сканироваться] Пользовательский агент: [имя пользовательского агента] Разрешить: [строка URL для сканирования] Карта сайта: [URL-адрес вашего XML-файла Sitemap]
У вас может быть несколько строк инструкций, чтобы разрешить или запретить определенные URL-адреса и добавить несколько карт сайта.Если вы не запрещаете URL-адрес, роботы поисковых систем предполагают, что им разрешено сканировать его.
Вот как может выглядеть файл примера robots.txt:
Пользовательский агент: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Карта сайта: https://example.com/sitemap_index.xml
В приведенном выше примере robots.txt мы разрешили поисковым системам сканировать и индексировать файлы в нашей папке загрузки WordPress.
После этого мы запретили поисковым роботам сканировать и индексировать плагины и папки администратора WordPress.
Наконец, мы предоставили URL-адрес нашей XML-карты сайта.
Вам нужен файл Robots.txt для вашего сайта WordPress?
Если у вас нет файла robots.txt, поисковые системы все равно будут сканировать и индексировать ваш сайт. Однако вы не сможете указать поисковым системам, какие страницы или папки им не следует сканировать.
Это не окажет большого влияния, когда вы впервые создаете блог и у вас мало контента.
Однако по мере того, как ваш веб-сайт растет и у вас появляется много контента, вы, вероятно, захотите лучше контролировать то, как ваш веб-сайт сканируется и индексируется.
Вот почему.
У поисковых роботов есть квота сканирования для каждого веб-сайта.
Это означает, что они просматривают определенное количество страниц во время сеанса сканирования. Если они не завершат сканирование всех страниц вашего сайта, они вернутся и возобновят сканирование в следующем сеансе.
Это может снизить скорость индексации вашего сайта.
Вы можете исправить это, запретив поисковым роботам пытаться сканировать ненужные страницы, такие как ваши административные страницы WordPress, файлы плагинов и папку тем.
Запрещая ненужные страницы, вы сохраняете квоту сканирования. Это помогает поисковым системам сканировать еще больше страниц на вашем сайте и индексировать их как можно быстрее.
Еще одна веская причина использовать файл robots.txt - это когда вы хотите, чтобы поисковые системы не индексировали сообщение или страницу на вашем веб-сайте.
Это не самый безопасный способ скрыть контент от широкой публики, но он поможет вам предотвратить их появление в результатах поиска.
Что делают идеальные роботы.txt должен выглядеть как файл?
Многие популярные блоги используют очень простой файл robots.txt. Их содержание может отличаться в зависимости от потребностей конкретного сайта:
Пользовательский агент: * Запретить: Карта сайта: http://www.example.com/post-sitemap.xml Карта сайта: http://www.example.com/page-sitemap.xml
Этот файл robots.txt позволяет всем ботам индексировать весь контент и предоставляет им ссылку на XML-карту сайта веб-сайта.
Для сайтов WordPress мы рекомендуем следующие правила в файле robots.txt файл:
Пользовательский агент: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Запретить: /readme.html Запретить: / ссылаться / Карта сайта: http://www.example.com/post-sitemap.xml Карта сайта: http://www.example.com/page-sitemap.xml
Указывает поисковым роботам индексировать все изображения и файлы WordPress. Он запрещает поисковым роботам индексировать файлы плагинов WordPress, область администрирования WordPress, файл readme WordPress и партнерские ссылки.
Добавляя карты сайта в файл robots.txt, вы упрощаете роботам Google поиск всех страниц на вашем сайте.
Теперь, когда вы знаете, как выглядит идеальный файл robots.txt, давайте посмотрим, как создать файл robots.txt в WordPress.
Как создать файл Robots.txt в WordPress?
Есть два способа создать файл robots.txt в WordPress. Вы можете выбрать наиболее подходящий для вас метод.
Метод 1. Редактирование роботов.txt с помощью Yoast SEO
Если вы используете плагин Yoast SEO, он поставляется с генератором файлов robots.txt.
Вы можете использовать его для создания и редактирования файла robots.txt прямо из админки WordPress.
Просто перейдите на страницу SEO »Инструменты в админке WordPress и щелкните ссылку Редактор файлов.
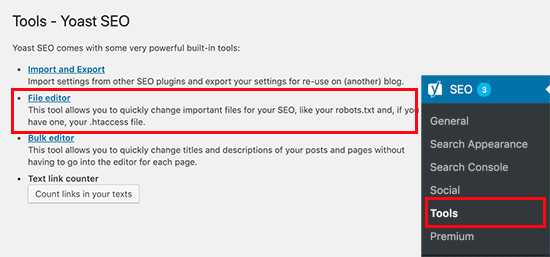
На следующей странице Yoast SEO покажет существующий файл robots.txt.
Если у вас нет файла robots.txt, то Yoast SEO сгенерирует для вас файл robots.txt.
По умолчанию генератор файлов robots.txt Yoast SEO добавляет в файл robots.txt следующие правила:
Пользовательский агент: * Запретить: /
Это важно, , чтобы вы удалили этот текст, потому что он блокирует сканирование вашего сайта всеми поисковыми системами.
После удаления текста по умолчанию вы можете продолжить и добавить свои собственные правила robots.txt. Мы рекомендуем использовать идеальных роботов.txt, который мы использовали выше.
Когда вы закончите, не забудьте нажать кнопку «Сохранить файл robots.txt», чтобы сохранить изменения.
Метод 2. Отредактируйте файл Robots.txt вручную с помощью FTP
Для этого метода вам нужно будет использовать FTP-клиент для редактирования файла robots.txt.
Просто подключитесь к своей учетной записи хостинга WordPress с помощью FTP-клиента.
Попав внутрь, вы сможете увидеть файл robots.txt в корневой папке вашего сайта.
Если вы его не видите, скорее всего, у вас нет robots.txt файл. В этом случае вы можете просто создать его.
Robots.txt - это простой текстовый файл, что означает, что вы можете загрузить его на свой компьютер и отредактировать с помощью любого текстового редактора, например Блокнота или TextEdit.
После сохранения изменений вы можете загрузить их обратно в корневую папку вашего сайта.
Как проверить файл robots.txt?
После создания файла robots.txt всегда рекомендуется протестировать его с помощью инструмента тестирования robots.txt.
Существует множество инструментов для тестирования robots.txt, но мы рекомендуем использовать тот, который находится в консоли поиска Google.
Просто войдите в свою учетную запись Google Search Console, а затем переключитесь на старый сайт поисковой консоли Google.
Вы перейдете к старому интерфейсу Google Search Console. Отсюда вам нужно запустить тестер robots.txt, расположенный в меню «Сканирование».
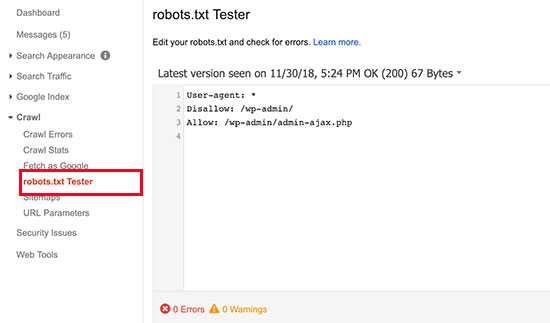
Инструмент автоматически загрузит роботов с вашего сайта.txt и выделите ошибки и предупреждения, если они были обнаружены.
Последние мысли
Цель оптимизации файла robots.txt - запретить поисковым системам сканировать страницы, которые не являются общедоступными. Например, страницы в папке wp-plugins или страницы в папке администратора WordPress.
Среди экспертов по SEO распространен миф о том, что блокировка категорий, тегов и архивных страниц WordPress улучшит скорость сканирования и приведет к более быстрой индексации и более высокому ранжированию.
Это неправда. Это также противоречит рекомендациям Google для веб-мастеров.
Мы рекомендуем использовать указанный выше формат robots.txt для создания файла robots.txt для своего веб-сайта.
Мы надеемся, что эта статья помогла вам узнать, как оптимизировать файл robots.txt WordPress для SEO. Вы также можете увидеть наше полное руководство по WordPress SEO и лучшие инструменты WordPress SEO для развития вашего сайта.
Если вам понравилась эта статья, то подпишитесь на наш канал YouTube для видеоуроков по WordPress.Вы также можете найти нас в Twitter и Facebook.
.Управление файлами Robots.txt и Sitemap
- 7 минут на чтение
В этой статье
Руслан Якушев
Набор инструментов поисковой оптимизации IIS включает функцию Исключение роботов , которую вы можете использовать для управления содержимым файла Robots.txt для вашего веб-сайта, а также включает функцию Sitemaps и Sitemap Indexes , которую вы можете использовать для управления своими карты сайта.В этом пошаговом руководстве объясняется, как и зачем использовать эти функции.
Фон
Сканеры поисковых систем будут тратить на ваш веб-сайт ограниченное время и ресурсы. Поэтому очень важно сделать следующее:
- Запретить поисковым роботам индексировать содержимое, которое не является важным или которое не должно отображаться на страницах результатов поиска.
- Направьте поисковые роботы на контент, который вы считаете наиболее важным для индексации.
Для решения этих задач обычно используются два протокола: протокол исключения роботов и протокол Sitemaps.
Протокол исключения роботов используется для указания сканерам поисковых систем, какие URL-адреса НЕ следует запрашивать при сканировании веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта. Большинство поисковых роботов обычно ищут этот файл и следуют содержащимся в нем инструкциям.
Протокол Sitemaps используется для информирования сканеров поисковых систем об URL-адресах, доступных для сканирования на вашем веб-сайте. Кроме того, файлы Sitemap используются для предоставления некоторых дополнительных метаданных об URL-адресах сайта, таких как время последнего изменения, частота изменений, относительный приоритет и т. Д.Поисковые системы могут использовать эти метаданные при индексировании вашего веб-сайта.
Предварительные требования
1. Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам понадобится размещенный веб-сайт IIS 7 или более поздней версии или веб-приложение, которым вы управляете. Если у вас его нет, вы можете установить его из галереи веб-приложений Microsoft. В этом пошаговом руководстве мы будем использовать популярное приложение для ведения блогов DasBlog.
2. Анализ веб-сайта
Если у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как обычная поисковая система будет сканировать его содержимое.Для этого выполните действия, описанные в статьях «Использование анализа сайта для сканирования веб-сайта» и «Использование отчетов анализа сайта». Когда вы проведете свой анализ, вы, вероятно, заметите, что у вас есть определенные URL-адреса, которые доступны для сканирования поисковыми системами, но что нет никакой реальной пользы от их сканирования или индексации. Например, страницы входа или страницы ресурсов даже не должны запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Управление файлом Robots.txt
Вы можете использовать функцию исключения роботов IIS SEO Toolkit для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не должны сканироваться или индексироваться. Следующие шаги описывают, как использовать этот инструмент.
- Откройте консоль управления IIS, набрав INETMGR в меню «Пуск».
- Перейдите на свой веб-сайт, используя древовидное представление слева (например, веб-сайт по умолчанию).
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Добавить новое правило запрета » в разделе Исключение роботов .
Добавление запрещающих и разрешающих правил
Диалоговое окно «Добавить запрещающие правила» откроется автоматически:
Протокол исключения роботов
использует директивы «Разрешить» и «Запрещать», чтобы информировать поисковые системы о путях URL, которые можно сканировать, и тех, которые нельзя сканировать.Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Древовидное представление пути URL-адреса используется для выбора запрещенных URL-адресов. Вы можете выбрать один из нескольких вариантов при выборе путей URL с помощью раскрывающегося списка «Структура URL»:
- Физическое расположение - вы можете выбрать пути из физической структуры файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) - вы можете выбрать пути из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта IIS.
- <Запустить новый анализ сайта ...> - вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда пути URL.
После выполнения шагов, описанных в разделе предварительных требований, вам будет доступен анализ сайта. Выберите анализ в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо скрыть от поисковых систем, установив флажки в дереве «Пути URL-адресов»:
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите OK.Вы увидите новые запрещающие записи в главном окне функций:
Также будет обновлен файл Robots.txt для сайта (или создан, если он не существует). Его содержимое будет выглядеть примерно так:
Агент пользователя: * Запретить: /EditConfig.aspx Запретить: /EditService.asmx/ Запретить: / images / Запретить: /Login.aspx Запретить: / scripts / Запретить: /SyndicationService.asmx/ Чтобы увидеть, как работает Robots.txt, вернитесь к функции анализа сайта и повторно запустите анализ сайта.На странице «Сводка отчетов» в категории « ссылок » выберите « ссылок, заблокированных файлом Robots.txt ». В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
Управление файлами карты сайта
Вы можете использовать функцию Sitemaps и Sitemap Indexes IIS SEO Toolkit для создания карт сайта на своем веб-сайте, чтобы информировать поисковые системы о страницах, которые следует сканировать и проиндексировать.Для этого выполните следующие действия:
- Откройте диспетчер IIS, набрав INETMGR в меню Пуск .
- Перейдите на свой веб-сайт с помощью древовидной структуры слева.
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Создать новую карту сайта » в разделе «Карты сайта и индексы файлов Sitemap ».
- Диалоговое окно Добавить карту сайта откроется автоматически.
- Введите имя файла карты сайта и нажмите ОК . Откроется диалоговое окно Добавить URL-адреса .
Добавление URL в карту сайта
Диалоговое окно Добавить URL-адреса выглядит так:
Файл Sitemap представляет собой простой XML-файл, в котором перечислены URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Используйте диалоговое окно Добавить URL-адреса для добавления новых записей URL-адресов в XML-файл Sitemap.Каждый URL-адрес в карте сайта должен иметь полный формат URI (т.е. он должен включать префикс протокола и имя домена). Итак, первое, что вам нужно указать, - это домен, который будет использоваться для URL-адресов, которые вы собираетесь добавить в карту сайта.
Древовидное представление пути URL-адреса используется для выбора URL-адресов, которые следует добавить в карту сайта для индексации. Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
- Физическое расположение - вы можете выбрать URL-адреса из физического макета файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) - вы можете выбрать URL-адреса из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта.
- <Запустить новый анализ сайта ...> - вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда URL-пути, которые вы хотите добавить для индексации.
После того, как вы выполнили шаги, указанные в разделе предварительных требований, вам будет доступен анализ сайта.Выберите его из раскрывающегося списка, а затем проверьте URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры Частота изменения , Дата последнего изменения и Приоритет , а затем нажмите ОК , чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
http: // myblog / 2009/03/11 / Поздравляю, вы установилиDasBlogWithWebDeploy.aspx 2009-06-03T16: 05: 02 еженедельно 0,5 http: //myblog/2009/06/02/ASPNETAndURLRewriting.aspx 2009-06-03T16: 05: 01 еженедельно 0,5 Добавление местоположения карты сайта в Robots.txt файл
Теперь, когда вы создали карту сайта, вам нужно сообщить поисковым системам, где она расположена, чтобы они могли начать ее использовать. Самый простой способ сделать это - добавить URL-адрес карты сайта в файл Robots.txt.
В функции Sitemaps и Sitemap Indexes выберите только что созданную карту сайта, а затем щелкните Добавить в Robots.txt на панели Actions :
Ваш файл Robots.txt будет выглядеть примерно так:
Агент пользователя: * Запретить: / EditService.asmx / Запретить: / images / Запретить: / scripts / Запретить: /SyndicationService.asmx/ Запретить: /EditConfig.aspx Запретить: /Login.aspx Карта сайта: http: //myblog/sitemap.xml Регистрация карты сайта в поисковых системах
Помимо добавления местоположения карты сайта в файл Robots.txt, рекомендуется отправить URL-адрес карты сайта в основные поисковые системы. Это позволит вам получать полезный статус и статистику о вашем веб-сайте с помощью инструментов для веб-мастеров поисковой системы.
Сводка
В этом пошаговом руководстве вы узнали, как использовать функции исключения роботов, файлов Sitemap и Sitemap Indexes набора инструментов поисковой оптимизации IIS для управления файлами Robots.txt и Sitemap на вашем веб-сайте. IIS Search Engine Optimization Toolkit предоставляет интегрированный набор инструментов, которые работают вместе, чтобы помочь вам создать и проверить правильность файлов Robots.txt и карты сайта, прежде чем поисковые системы начнут их использовать.
.Управление файлами Robots.txt и Sitemap
- 7 минут на чтение
В этой статье
Руслан Якушев
Набор инструментов поисковой оптимизации IIS включает функцию Исключение роботов , которую вы можете использовать для управления содержимым файла Robots.txt для вашего веб-сайта, а также включает функцию Sitemaps и Sitemap Indexes , которую вы можете использовать для управления своими карты сайта.В этом пошаговом руководстве объясняется, как и зачем использовать эти функции.
Фон
Сканеры поисковых систем будут тратить на ваш веб-сайт ограниченное время и ресурсы. Поэтому очень важно сделать следующее:
- Запретить поисковым роботам индексировать содержимое, которое не является важным или которое не должно отображаться на страницах результатов поиска.
- Направьте поисковые роботы на контент, который вы считаете наиболее важным для индексации.
Для решения этих задач обычно используются два протокола: протокол исключения роботов и протокол Sitemaps.
Протокол исключения роботов используется для указания сканерам поисковых систем, какие URL-адреса НЕ следует запрашивать при сканировании веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта. Большинство поисковых роботов обычно ищут этот файл и следуют содержащимся в нем инструкциям.
Протокол Sitemaps используется для информирования сканеров поисковых систем об URL-адресах, доступных для сканирования на вашем веб-сайте. Кроме того, файлы Sitemap используются для предоставления некоторых дополнительных метаданных об URL-адресах сайта, таких как время последнего изменения, частота изменений, относительный приоритет и т. Д.Поисковые системы могут использовать эти метаданные при индексировании вашего веб-сайта.
Предварительные требования
1. Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам понадобится размещенный веб-сайт IIS 7 или более поздней версии или веб-приложение, которым вы управляете. Если у вас его нет, вы можете установить его из галереи веб-приложений Microsoft. В этом пошаговом руководстве мы будем использовать популярное приложение для ведения блогов DasBlog.
2. Анализ веб-сайта
Если у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как обычная поисковая система будет сканировать его содержимое.Для этого выполните действия, описанные в статьях «Использование анализа сайта для сканирования веб-сайта» и «Использование отчетов анализа сайта». Когда вы проведете свой анализ, вы, вероятно, заметите, что у вас есть определенные URL-адреса, которые доступны для сканирования поисковыми системами, но что нет никакой реальной пользы от их сканирования или индексации. Например, страницы входа или страницы ресурсов даже не должны запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Управление файлом Robots.txt
Вы можете использовать функцию исключения роботов IIS SEO Toolkit для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не должны сканироваться или индексироваться. Следующие шаги описывают, как использовать этот инструмент.
- Откройте консоль управления IIS, набрав INETMGR в меню «Пуск».
- Перейдите на свой веб-сайт, используя древовидное представление слева (например, веб-сайт по умолчанию).
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Добавить новое правило запрета » в разделе Исключение роботов .
Добавление запрещающих и разрешающих правил
Диалоговое окно «Добавить запрещающие правила» откроется автоматически:
Протокол исключения роботов
использует директивы «Разрешить» и «Запрещать», чтобы информировать поисковые системы о путях URL, которые можно сканировать, и тех, которые нельзя сканировать.Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Древовидное представление пути URL-адреса используется для выбора запрещенных URL-адресов. Вы можете выбрать один из нескольких вариантов при выборе путей URL с помощью раскрывающегося списка «Структура URL»:
- Физическое расположение - вы можете выбрать пути из физической структуры файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) - вы можете выбрать пути из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта IIS.
- <Запустить новый анализ сайта ...> - вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда пути URL.
После выполнения шагов, описанных в разделе предварительных требований, вам будет доступен анализ сайта. Выберите анализ в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо скрыть от поисковых систем, установив флажки в дереве «Пути URL-адресов»:
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите OK.Вы увидите новые запрещающие записи в главном окне функций:
Также будет обновлен файл Robots.txt для сайта (или создан, если он не существует). Его содержимое будет выглядеть примерно так:
Агент пользователя: * Запретить: /EditConfig.aspx Запретить: /EditService.asmx/ Запретить: / images / Запретить: /Login.aspx Запретить: / scripts / Запретить: /SyndicationService.asmx/ Чтобы увидеть, как работает Robots.txt, вернитесь к функции анализа сайта и повторно запустите анализ сайта.На странице «Сводка отчетов» в категории « ссылок » выберите « ссылок, заблокированных файлом Robots.txt ». В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
Управление файлами карты сайта
Вы можете использовать функцию Sitemaps и Sitemap Indexes IIS SEO Toolkit для создания карт сайта на своем веб-сайте, чтобы информировать поисковые системы о страницах, которые следует сканировать и проиндексировать.Для этого выполните следующие действия:
- Откройте диспетчер IIS, набрав INETMGR в меню Пуск .
- Перейдите на свой веб-сайт с помощью древовидной структуры слева.
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Создать новую карту сайта » в разделе «Карты сайта и индексы файлов Sitemap ».
- Диалоговое окно Добавить карту сайта откроется автоматически.
- Введите имя файла карты сайта и нажмите ОК . Откроется диалоговое окно Добавить URL-адреса .
Добавление URL в карту сайта
Диалоговое окно Добавить URL-адреса выглядит так:
Файл Sitemap представляет собой простой XML-файл, в котором перечислены URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Используйте диалоговое окно Добавить URL-адреса для добавления новых записей URL-адресов в XML-файл Sitemap.Каждый URL-адрес в карте сайта должен иметь полный формат URI (т.е. он должен включать префикс протокола и имя домена). Итак, первое, что вам нужно указать, - это домен, который будет использоваться для URL-адресов, которые вы собираетесь добавить в карту сайта.
Древовидное представление пути URL-адреса используется для выбора URL-адресов, которые следует добавить в карту сайта для индексации. Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
- Физическое расположение - вы можете выбрать URL-адреса из физического макета файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) - вы можете выбрать URL-адреса из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта.
- <Запустить новый анализ сайта ...> - вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда URL-пути, которые вы хотите добавить для индексации.
После того, как вы выполнили шаги, указанные в разделе предварительных требований, вам будет доступен анализ сайта.Выберите его из раскрывающегося списка, а затем проверьте URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры Частота изменения , Дата последнего изменения и Приоритет , а затем нажмите ОК , чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
http: // myblog / 2009/03/11 / Поздравляю, вы установилиDasBlogWithWebDeploy.aspx 2009-06-03T16: 05: 02 еженедельно 0,5 http: //myblog/2009/06/02/ASPNETAndURLRewriting.aspx 2009-06-03T16: 05: 01 еженедельно 0,5 Добавление местоположения карты сайта в Robots.txt файл
Теперь, когда вы создали карту сайта, вам нужно сообщить поисковым системам, где она расположена, чтобы они могли начать ее использовать. Самый простой способ сделать это - добавить URL-адрес карты сайта в файл Robots.txt.
В функции Sitemaps и Sitemap Indexes выберите только что созданную карту сайта, а затем щелкните Добавить в Robots.txt на панели Actions :
Ваш файл Robots.txt будет выглядеть примерно так:
Агент пользователя: * Запретить: / EditService.asmx / Запретить: / images / Запретить: / scripts / Запретить: /SyndicationService.asmx/ Запретить: /EditConfig.aspx Запретить: /Login.aspx Карта сайта: http: //myblog/sitemap.xml Регистрация карты сайта в поисковых системах
Помимо добавления местоположения карты сайта в файл Robots.txt, рекомендуется отправить URL-адрес карты сайта в основные поисковые системы. Это позволит вам получать полезный статус и статистику о вашем веб-сайте с помощью инструментов для веб-мастеров поисковой системы.
Сводка
В этом пошаговом руководстве вы узнали, как использовать функции исключения роботов, файлов Sitemap и Sitemap Indexes набора инструментов поисковой оптимизации IIS для управления файлами Robots.txt и Sitemap на вашем веб-сайте. IIS Search Engine Optimization Toolkit предоставляет интегрированный набор инструментов, которые работают вместе, чтобы помочь вам создать и проверить правильность файлов Robots.txt и карты сайта, прежде чем поисковые системы начнут их использовать.
.Объяснение и иллюстрация файла robots.txt
"Используйте файл robots.txt на своем веб-сервере.
- из руководства Google для веб-мастеров 1
Что такое файл robots.txt?
- Файл robots.txt - это простой текстовый файл, размещаемый на вашем веб-сервере, который сообщает веб-сканерам, таким как робот Googlebot, следует ли им обращаться к файлу или нет.
Базовые примеры robots.txt
Вот несколько распространенных роботов.txt (они будут подробно описаны ниже).
Блокировать одну папку
User-agent: *
Disallow: / folder /
Блок одного файла
User-agent: *
Disallow: /file.html
Зачем вам нужен файл robots.txt?
- Неправильное использование файла robots.txt может повредить вашему рейтингу
- Файл robots.txt управляет тем, как пауки поисковых систем видят ваши веб-страницы и взаимодействуют с ними.
- Этот файл упоминается в нескольких рекомендациях Google.
- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальной частью работы поисковых систем.
Совет: чтобы узнать, есть ли ваш robots.txt блокирует любые важные файлы, используемые Google, используйте инструмент рекомендаций Google.
Пауки поисковых систем
Первое, на что паук поисковой системы, такой как робот Googlebot, обращает внимание при посещении страницы, - это файл robots.txt.
Он делает это, потому что хочет знать, есть ли у него разрешение на доступ к этой странице или файлу. Если в файле robots.txt указано, что он может входить, паук поисковой системы переходит к файлам страниц.
Если у вас есть инструкции для робота поисковой системы, вы должны сообщить ему эти инструкции.Вы делаете это с помощью файла robots.txt. 2
Приоритеты вашего сайта
Есть три важных вещи, которые должен сделать любой веб-мастер, когда дело касается файла robots.txt.
- Определите, есть ли у вас файл robots.txt
- Если он у вас есть, убедитесь, что он не вредит вашему рейтингу и не блокирует контент, который вы не хотите блокировать
- Определите, нужен ли вам файл robots.txt
Определение наличия файла robots.txt
Вы можете ввести веб-сайт ниже, нажмите «Перейти», и он определит, есть ли на сайте файл robots.txt, и отобразит то, что написано в файле (результаты отображаются здесь, на этой странице) .
Если вы не хотите использовать вышеуказанный инструмент, вы можете проверить его в любом браузере. Файл robots.txt всегда находится в одном и том же месте на любом веб-сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
www.yourwebsite.com/robots.txt
Если у вас там есть файл, то это ваш файл robots.txt. Вы либо найдете файл со словами, либо найдете файл без слов, либо вообще не найдете файл.
Определите, блокирует ли ваш robots.txt важные файлы
Вы можете использовать инструмент рекомендаций Google, который предупредит вас, если вы блокируете определенные ресурсы страницы, которые необходимы Google для понимания ваших страниц.
Если у вас есть доступ и разрешение, вы можете использовать консоль поиска Google для тестирования своих роботов.txt файл. Инструкции для этого можно найти здесь (инструмент не общедоступен - требуется логин) .
Чтобы полностью понять, не блокирует ли ваш файл robots.txt что-либо, вы не хотите, чтобы он блокировал, вам необходимо понять, о чем он говорит. Мы рассмотрим это ниже.
Вам нужен файл robots.txt?
Возможно, вам даже не понадобится иметь файл robots.txt на вашем сайте. На самом деле, зачастую он вам не нужен.
Причины, по которым вы можете захотеть иметь robots.txt файл:
- У вас есть контент, который вы хотите заблокировать для поисковых систем
- Вы используете платные ссылки или рекламу, требующую специальных инструкций для роботов
- Вы хотите настроить доступ к своему сайту для надежных роботов
- Вы разрабатываете действующий сайт, но не хотите, чтобы поисковые системы еще индексировали его
- Они помогают следовать некоторым рекомендациям Google в определенных ситуациях.
- Вам нужно частично или полностью из вышеперечисленного, но у вас нет полного доступа к вашему веб-серверу и его настройке
Каждой из вышеперечисленных ситуаций можно управлять другими методами, но не с помощью robots.txt - хорошее центральное место для заботы о них, и у большинства веб-мастеров есть возможность и доступ, необходимые для создания и использования файла robots.txt.
Причины, по которым вы можете не иметь файл robots.txt:
- Просто и без ошибок
- У вас нет файлов, которые вы хотите заблокировать для поисковых систем.
- Вы не попали ни в одну из перечисленных выше причин, по которым у вас есть файл robots.txt.
Не иметь роботов - это нормально.txt файл.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как Googlebot, будут иметь полный доступ к вашему сайту. Это нормальный и простой метод, который очень распространен.
Как сделать файл robots.txt
Если вы умеете печатать или копировать и вставлять, вы также можете создать файл robots.txt.
Файл представляет собой просто текстовый файл, что означает, что вы можете использовать блокнот или любой другой текстовый редактор для его создания. Вы также можете сделать их в редакторе кода. Вы даже можете «скопировать и вставить» их.
Вместо того чтобы думать: «Я создаю файл robots.txt», просто подумайте: «Я пишу заметку», это в значительной степени один и тот же процесс.
Что должен сказать robots.txt?
Это зависит от того, что вы хотите.
Все инструкции robots.txt приводят к одному из следующих трех результатов
- Полное разрешение: все содержимое может сканироваться.
- Полное запрещение: сканирование контента невозможно.
- Условное разрешение: директивы в файле robots.txt определяют возможность сканирования определенного контента.
Давайте объясним каждый.
Полное разрешение - все содержимое можно сканировать
Большинство людей хотят, чтобы роботы посещали все на их веб-сайтах. Если это так, и вы хотите, чтобы робот индексировал во всех частях вашего сайта есть три варианта, чтобы роботы знали, что им рады.
1) Нет файла robots.txt
Если на вашем сайте нет файла robots.txt, вот что происходит ...
В гости приходит робот вроде Googlebot. Ищет файл robots.txt. Он не находит его, потому что его там нет. Затем робот чувствует бесплатно посещать все ваши веб-страницы и контент, потому что это то, на что он запрограммирован в данной ситуации.
2) Создайте пустой файл и назовите его robots.txt
Если на вашем веб-сайте есть файл robots.txt, в котором ничего нет, то вот что происходит ...
В гости приходит робот вроде Googlebot.Ищет файл robots.txt. Он находит файл и читает его. Читать нечего, поэтому После этого робот может свободно посещать все ваши веб-страницы и контент, потому что именно на это он запрограммирован в данной ситуации.
3) Создайте файл с именем robots.txt и напишите в нем следующие две строки ...
Если на вашем веб-сайте есть файл robots.txt с этими инструкциями, происходит следующее ...
В гости приходит робот вроде Googlebot. Он ищет роботов.txt файл. Он находит файл и читает его. Читает первую строку. Затем это читает вторую строку. Затем робот может свободно посещать все ваши веб-страницы и контент, потому что это то, что вы ему сказали (я объясню это ниже).
Полное запрещение - сканирование содержимого невозможно
Предупреждение. Это означает, что Google и другие поисковые системы не будут индексировать или отображать ваши веб-страницы.
Чтобы заблокировать доступ всех известных "пауков" поисковых систем к вашему сайту, в вашем файле robots.txt:
Не рекомендуется делать это, поскольку это не приведет к индексации ни одной из ваших веб-страниц.
Инструкции robot.txt и их значение
Вот объяснение того, что означают разные слова в файле robots.txt
Пользовательский агент
Часть «User-agent» предназначена для указания направления к конкретному роботу, если это необходимо. Есть два способа использовать это в ваш файл.
Если вы хотите сообщить всем роботам одно и то же, поставьте «*» после «User-agent». Это будет выглядеть так...
Вышеупомянутая строка говорит: «Эти указания применимы ко всем роботам».
Если вы хотите что-то сказать конкретному роботу (в этом примере роботу Google), это будет выглядеть так ...
В строке выше говорится, что «эти указания относятся только к роботу Googlebot».
Запрещено:
Часть «Запретить» предназначена для указания роботам, в какие папки им не следует смотреть. Это означает, что если, например, вы не хотите, чтобы поисковые системы индексировали фотографии на вашем сайте, вы можете поместить эти фотографии в одну папку и исключить ее.
Допустим, вы поместили все эти фотографии в папку под названием «фотографии». Теперь вы хотите запретить поисковым системам индексировать эту папку.
Вот как должен выглядеть ваш файл robots.txt в этом сценарии:
User-agent: *
Disallow: / photos
Две вышеуказанные строки текста в файле robots.txt не позволят роботам зайти в папку с фотографиями. "Пользовательский агент *" часть говорит, что «это относится ко всем роботам». В части «Запретить: / фотографии» указано «не посещать и не индексировать папку с моими фотографиями».
Инструкции для робота Googlebot
Робот, который Google использует для индексации своей поисковой системы, называется Googlebot. Он понимает еще несколько инструкций, чем другие роботы.
Помимо "Имя пользователя" и "Запретить" робот Googlebot также использует инструкцию Разрешить.
Разрешить
Инструкции «Разрешить:» позволяют сообщить роботу, что можно видеть файл в папке, которая была «Запрещена». по другим инструкциям. Чтобы проиллюстрировать это, давайте возьмем приведенный выше пример, когда робот не посещает и не индексирует ваши фотографии.Мы поместили все фотографии в одну папку под названием «фотографии» и создали файл robots.txt, который выглядел так ...
User-agent: *
Disallow: / photos
Теперь предположим, что в этой папке есть фотография с именем mycar.jpg, которую вы хотите проиндексировать роботом Googlebot. С Разрешить: инструкции, мы можем сказать Googlebot сделать это, это будет выглядеть так ...
User-agent: *
Disallow: / photos
Allow: /photos/mycar.jpg
Это сообщит роботу Googlebot, что он может посещать mycar.jpg "в папке с фотографиями, хотя в противном случае папка" фото " Исключенный.
Тестирование файла robots.txt
Чтобы узнать, заблокирована ли отдельная страница файлом robots.txt, вы можете использовать этот технический инструмент SEO, который сообщит вам, блокируются ли файлы, важные для Google, а также отобразит содержимое файла robots.txt.
Ключевые концепции
- Если вы используете файл robots.txt, убедитесь, что он используется правильно
- Неправильный robots.txt может заблокировать индексирование вашей страницы роботом Googlebot
- Убедитесь, что вы не блокируете страницы, необходимые Google для ранжирования ваших страниц.
Патрик Секстон
.
Узнайте, как оптимизировать файл Robots.txt
Итак, вы хотите стать рок-звездой robots.txt, а? Что ж, прежде чем вы сможете заставить этих пауков танцевать в вашем ритме, вам следует ознакомиться с несколькими основными принципами. Неправильно создав файл robots.txt, вы попадете в мир боли. Сделайте это правильно, и поисковые системы полюбят вас.

Что такое файл robots.txt?
Это «инструкция» для поисковых роботов (Google, Bing и т. Д.).) использовать при посещении вашего сайта.
Файл robots.txt указывает различным роботам / сканерам / паукам поисковых систем, где они могут и не могут заходить на ваш сайт. Вы сообщаете этим ботам (Google, Bing и т. Д.), Что им разрешено «видеть» на вашем веб-сайте, а что запрещено.
Ваш файл robots.txt - это полицейский на остановке, а машины - это веб-сканеры / пауки .
Имеет смысл? Хорошо.
Зачем мне нужен файл Robots.txt?
Роботы.txt - это то, что люди, как правило, поспешно собирают вместе. Может быть, это потому, что он имеет тенденцию быть одним из последних пунктов в списке запуска веб-сайта (не должно быть… но вы знаете….) Или, может быть, люди в целом просто ленивы. Вы ленивый веб-мастер? Надеюсь, что нет…
Что может пойти не так, если я не буду использовать этот файл Robots.txt?
Без файла robots.txt ваш веб-сайт будет :
- Не оптимизирован с точки зрения возможности сканирования
- Более подвержен ошибкам SEO
- Открыт для просмотра конфиденциальных данных
- Злоумышленникам проще взломать веб-сайт
- Пострадает от конкуренции
- Возникнут проблемы с индексацией
- Будет беспорядок, чтобы разобраться в инструментах для веб-мастеров
- Будет подавать запутанные сигналы поисковым системам
- и другие…
Давайте Начало: создание ваших роботов.txt
Минута № 1: у вас уже есть файл robots.txt?
Было бы неплохо определить, есть ли на вашем веб-сайте в настоящее время файл robots.txt для начала. Возможно, вы не захотите отменять что-либо, что есть в данный момент. Если вы не знаете, есть ли на вашем веб-сайте файл robots, просто зайдите на свой веб-сайт и укажите «robots.txt». Пример того, как это будет выглядеть:
www.mywebsite.com/robots.txt
Замените часть «mywebsite», конечно, на свое собственное доменное имя.
* Примечание : файл robots.txt всегда должен находиться на «корневом» или «домашнем» уровне вашего веб-сайта, то есть он должен находиться в той же папке, что и ваша домашняя страница или страница индекса.
Если вы ничего не видите при посещении этого URL-адреса, на вашем веб-сайте нет файла robots.txt. Однако, если вы ДЕЙСТВИТЕЛЬНО видите информацию, у вас ДЕЙСТВИТЕЛЬНО есть текущий файл robots. В этом случае, когда вы собираетесь редактировать или добавлять какие-либо правила (как показано ниже), не удаляйте все, что у вас есть в настоящее время, поскольку это может «испортить» ваш сайт.
На всякий случай сделайте резервную копию файла robots.txt перед тем, как приступить к его редактированию. Когда дело доходит до работы с цифровыми файлами, у меня есть для вас три слова: ВСЕГДА СОЗДАВАЙТЕ РЕЗЕРВНЫЕ КОПИИ
Минута №2: Запуск файла Robots.txt
Создать файл robots.txt так же просто, как встать с кровати. Ладно, мне трудно встать с постели, но я отвлекся.
Чтобы создать файл robots.txt, просто откройте любой текстовый редактор. Важно, чтобы вы не использовали программное обеспечение WYSIWYG (программное обеспечение для дизайна веб-страниц), поскольку эти инструменты могут добавлять дополнительный код, который нам не нужен.Сделайте это простым и используйте текстовый редактор. К наиболее распространенным относятся:
- Блокнот
- Блокнот ++
- Скобки
- TextWrangler
- TextMate
- Sublime Text
- Vim
- Atom
- и т. Д.
Подойдет любая из этих программ, так как ваш компьютер поставляется с Блокнот по умолчанию, вы также можете использовать его для этого урока.
Откройте Блокнот и начните вводить свои «правила». После того, как вы ввели свои правила, вы сохраняете файл, называя его «роботами», и убедитесь, что он сохранен с расширением «Текстовые документы (*.текст)".
Какие «правила» вы должны ввести в свой файл robots.txt? Это зависит от того, чего вы хотите достичь. Прежде чем вводить правила, вам необходимо решить, что вы хотите «заблокировать» или «скрыть» от сканирования на вашем веб-сайте. Папки на вашем веб-сайте, которые не нужно сканировать и индексировать в результатах поиска, включают в себя такие вещи, как:
- Страницы поиска по сайту
- Разделы оформления / электронной торговли
- Области входа пользователя
- Конфиденциальные данные
- Тестирование / Staging / Дубликаты данных
- и т. Д..
Имея эту информацию под рукой, легко настроить правила. Давайте посмотрим, как именно мы это делаем.
Понимание правил файла Robots.txt
Что касается файла robots.txt, существует стандартный формат для создания правил.
1) Звездочки используются как подстановочные знаки: *
2) Чтобы разрешить сканирование областей вашего веб-сайта, используется правило «Разрешить»
3) Чтобы запретить сканирование областей вашего веб-сайта, «Запретить» используется правило
Допустим, у вас есть веб-сайт (что, вероятно, у вас есть ??).На вашем веб-сайте (назовем его mywebsite.com) у вас была подпапка, содержащая дублирующуюся информацию / тестовые материалы / материалы, которые вы хотите сохранить в тайне. Возможно, вы настроили эту подпапку в качестве промежуточной или тестовой области. Назовем эту папку «постановкой». Ваш файл robots.txt будет выглядеть примерно так:
User-agent: *
Disallow: / staging /
Довольно просто, не правда ли? Давайте посмотрим, что здесь происходит.
Начнем с наших роботов.txt с User-agent: *
Определение User-agent обращается к паукам поисковых систем, а звездочка используется как подстановочный знак. Таким образом, это правило указывает ВСЕМ паукам из поисковых систем ВСЕ , что они должны следовать ВСЕМ правилам , которые должны появиться позже.
Так будет до тех пор, пока другое объявление User-agent не будет объявлено далее в robots.txt (если вам придется использовать его снова). Что будет потом?
Следующее правило:
Disallow: / staging /
Это правило запрета сообщает паукам поисковых систем, что им не разрешено сканировать что-либо на вашем веб-сайте, которое находится в промежуточной папке.Используя название нашего воображаемого веб-сайта, это местоположение будет выглядеть так: www.mywebsite.com/staging/
* Совет : имейте в виду, что только потому, что вы запрещаете сканирование определенного раздела вашего веб-сайта, оно может по-прежнему отображаться в индексе поисковых систем IF ранее сканировалось И , если вы разрешили индексирование этих страниц .
Чтобы этого не произошло, лучше всего объединить правило запрета с метатегами noindex, добавляемыми на ваши веб-страницы (подробнее об этом ниже).Если страницы, которые вы не хотите сканировать, уже отображаются в индексе поисковой системы, возможно, вам придется удалить их вручную с помощью области инструментов для веб-мастеров соответствующих поисковых систем (Google / Bing).
Все просто, не правда ли?
Несколько примеров, которые вы можете использовать
Ниже вы видите несколько примеров из файла robots.txt, показывающих различные правила для разных ситуаций. Не все файлы robots.txt будут одинаковыми. Некоторые люди могут захотеть заблокировать сканирование всего своего веб-сайта.У других может быть потребность ограничить только определенные разделы своего веб-сайта.
Разрешение сканирования и индексации всего на веб-сайте
Агент пользователя: *
Разрешить: /
Блокировка всего веб-сайта от сканирования
Агент пользователя: *
Disallow: /
Блокировка определенной папки от сканирования
User-agent: *
Allow: / myfolder /
Allow A Specific Robot (Allow A Specific in Spider / в данном случае Google) для доступа к вашему сайту и запрета всем остальным
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
Extra: Роботы, специфичные для WordPress.txt File
Что касается WordPress, то при каждой установке WP есть три основных стандартных каталога. Это:
- wp-content
- wp-admin
- wp-includes
Папка wp-content содержит подпапку, известную как «загрузки». Это место содержит медиа-файлы, которые вы используете (изображения и т. Д.), И мы НЕ должны блокировать этот раздел. Зачем вам это нужно?
Ну, когда вы «запрещаете» папку в robots.txt, по умолчанию - все подпапки под ней также блокируются по умолчанию.Итак, мы должны создать уникальное правило для этой подпапки мультимедиа.
Ваш файл robots.txt WordPress теперь может выглядеть примерно так:
User-agent: *
Disallow: / wp-admin /
Disallow: / wp-includes /
Запретить: / wp-content / plugins /
Запретить: / wp-content / themes /
Разрешить: / wp-content / uploads /
Теперь у нас есть очень простой файл robots.txt, который блокирует выбранные нами папки, но по-прежнему позволяет сканировать подпапку «uploads» внутри «wp-content». Есть смысл?
Если вы запрещаете папку «xyz», каждая папка, находящаяся под / помещенная внутри «xyz», также будет запрещена. Чтобы указать отдельные папки, которые следует сканировать, необходимо указать явное правило.
Вот что вы можете использовать для запуска файла robots.txt WordPress. Странный шар в этой группе, которого вы, возможно, не видели раньше, - это «Disallow: / 20 *». Это отключает архивы дат, начиная с 20 года.
User-agent: *
Disallow: / wp-admin /
Disallow: / wp-includes /
Disallow: / wp-content / plugins /
Disallow: / wp- content / cache /
Disallow: / wp-content / themes /
Disallow: /xmlrpc.php
Disallow: / wp-
Disallow: / feed /
Disallow: / trackback /
Disallow: * / feed /
Disallow: * / trackback /
Disallow: / *?
Disallow: / cgi-bin /
Disallow: / wp-login /
Disallow: / wp-register /
Disallow: / 20 *Разрешить: / wp-content / uploads /
Карта сайта: http: // example.com / sitemap.xml
* Совет : всегда рекомендуется включать ссылку на карту сайта из файла robots.txt. Карта сайта также должна быть размещена в «корне» вашего веб-сайта (в той же папке, что и файл домашней страницы).
Минута № 3: осторожное предупреждение / проверка на наличие ошибок
Вы должны убедиться, что вы не сделали никаких опечаток. Простая опечатка может испортить ваш файл, поэтому убедитесь, что вы написали все правильно и используете правильный интервал.
Также важно отметить, что не все пауки / сканеры следуют стандартному протоколу robots.txt. Вредоносные пользователи и спам-боты будут просматривать ваш файл robots.txt и искать конфиденциальную информацию, такую как личные разделы, папки с конфиденциальными данными, административные области и т. Д. Хотя многие люди ДОЛЖНЫ перечислять эти папки / области своего веб-сайта в файле robots.txt (и это нормально в 99% случаев), чтобы сделать дополнительный шаг вперед, вы можете не помещать их в файл robots.txt и просто скрыть их с помощью метатега robots.
Итак, если вы хотите быть в большей безопасности и использовать блокировку своих конфиденциальных страниц с помощью метатегов, вот как вы это делаете:
- Откройте программу редактирования веб-сайта (что бы вы ни использовали для разработки / редактирования настоящего веб-сайта)
- Используя «представление кода» или «представление текста» вашего программного обеспечения для редактирования, вы должны ввести следующий код между тегами «заголовок» страницы (верхняя часть страницы).
При просмотре исходного кода вашей страницы он должен выглядеть примерно так:
…
… и именно так вы легко блокируете свои страницы от индексации и сканирования!
Минута №4: Загрузка на ваш веб-сайт
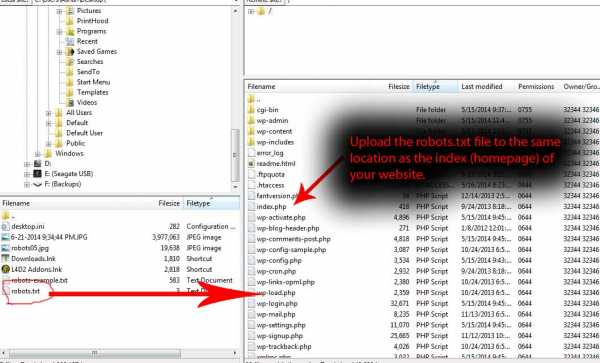
Конечно, ничего из этого не будет служить никакой цели, если вы не загрузите и не сохраните файл обратно на свой веб-сайт.Поэтому обязательно сохраните файл роботов как robots.txt, и если вы также решили использовать опцию метатега, обязательно повторно загрузите эти веб-страницы после того, как вы их отредактировали и сохранили.
Минута № 5: Просмотр файла в Интернете

Последним шагом в этом простом процессе является просмотр файла robots.txt в вашем веб-браузере, а также проверка того, что ваши недавно сохраненные страницы (если вы использовали метатег ) также обновляются. На всякий случай обновите страницу или очистите кеш и файлы cookie на своем компьютере, прежде чем делать это.
Полезный ресурс:
Хороший список имен пользовательских агентов веб-сканера можно найти на сайте: http://www.robotstxt.org/db.html. Здесь вы можете найти любое «имя» сканера и добавить его в свой список разрешенных / запрещенных… большинству людей это не понадобится.
Заключение и заключительные мысли
Итак, теперь у вас есть сила и знания, чтобы эффективно создавать и оптимизировать файл robots.txt для вашего веб-сайта - это здорово! Однако есть еще много чего узнать. Роботы.txt - это только один из сотен элементов, которые мы ежедневно используем для наших клиентов и стараемся опережать их.
Если вы хотите, чтобы мы проанализировали оптимизацию вашего веб-сайта и резко повысили рейтинг вашего сайта, обязательно свяжитесь с нами, чтобы получить бесплатную 25-минутную маркетинговую оценку. Мы всегда рады помочь!
Есть вопросы? Обязательно оставьте свой комментарий ниже, и я свяжусь с вами как молния.