Как отобразить xml файл на html странице
Визуализация Xml-документов / Хабр
Думаю, для многих не секрет, что xml является достаточно удобным способом хранения и передачи информации. Вот уже который раз натыкаюсь в литературе на утверждение, что в будущем xml должен заменить html, а появление xhtml является тому подтверждением. Но тут есть нюанс. все браузеры знают как отображать html-документы, но ни один из них не знает, как должны отображаться xml-документы. Это связано прежде всего с тем, что формируя xml-документ Вы можете ввести свои теги. Я хочу коротко (это очень большая тема, на самом деле) рассказать о так называемых «Таблицах преобразований xml-документов».
Думаю, что многие наверняка знакомы с ними, но надеюсь что кому-то это может быть полезно, а, учитывая мою любовь к практике, хочу показать всё на очень простом примере
Что мы имеем
Рассмотрим простенький xml-документ:
- <?xml version="1.0" encoding="utf-8"?>
- <document>
- <header>Это заголовок Xml-документа</header>
- <items>
- <item>
- <name>Habrahabr.ru</name>
- <description>
- В Хабрахабр заложена модель совместного творчества людей. Это
- универсальное средство для всех представителей нового поколения
- средств массовой информации.
- </description>
- </item>
- <item>
- <name>Bash.org.ru</name>
- <description>
- Вы добавляете цитату. После этого цитата попадает в Бездну, где
- ее могут увидеть и проголосовать за нее наши посетители, читающие
- сей суровый раздел.
- </description>
- </item>
- </items>
- </document>
Если мы попробуем просмотреть его в браузере, то увидим нечто подобное: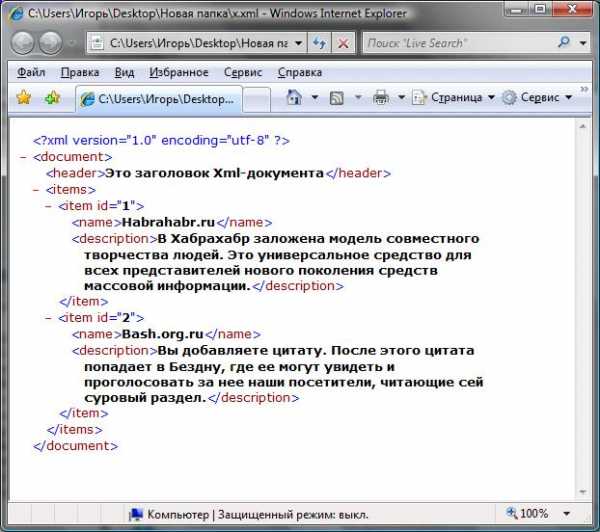
Существует несколько способов визуализировать содержимое этого документа.
К нему можно подключить обычную таблицу стилей (css-файл) или таблицу преобразований.
Таблица преобразований представляет из себя xml-документ, оформленный по определённым правилам и имеющий расширение .xslt.
Допустим нам нужно отобразить информацию, содержащуюся в xml-документе, для этого создадим таблицу преобразований (файл будет называться style.xslt):
- <?xml version="1.0" encoding="utf-8"?>
- <xsl:stylesheet version="1.0"
- xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
- xmlns:msxsl="urn:schemas-microsoft-com:xslt"
- exclude-result-prefixes="msxsl">
-
- <xsl:template match="document">
- <html>
- <head><title><xsl:value-of select="header" /></title></head>
- <body><xsl:apply-templates select="items" /></body>
- </html>
- </xsl:template>
-
- <xsl:template match="items">
- <ul><xsl:apply-templates select="item" /></ul>
- </xsl:template>
-
- <xsl:template match="item">
- <li><a>
- <xsl:attribute name="href">
- http:// <xsl:value-of select="name"/>
- </xsl:attribute>
- <xsl:value-of select="name"/>
- </a> - <xsl:value-of select="description"/>
- <li> </xsl:template>
-
- </xsl:stylesheet>
Подключить таблицу преобразований (к исходному xml-документу конечно же) можно следующим образом:
В итоге, открыв тот же самый файл в браузере мы увидим следующее: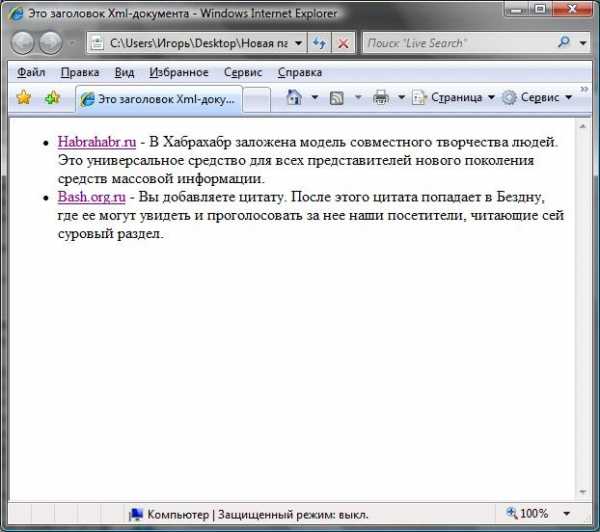
В двух словах, как это работает
В таблице преобразований описаны три шаблона: document, items и item. Когда в шаблоне встречается элемент xsl:apply-templates на его место подставляются то, что получится в результате обработки всех элементов, удовлетворяющих выражению select (я указывал просто названия тегов, хотя там могут быть достаточно сложные конструкции). Аналогично вставляются значения тегов (тег xsl:value-of) и атрибуты для тегов (тег xsl:attribute).
Шаблон document формирует основу html-страницы (теги html, head, body), а в них подставляются заголовок страницы и список элементов, формирующийся по шаблону items (Элементы списка формируются по шаблону items).
Всё преобразование делается на стороне клиента.
Это лишь малая доля того, что может предоставить технология таблиц преобразований. Visual Studio имеет удобный интерфейс по работе с ними, в том числе просмотр сгенерированного html.
НОУ ИНТУИТ | Лекция | Отображение XML-документов с использованием связывания данных
Аннотация: В этой лекции вы получите сведения о двух основных шагах при связывании данных. Также узнаете в подробностях, как привязать XML-документ к HTML-странице, как сцеплять элементы HTML с элементами XML, и как программировать Web-страницу с помощью сценариев, которые используют в качестве базового объекта программирования связанные данные.
Связывание данных является первым из методов отображения XML-документа с традиционной HTML-страницы, с которым вы познакомитесь. Отображение XML с HTML-страниц дает вам возможность воспользоваться как преимуществами хранения данных в XML-документе, с его гибким синтаксисом для структурирования данных и маркировки каждого фрагмента информации, так и имеющееся богатство форматирования и динамическое программирование HTML.
При связывании данных вы соединяете XML-документ с HTML-страницей, а затем встраиваете стандартные HTML-элементы, такие как SPAN или TABLE, в отдельные XML-элементы. HTML-элементы затем автоматически отображают содержимое XML-элементов, в которые они встроены.
Связывание данных, как и другие методы, о которых вы узнаете в этой лекции, работает только с XML-документом, который симметрично структурирован, например, как базы данных, – а именно, элементы документа могут быть интерпретированы как набор записей и полей. В простейшем случае такой документ состоит из корневого элемента, содержащего множество элементов одинакового типа (записи), каждый из которых имеет одинаковый набор дочерних элементов, все из которых содержат символьные данные (поля). В качестве примера можно привести документ Inventory.xml, который представлен в Листинге 8.1. Элементы BOOK этого документа могут быть интерпретированы как записи, а элементы, вложенные в каждый элемент BOOK ( TITLE, AUTHOR и т.д.), могут быть интерпретированы как поля. Далее в этой лекции вы подробнее узнаете о специфических структурах документа, которые подходят для связывания данных. Если структура документа такова, что не допускает связывание данных, можно использовать метод создания сценариев, о котором пойдет речь в "Отображение XML-документов с использованием сценариев объектной модели документа" .
В этой лекции вы прежде всего получите сведения о двух основных шагах при связывании данных. Затем вы узнаете в подробностях, как привязать XML-документ к HTML-странице (первый основной шаг) и как сцеплять элементы HTML с элементами XML (второй основной шаг). Наконец, вы узнаете, как программировать Web-страницу с помощью сценариев, которые используют в качестве базового объекта программирования связанные данные (а именно, Data Source Object, или DSO). Вы можете применять эти сценарии совместно со связыванием данных – либо независимо.
В "Отображение XML-документов с использованием сценариев объектной модели документа" вы познакомитесь с совершенно иным способом организации доступа управления и отображения XML-документа с HTML-страницы. Этот метод вы можете использовать для XML-документов любого типа, независимо от вида его логической структуры.
Ссылка. Для получения более подробной информации о связывании данных и объекте DSO, который лежит в основе этого метода, обратитесь к Web-странице Microsoft Developer Network (MSDN) по адресу: http://msdn.microsoft.com/xml/xmlguide/xmldso.asp.
Основные шаги
Вот два основных этапа при связывании данных:
- Установка связи XML-документа с HTML-страницей, на которой вы хотите отобразить данные XML. Этот шаг обычно реализуется включением HTML-элемента с именем XML в HTML-страницу. Например, следующий элемент на HTML-странице связывает XML-документ Book.xml со страницей:
<XML SRC="Book.xml"></XML>
- Сцепление HTML-элементов с XML-элементами.Когда вы сцепляете HTML-элементы с XML-элементом, HTML-элемент автоматически отображает содержимое XML-элемента. Например, следующий элемент SPAN на HTML-странице сцеплен с элементом AUTHOR связанного XML-документа:
<SPAN DATASRC="#dsoBook" DATAFLD="AUTHOR"></SPAN>
В результате HTML-элемент SPAN отображает содержимое XML-элемента AUTHOR.
Базовая технология связывания данных в действительности столь же проста, как в этом примере, хотя в дальнейшем вы познакомитесь с различными вариациями и способами использования этой технологии.
Шаг первый: установка связи XML-документа с HTML-страницей
Чтобы отобразить XML-документ на HTML-странице, вы должны установить его связь со страницей. Самый простой путь сделать это в Microsoft Internet Explorer 5 – включить в страницу HTML-элемент с именем XML, так называемый фрагмент данных. Вы можете использовать одну из двух различных форм записи для фрагмента данных.
В первой форме весь текст XML-документа помещается между начальным и конечным тегами XML. Вот пример фрагмента данных на следующей HTML-странице:
<HTML> <HEAD> <TITLE>Book Description</TITLE> </HEAD> <BODY> <XML> <?xml version="1.0" encoding="windows-1251" ?> <BOOK> <TITLE>The Adventures of Huckleberry Finn</TITLE> <AUTHOR>Mark Twain</AUTHOR> <BINDING>mass market paperback</BINDING> <PAGES>298</PAGES> <PRICE>$5.49</PRICE> </BOOK> </XML> <!-- другие элементы HTML … --> </BODY> </HTML>
Во второй форме записи HTML-элемент с именем XML остается пустым и содержит только URL XML-документа. Вот пример фрагмента данных на HTML-странице:
<HTML> <HEAD> <TITLE>Book Description</TITLE> </HEAD> <BODY> <XML SRC="Book.xml"></XML> <!-- другие элементы HTML … --> </BODY> </HTML>
В предыдущем примере текст XML-документа должен содержаться в отдельном файле Book.xml:
<?xml version="1.0" encoding="windows-1251" ?> <!-- Имя файла: Book.xml --> <BOOK> <TITLE>The Adventures of Huckleberry Finn</TITLE> <AUTHOR>Mark Twain</AUTHOR> <BINDING>mass market paperback</BINDING> <PAGES>298</PAGES> <PRICE>$5.49</PRICE> </BOOK>
Вторая форма более соответствует основам философии XML, согласно которой собственно данные (XML-документ) хранятся отдельно от информации по их форматированию и обработке (таблицы стилей или, в данном случае, HTML-страницы). Вторая форма облегчает работу с XML-документом, особенно если один документ отображается на нескольких различных HTML-страницах. В рассматриваемых в этом курсе примерах вы будете иметь дело только со второй формой.
Примечание. Имейте в виду, что элемент с именем XML, используемый для создания фрагмента данных, не является собственно XML-элементом. Это просто HTML-элемент, который содержит XML-элементы. Следовательно, использование синтаксиса XML для пустого элемента, <XML SRC="Book.xml" />, недопустимо.
Вы должны присвоить атрибуту ID фрагмента данных уникальный идентификатор, который используете для доступа к XML-документу с HTML-страницы. (В предыдущем примере в качестве значения для ID выступает "dsoBook".)
При второй форме записи фрагмента данных вы присваиваете атрибуту SRC URL файла, содержащего данные XML. Вы можете использовать полный URL, как в следующем примере:
<XML SRC="http://www.my_domain.com/documents/Book.xml"> </XML>
Чаще, однако, вы используете частичный URL, который задает местонахождение относительно местонахождения HTML-страницы, содержащей фрагмент данных. Например, атрибут SRC в следующем фрагменте данных указывает, что файл Book.xml находится в той же папке, что и HTML-страница:
<XML SRC="Book.xml"></XML>
Относительные URL более распространены, потому что XML-документ обычно содержится в той же папке, что и HTML-страница, либо в одной из вложенных папок.
Просмотр XML файлов
XML файл можно просматривать во всех основных браузерах. Однако не стоить ждать, что он будет отображаться, как HTML.
Просмотр XML файлов
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Напоминание</heading> <body>Не забудь обо мне в эти выходные!</body> </note>
Посмотрите этот XML файл: note.xml.
XML документ будет отображен с подкрашенными корневым и дочерними элементами. На знак плюс (+) или минус (-) слева от элементов можно нажать, и тогда структура элемента развернется или наоборот свернется. Чтобы просмотреть исходный код XML файла (без знаков + и - ), выберите пункт меню браузера "Исходный код".
Замечание: В браузерах Safari отображается только текст элемента. Чтобы просмотреть код XML документа, необходимо кликнуть правой кнопкой мыши на страницу и выбрать "Просмотреть исходный код".
Просмотр поврежденного XML файла
Если попытаться открыть некорректно составленный XML файл, то некоторые браузеры выдадут сообщение об ошибке, некоторые некорректно его отобразят.
Попробуйте открыть следующий XML файл в браузерах Chrome, IE, Firefox, Opera и Safari : note_error.xml.
Другие примеры XML
Просмотр следующих XML документов поможет вам освоиться с выводом XML.
XML каталог компакт-дисков (cd_catalog.xml)
Коллекция CD, сохраненная в виде XML данных.
XML каталог растений (plant_catalog.xml)
Каталог растений из магазина растений, сохраненный в виде XML данных.
Простое меню (simple.xml)
Меню завтрака из ресторана, сохраненное в виде XML данных.
Почему XML отображается таким образом?
XML документы не несут никакой информации о том, каким образом нужно отображать их данные.
В связи с тем, что теги XML "придуманы" автором XML документа, браузеры не знают, что описыва
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML. XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Содержание
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>
И разберемся, что означает эта запись.
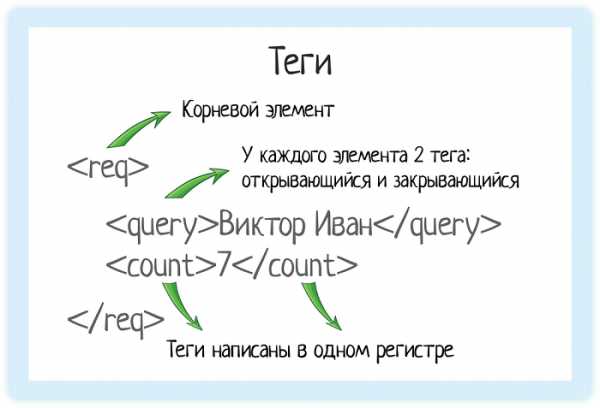
Теги
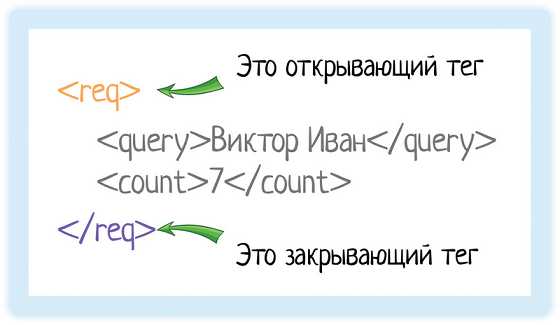
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки: <tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!

Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».

Он мог бы называться по другому:
<main>
<sugg>
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.Значение элемента
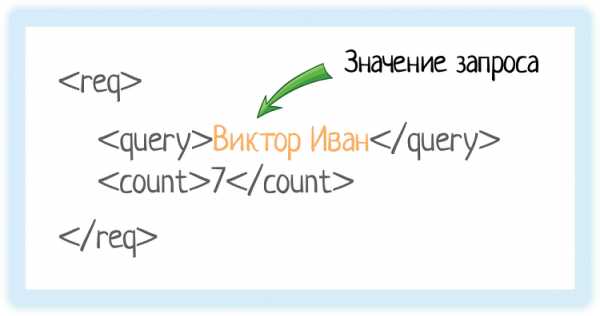
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.

Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
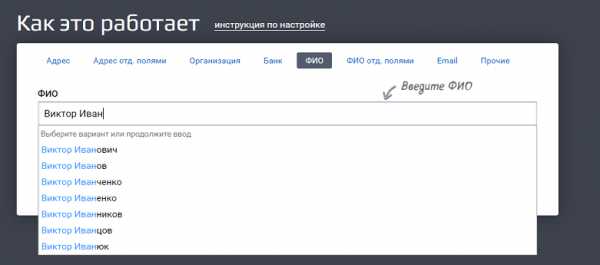
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
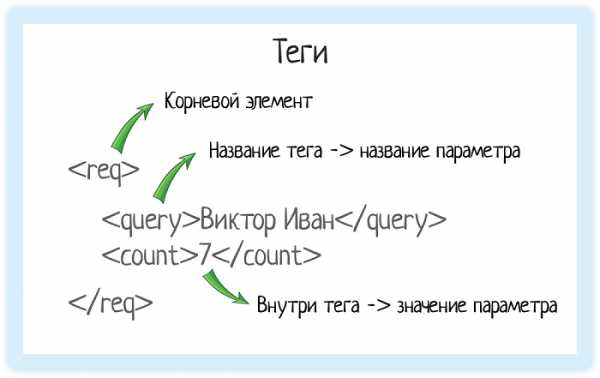
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.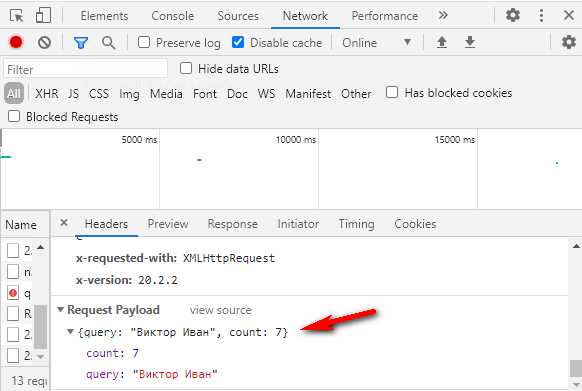
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:- Виктор Иван — строка
- 7 — число
Но оба значения идут без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виденазвание_атрибута = «значение атрибута»
Например:<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>

Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:<party type="PHYSICAL" sourceSystem="AL" rawId="2"> <field name=“name">Олег </field> <field name="birthdate">02.01.1980</field> <attribute type="PHONE" rawId="AL.2.PH.1"> <field name="type">MOBILE</field> <field name="number">+7 916 1234567</field> </attribute> </party>
Давайте разберем эту запись. У нас есть основной элемент party. 
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!

Внутри party есть элементы field.

У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.

Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.

У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл...
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?

Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:<?xml version="1.0" encoding="UTF-8"?>
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- ...
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.

Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!

А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:<xs:element name="doRegister "> <xs:complexType> <xs:sequence> <xs:element name="email" type="xs:string"/> <xs:element name="name" type="xs:string"/> <xs:element name="password" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>
А в WSDl сервиса она записана еще проще:<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:<xsd:complexType name="Test"> <xsd:sequence> <xsd:element name="value" type="xsd:string"/> <xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/> <xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/> <xsd:element name="user" type="USER" minOccurs="0"/> </xsd:sequence> </xsd:complexType>
А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач. См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация! Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:<req> <query>Ан</query> <count>7</count> </req>
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:<req> <query>Ан</query> <gender>FEMALE</gender> </req>
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>
Это тоже самое, что передать в нем пустое значение<name></name>
Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.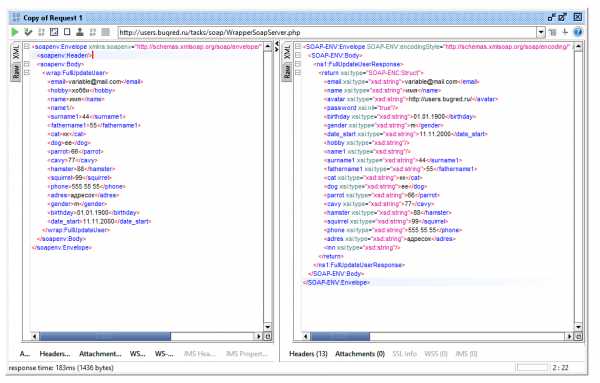
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом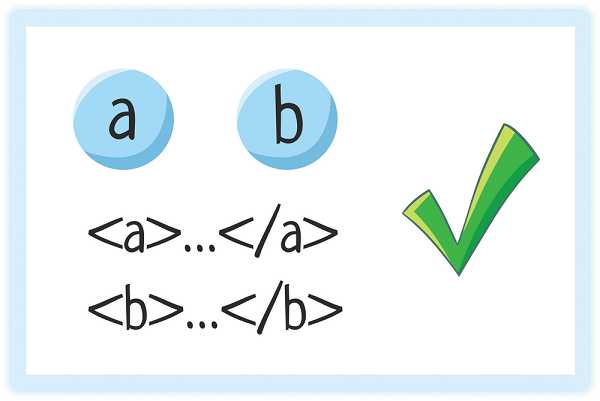
Один элемент может быть вложен в другой

Но накладываться друг на друга элементы НЕ могут!
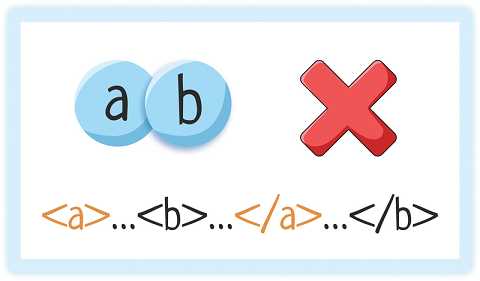
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON. Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
XML сайты в результатах поиска / Хабр
Что такое XML сайт
XML сайт это сайт, страницы которого являются простыми XML файлами с MIME типом "text/xml" "application/xml"(XML Media Types). Они содержат только уникальные данные для этой страницы.
В таком XML файле задаётся ссылка на XSLT шаблон, который преобразует XML в HTML или в XHTML в браузере пользователя.
Проблема
Для классических html веб страниц поисковики в качестве заголовка отображают содержимое тега title. В описании отображается кусочки текста с найденными ключевыми словами или содержимое тега meta description.
Поисковики обычно не исполняют скрипты на страницах которые индексируют и соответственно не видят конечный вариант страницы после их исполнения. Соответственно они не видят теги title и meta которые вставляются XSLT шаблоном. Они индексируют текст который есть в XML документе как есть.
Решение
Наша задача правильно добавить теги title и meta в XML чтобы браузер, поисковик и меседжер в котором отправляется ссылка на страницу их понимали.
Таким же образом можно будет добавить и другие HTML теги для поисковиков, меседжеров и даже браузера если он вдруг не исполнит XSLT шаблон.
Как страница отображается без тегов
Например у нас такой XML:
<запись> <заголовок>Текст заголовка</заголовок> <текст>Текст записи</текст> </запись>
Как он отображается в поиске без title и meta тегов:
- XML показывается в одну строку (Гугл)
Заголовок: <запись><заголовок>Текст заголовка</заголовок><текст>...
Описание: <запись><заголовок>Текст заголовка</заголовок><текст>Текст записи</текст></запись>
- Сокращённый вариант (duckduckgo.com)
Заголовок: example.com
Описание: запись>заголовок>Текст заголовка...
- Только содержимое тегов в загаловке (startpage.com)
Заголовок: Текст заголовка Текст записи
- Страница не отображается в поиске (Яндекс)
Я запускал несколько раз переиндексацию страницы но яндексу упорно не нравился mime тип страницы. Потом когда я начал писать эту статью они мне прислали увидомление что добавили в поиск. Но сегодня страница снова исчезла из поиска.
Вставляем теги
Для того чтобы вставить теги title и meta в xml и при этом браузер и поисковик понимали что это html теги им надо задать пространство имён "http://www.w3.org/1999/xhtml".
Варианты вставки:
Задать префикс для html тегов.
<!-- родительском элементе объявляем префикс 'xh' для xhtml элементов --> <запись xmlns:xh="http://www.w3.org/1999/xhtml"> <!-- далее используем этот префикс перед именем элемента --> <xh:title>Текст заголовка для страницы поиска и меседжеров</xh:title> <xh:meta name ="description" content="Часть текста записи для страницы поиска и меседжеров"/> <!-- у элементов без префикса пространство имён остаётся пустым --> <заголовок>Текст заголовка</заголовок> <текст>Текст записи</текст> </запись>
Этот вариант самый краткий но выяснилось что Гугл его не понимает.
UPD (04.08.2020): Похоже Гугл таки понял данный вариант но задал пока только заголовок.
UPD (26.08.2020): Яндекс применил тестовым XML страницам с <!DOCTYPE html> шаблон и взял заголовок и описание из результата. Тестовые страницы появились в результатах поиска Яндекса.
Обернуть в элемент с заданным пространством имён поумолчанию.
<запись> <!-- в теге head определяем пространство имён поумолчанию --> <head xmlns="http://www.w3.org/1999/xhtml"> <!-- все дочерние элементы наследуют это пространство имён --> <title>Текст заголовка</title> <meta name="description" content="Часть текста записи для страницы поиска и меседжеров"/> </head> <!-- элементы вне тега head остаются с пустым пространством имён --> <заголовок>Текст заголовка</заголовок> <текст>Текст записи</текст> </запись>
Тут пространство имён поумолчанию задаётся в родительском элементе и распространяется на дочерние.
Гугл понял такой вариант и использовал текст из title в качестве заголовка и текст из meta description в качестве описания страницы.
UPD (04.08.2020): В этом варианте на тестовых страницах Гугл задал заголовок и описание после применения XSLT шаблона.
UPD (20.08.2020): После добавления <!DOCTYPE html> на тестовых страницах Яндекс взял информацию из title и meta description но посчитал страницу не достаточно качественной.
С этим вариантом возникает проблема на web.archive.org. Архив в данном виде воспринимает страницу как html и пихает в неё свои теги "поправляя" те теги которых не знает. В результате документ перестаёт быть правильным XML и не отображается.
Пример работы web.archive.org над этим вариантом.
<запись> <head xmlns="http://www.w3.org/1999/xhtml"><script ...</script> <title>Текст заголовка</title> <meta name="description" content="Часть текста записи для страницы поиска и меседжеров"/> </head> <заголовок>Текст заголовка</заголовок> <текст>Текст записи</текст> </запись>
Задать пространство имён поумолчанию каждому элементу индивидуально.
<запись> <!-- задаём пространство имён каждому элементу индивидуально --> <title xmlns="http://www.w3.org/1999/xhtml">Текст заголовка</title> <meta name="description" content="Часть текста записи для страницы поиска и меседжеров" xmlns="http://www.w3.org/1999/xhtml"/> <!-- остальные элементы остаются с пустым пространством имён --> <заголовок>Текст заголовка</заголовок> <текст>Текст записи</текст> </запись>
Данный способ хорош когда нам нужен только один элемент из этого пространства имён и мы можем указать его пространство имён прям в нём.
Этот вариант я только поставил на тест так что результат отображения в Гугле не известен.
UPD (27.07.2020): На живом сайте в таком варианте Гугл подхватил заголовок. Описание осталось пустым. Я решил попробовать переместить xmlns в конец meta тега чтобы он больше был похож на обычный html. Ждём следующей переиндексации.
UPD (04.08.2020): На тестовых страницах Гугл задал заголовок до применения XSLT шаблона а описание после его применения.
UPD (10.08.2020): На живом сайте в этом варианте Бинг корректно отображает заголовок и описание.
UPD (20.08.2020): После добавления <!DOCTYPE html> на тестовых страницах Яндекс взял информацию из title и meta description но посчитал страницу не достаточно качественной. На живом сайте он также задал название и описание страницы и отобразил страницу в поиске.
UPD (26.08.2020): Яндекс применил тестовым XML страницам с <!DOCTYPE html> шаблон и взял заголовок и описание из результата. Тестовые страницы появились в результатах поиска Яндекса.
Шаблон
После проведения всех экспериментов итоговый шаблон XML у меня такой:
<?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet href="style.css" type="text/css" ?> <?xml-stylesheet href="style.xsl" type="text/xsl" ?> <!DOCTYPE html> <корень> <title xmlns="http://www.w3.org/1999/xhtml">[Заголовок страницы]</title> <meta name="description" content="[Описание страницы]" xmlns="http://www.w3.org/1999/xhtml" /> <meta name="keywords" content="[ключевые слова]" xmlns="http://www.w3.org/1999/xhtml" /> <!-- содержимое XML документа --> </корень>
Отдаётся документ с MIME типом "application/xhtml+xml" для Гугла и директивой <!DOCTYPE html> для Яндекса чтоб они исполнили XSLT шаблон на странице.
Результат
После правильной вставки тегов title и meta в результатах поиска после переиндексации страницы она появляется уже с заданным заголовком и описанием. Также после отправки ссылки на сайт в сообщении подгружается её заголовок и описание.
Ссылки
Страница с ссылками на примеры: ivan386.github.io/xml-site-index-test/
Примеры я создал сегодня(10.07.2020). Надо подождать пока поисковики их проиндексируют.
UPD (27.07.2020): На данный момент только Бинг показывает одну из XML в результатах поиска. Это первый вариант XML и Бинг также как и Гугл не увидел в ней заголовка и описания. Возможно поскольку мало текста в самих XML документах поисковики неохотно их показывают и они задержались в песочнице.
UPD (04.08.2020): Гугл наконец то показал некоторые тестовые страницы в поиске. Я за это время их сделал много. На некоторых он даже применил XSLT шаблон и взял заголовок и описание после применения.
UPD (20.08.2020): После добавления тестовым XML страницам <!DOCTYPE html> Яндекс прочитал на некоторых заголовок и описание но решил не отображать их в поиске так как посчитал их не качественными. При тестировании этого метода на живом сайте он таки появился в поиске Яндекса с правильным названием и описанием.
UPD (26.08.2020): Яндекс применил тестовым XML страницам с <!DOCTYPE html> шаблон и взял заголовок и описание из результата. Тестовые страницы появились в результатах поиска Яндекса.
Эти страницы в Гугле: site:ivan386.github.io/xml-site-index-test/
Эти страницы в Яндексе: site:ivan386.github.io/xml-site-index-test/
Эти страницы в Бинг: site:ivan386.github.io/xml-site-index-test/
Эти страницы в DuckDuckGo: site:ivan386.github.io/xml-site-index-test/
Отображение XML с помощью CSS
Geeks_for_Geeks
{
font-size:80%;
margin:0.5em;
font-family: Verdana;
display:block;
}
geeks_section {
display:block;
border: 1px solid silver;
margin:0.5em;
padding:0.5em;
background-color:whitesmoke;
}
title {
display:block;
font-weight:bolder;
text-align:center;
font-size:30px;
background-color: green;
color: white;
}
name, topic1, topic2, topic3, topic4 {
display:block;
text-align:center;
}
name {
color:green;
text-decoration: underline ;
font-weight:bolder;
font-size:20px;
}
topic1 {
color:green
}
topic2 {
color:brown
}
topic3 {
color:blue
}
topic4 {
color:orange
}
javascript - как отобразить XML-файл на HTML-странице с помощью Ajax?
Переполнение стека - Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
. Как отображать XML с помощью JavaScript на странице HTML5
-
- Веб-дизайн и разработка
- HTML
- Как отображать XML с помощью JavaScript на странице HTML5
Автор: Джон Пол Мюллер
XML - отличный способ хранить данные с помощью JavaScript. Однако это не самый простой способ просмотреть данные. Все теги, как правило, скрывают данные, а не упрощают понимание. В сгенерированном XML-файле обычно отсутствуют пробелы, что еще больше затрудняет его просмотр.
Некоторые разработчики используют метод каскадных таблиц стилей (CSS), но большинство разработчиков предпочитают использовать язык таблиц стилей XML для преобразований (XSLT). Использование XSLT дает некоторые значительные преимущества в гибкости и способности работать со сложными данными по сравнению с CSS, но XSLT также немного сложнее в изучении. Здесь можно найти учебник по XSLT.
Ничто не работает так хорошо, как быстрый пример, демонстрирующий, как работает XSLT. Чтобы использовать XSLT с файлом XML, вам необходимо добавить инструкцию обработки в файл XML.Следующая инструкция по обработке указывает браузеру, отображающему файл Customer2.XML, использовать файл CustomerOut.XSLT для форматирования информации. Это единственное различие между файлом Customers2.XML и файлом Customers.XML.
Чтобы преобразовать XML-документ в документ, который вы можете видеть, вы создаете из него HTML-документ. Следующий код представляет собой типичный пример кода XSLT, который можно использовать для преобразования:
Список клиентов
Совершенно верно: XSLT на самом деле является другой формой XML, поэтому он начинается с объявления XML.Корневой узел определяет документ как обеспечивающий поддержку XSLT. Он включает в себя атрибут пространства имен, который сообщает браузеру, где найти информацию о том, как интерпретировать XSLT. Проверьте здесь, чтобы узнать больше о пространствах имен.
Тег сообщает браузеру, какую информацию извлекать из файла XML для отображения. Этот документ извлекает все, что есть в XML-файле.
Следующие шаги начинаются с создания HTML-документа с тегами, необходимыми для этого.Это сокращенная страница. Обычно вы включаете все необходимые теги. Страница включает заголовок и начало таблицы.
Тег обрабатывает каждую из записей в файле. Затем файл строит строки и ячейки данных для таблицы. Тег извлекает значения данных элементов , и .
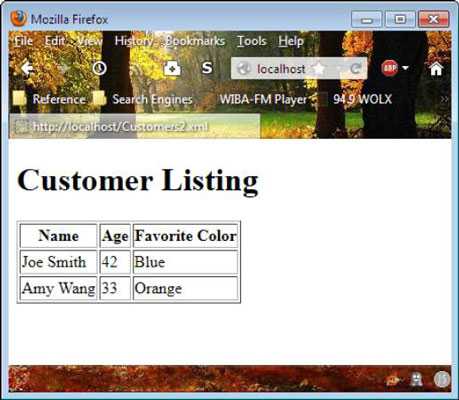
Некоторые браузеры сталкиваются с проблемами при использовании примера с локального диска.Например, Chrome отображает пустую страницу при доступе к Customers2.XML с локального диска. Чтобы протестировать этот метод таким образом, чтобы он работал в большинстве браузеров, скопируйте файлы на свой веб-сервер, а затем получите доступ к XML-файлу с веб-сервера.
Об авторе книги
Джон Пол Мюллер написал книги по сертификации и программированию, посвященные программированию на C #, Java, Windows и VBA. Он также является опытным техническим редактором и является автором статей для периодических изданий, включая Visual Basic Developer и SQL Server Professional .Вы можете связаться с ним по адресу [email protected].
. XML и CSS
Файлы Raw XML можно просматривать во всех основных браузерах.
Не ожидайте, что файлы XML будут отображаться как страницы HTML.
Просмотр файлов XML
-
Тове
Яни
Напоминание
Не забывай меня в эти выходные!
Посмотрите в браузере на приведенный выше XML-файл: примечание.xml
Большинство браузеров отображают XML-документ с элементами цветовой кодировки.
Часто знак плюс (+) или минус (-) слева элементов можно щелкнуть, чтобы развернуть или свернуть структуру элемента.
Чтобы просмотреть исходный XML-файл, попробуйте выбрать «Просмотр исходного кода страницы» или «Просмотр исходного кода» в меню браузера.
Примечание: В Safari 5 (и более ранних версиях) будет отображаться только текст элемента. Чтобы просмотреть необработанный XML, необходимо щелкнуть страницу правой кнопкой мыши и выбрать «Просмотреть исходный код».
Просмотр недопустимого файла XML
Если открывается ошибочный XML-файл, некоторые браузеры сообщают об ошибке, а некоторые отобразит его или отобразит неправильно.
-
Тове
Яни
Напоминание
Не забывай меня в эти выходные!
Попробуйте открыть следующий XML-файл: note_error.xml
Другие примеры XML
Просмотр некоторых XML-документов поможет вам почувствовать XML:
Меню завтрака в формате XML
Это меню завтрака из ресторана, сохраненное в формате XML.
Каталог на компакт-диске в формате XML
Это коллекция компакт-дисков, хранящаяся в формате XML.
Каталог растений в формате XML
Это каталог растений из заводского цеха, хранящийся в формате XML.
Почему XML отображается так?
Документы XML не содержат информации о том, как отображать данные.
Поскольку теги XML «изобретены» автором XML-документа, браузеры не знают, описывает ли тег, подобный
, таблицу HTML или обеденный стол. Без какой-либо информации о том, как отображать данные, браузеры могут просто отображать XML-документ как есть.
Совет: Если вы хотите стилизовать XML-документ, используйте XSLT.
. javascript - Как читать содержимое файла xml в jQuery и отображать в элементах html?
Переполнение стека - Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант
. Как получить значения из файла xml и отобразить на веб-странице html?
Переполнение стека - Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
. xml - Отображение файла xsl на странице html
Переполнение стека - Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
.