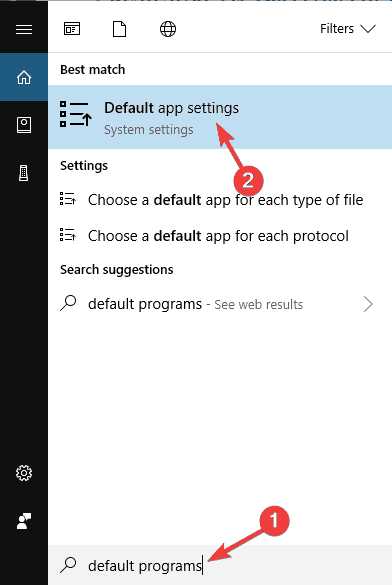
Как называется процесс сжатия файлов
Сжатие информации без потерь. Часть первая / Хабр
Доброго времени суток.Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Третья группа методов – это так называемые методы преобразования блока. Входящие данные разбиваются на блоки, которые затем трансформируются целиком. При этом некоторые методы, особенно основанные на перестановке блоков, могут не приводить к существенному (или вообще какому-либо) уменьшению объема данных. Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики
Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F = {p(si)} неизменно, и вероятности элементов взаимно независимы, то средняя длина кодов может быть рассчитана как
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента s
i распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.
Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.
Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.
Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 <-> B1
a2 <-> B2
…
an <-> Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B'B''. Тогда B' называют началом, или префиксом слова B, а B'' — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Итак, мы разобрались с основными определениями. Так как же происходит само кодирование без памяти?
Оно происходит в три этапа.
- Составляется алфавит Ψ символов исходного сообщения, причем символы алфавита сортируются по убыванию их вероятности появления в сообщении.
- Каждому символу ai из алфавита Ψ ставится в соответствие некое слово Bi из префиксного множества Ω.
- Осуществляется кодирование каждого символа, с последующим объединением кодов в один поток данных, который будет являться результатам сжатия.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
В первую очередь при кодировании алгоритмом Хаффмана, нам нужно построить схему ∑. Делается это следующим образом:
- Все буквы входного алфавита упорядочиваются в порядке убывания вероятностей. Все слова из алфавита выходного потока (то есть то, чем мы будем кодировать) изначально считаются пустыми (напомню, что алфавит выходного потока состоит только из символов {0,1}).
- Два символа aj-1 и aj входного потока, имеющие наименьшие вероятности появления, объединяются в один «псевдосимвол» с вероятностью p равной сумме вероятностей входящих в него символов. Затем мы дописываем 0 в начало слова Bj-1, и 1 в начало слова Bj, которые будут впоследствии являться кодами символов aj-1 и aj соответственно.
- Удаляем эти символы из алфавита исходного сообщения, но добавляем в этот алфавит сформированный псевдосимвол (естественно, он должен быть вставлен в алфавит на нужное место, с учетом его вероятности).
Шаги 2 и 3 повторяются до тех пор, пока в алфавите не останется только 1 псевдосимвол, содержащий все изначальные символы алфавита. При этом, поскольку на каждом шаге и для каждого символа происходит изменение соответствующего ему слова Bi (путем добавление единицы или нуля), то после завершения этой процедуры каждому изначальному символу алфавита ai будет соответствовать некий код Bi.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — { a1, a2, a3, a4}. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:
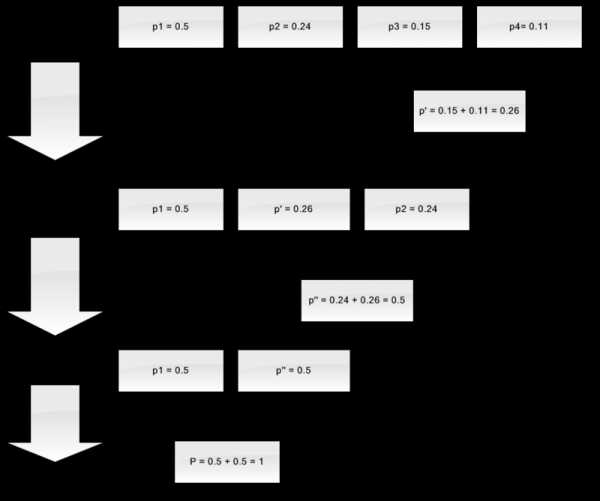
Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
a1 = 0
a2 = 11
a3 = 100
a4 = 101
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Литература
- Ватолин Д., Ратушняк А., Смирнов М. Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео; ISBN 5-86404-170-X; 2003 г.
- Д. Сэломон. Сжатие данных, изображения и звука; ISBN 5-94836-027-Х; 2004г.
- www.wikipedia.org
Как работает сжатие файлов | HowStuffWorks
В нашем предыдущем примере мы выбрали все повторяющиеся слова и поместили их в словарь. Для нас это наиболее очевидный способ составления словаря. Но программа сжатия видит это совершенно иначе: в ней нет концепции отдельных слов - она только ищет шаблоны. А чтобы максимально уменьшить размер файла, он тщательно выбирает, какие шаблоны включить в словарь.
Если подойти к фразе с этой точки зрения, мы получим совершенно другой словарь.
Объявление
Если программа сжатия просканирует фразу Кеннеди, первая повторяемость, с которой она столкнется, будет состоять всего из пары букв. В словах «не спрашивайте, что у вас» есть повторяющийся узор из буквы «т», за которой следует пробел - в «не» и «что». Если программа сжатия записала это в словарь, она могла бы записывать «1» каждый раз, когда за буквой «t» следовало пробел. Но в этой короткой фразе этого шаблона недостаточно, чтобы его можно было использовать, поэтому программа в конечном итоге его перезапишет.
Следующее, что программа может заметить, - это «ou», которое встречается как в «your», так и в «country». Если бы это был более длинный документ, запись этого шаблона в словарь могла бы сэкономить много места - «ou» - довольно распространенная комбинация в английском языке. Но по мере того, как программа сжатия прорабатывала это предложение, она быстро нашла лучший выбор для словарной статьи: не только повторяется «ou», но и повторяются целые слова «your» и «country», и они фактически повторяются. вместе, как фраза «ваша страна.«В этом случае программа заменит словарную статью для« ou »записью« ваша страна ».
Фраза «может сделать для» также повторяется, один раз за ней следует «ваш» и один раз за ней следует «вы», что дает нам повторяющийся образец «могу сделать для вас». Это позволяет нам записывать 15 символов (включая пробелы) с одним числовым значением, в то время как «ваша страна» позволяет нам записывать только 13 символов (с пробелами) с одним числовым значением, поэтому программа перезапишет запись «ваша страна» как просто «r страна, а затем напишите отдельную запись для "может сделать для вас.«Программа действует таким образом, собирая все повторяющиеся биты информации и затем вычисляя, какие шаблоны следует записать в словарь. Эта способность переписывать словарь является« адаптивной »частью алгоритма LZ на основе адаптивного словаря . способ, которым программа на самом деле это делает, довольно сложен, как вы можете видеть из обсуждений на Data-Compression.com.
Независимо от того, какой конкретный метод вы используете, эта система глубокого поиска позволяет сжимать файл гораздо эффективнее, чем если бы вы просто выбирали слова.Используя шаблоны, которые мы выбрали выше, и добавив «__» для пробелов, мы получили более крупный словарь:
- спросите__
- what__
- you
- r__country
- __can__do__for__you
И это меньшее предложение: «1not__2345 __ - __ 12354»
Предложение теперь занимает 18 единиц памяти, а наш словарь занимает 41 единицу.Итак, мы уменьшили общий размер файла с 79 до 59 единиц! Это всего лишь один способ сжатия фразы, и не обязательно самый эффективный. (Посмотрим, сможете ли вы найти лучший способ!)
Так насколько хороша эта система? Коэффициент уменьшения файла зависит от ряда факторов, включая тип файла, размер файла и схему сжатия.
В большинстве языков мира определенные буквы и слова часто встречаются вместе в одном шаблоне.Из-за такой высокой степени избыточности текстовые файлы , очень хорошо сжимаются. Уменьшение на 50 процентов и более типично для текстового файла хорошего размера. Большинство языков программирования также очень избыточны, потому что они используют относительно небольшой набор команд, которые часто идут вместе в заданном шаблоне. Файлы, содержащие много уникальной информации, например графику или файлы MP3, не могут быть сильно сжаты с помощью этой системы, потому что они не повторяют многие шаблоны (подробнее об этом в следующем разделе).
Если в файле много повторяющихся шаблонов, скорость уменьшения обычно увеличивается с размером файла. Вы можете убедиться в этом, просто взглянув на наш пример - если бы у нас было больше речи Кеннеди, мы могли бы чаще обращаться к шаблонам в нашем словаре и таким образом получать больше от файлового пространства каждой записи. Кроме того, в ходе более продолжительной работы могут появиться более распространенные шаблоны, что позволит нам создать более эффективный словарь.
Эта эффективность также зависит от конкретного алгоритма, используемого программой сжатия.Некоторые программы особенно подходят для сбора шаблонов в определенных типах файлов и поэтому могут сжать их более лаконично. У других есть словари в словарях, которые могут эффективно сжимать файлы большего размера, но не файлы меньшего размера. Хотя все программы сжатия подобного типа работают с одной и той же основной идеей, на самом деле существует множество вариантов выполнения. Программисты всегда пытаются построить лучшую систему.
.Объяснение WinZip Computing
Среди сотен различных типов расширений файлов файлы сжатия, такие как ZIP, являются уникальными. Они не предназначены для изображений, видео, аудио или какого-либо одного типа данных.
Вместо этого они являются результатом сжатия больших файлов во что-то более управляемое. При сжатии файла данные занимают меньше места, и файлы можно отправлять и получать намного быстрее.
Но подождите, как можно уменьшить размер файла, не испортив данные? Это может показаться невозможным, но как только вы узнаете, что происходит за кулисами, это становится понятным.
Итак, если вы когда-нибудь задумывались, "что делает сжатие файла?" тогда вы попали в нужное место. Итак, давайте начнем с некоторых основ.
Что такое сжатие файлов?
Это правда, что ZIP - не единственный тип сжатого файла, но он определенно один из самых распространенных. Мы могли бы продолжать и говорить о ZIP, ARC, ARJ, RAR, CAB и десятках других, но все они, по сути, работают одинаково.Итак, чтобы этот пост был понятным и легким для понимания, мы сосредоточимся только на расширении ZIP.
По сути, сжатый файл - это своего рода архив, содержащий один или несколько файлов, размер которых был уменьшен. Поскольку эти файлы меньше, их можно хранить, не занимая много места, или передавать через Интернет с более высокой скоростью. Используя такую программу, как WinZip, вы можете затем распаковать файл или файлы обратно в их исходное состояние без какого-либо ухудшения.
Нужно скачать Winzip?
Загрузите бесплатную 30-дневную пробную версию прямо сейчас!
Все еще не знаете, как на самом деле работает это волшебство? Потерпите меня, пока я буду немного разбираться в технике.
Как работает сжатие файлов?
Здесь все может немного усложниться.По сути, есть два основных типа сжатия файлов? без потерь и с потерями. Сжатие без потерь принимает ваши файлы и уменьшает их размер без потери информации. Сжатие с потерями уменьшает размер файла, отрубая фрагменты, которые не на 100% необходимы для работы. Я знаю, что это довольно большое упрощение, поэтому давайте разберем их по одному.
Сжатие файлов без потерь
Это может звучать безумно, но так работает.Чтобы сжатие без потерь работало, файл необходимо уменьшить, ничего не теряя. Это делается за счет удаления избыточности.
Что такое избыточность, спросите вы?
Избыточность данных - это условие, создаваемое в базе данных или среде хранения данных, в которой один и тот же фрагмент данных хранится в нескольких местах.
За счет исключения избыточности у вас остается только один экземпляр каждого бита данных.
Сжатие файлов без потерь будет примерно таким:
AAABBBBBCC
и сжав его до этого:
A3B5C2
Там же информация, но она упрощена и занимает меньше места (обратите внимание, что числа соответствуют количеству повторений предыдущей буквы). Таким образом, когда вы распаковываете (распаковываете / открываете / извлекаете) файл, он знает, как вернуться в исходную форму.Это в основном используется для текста и электронных таблиц, потому что потеря слов или данных из документа - это не то, чего вы хотите.
Сжатие файлов с потерями
Сжатие с потерями работает в основном так же, но, как вы, вероятно, можете понять по названию, это приводит к безвозвратной потере некоторых данных (не так плохо, как кажется).
Это чаще встречается с мультимедийными файлами, такими как видео, аудио и изображения, потому что они не сильно страдают от потери данных.Фактически, музыка и видео, которые у вас сейчас есть на вашем компьютере, вероятно, были сжаты, и вы даже не замечаете недостающих битов. Это связано с тем, что удаляемые данные находятся за пределами диапазона, который люди могут слышать или видеть.
Однако есть и обратная сторона - если вы снова и снова сжимаете один и тот же файл, используя метод с потерями, вы начнете замечать снижение качества, поскольку данные каждый раз удаляются.
Зачем сжимать файлы?
Нужно скачать Winzip?
Загрузите бесплатную 30-дневную пробную версию прямо сейчас!
Если вы часто редактируете медиафайлы, вы знаете, насколько важно сжатие файлов при передаче фотографий, музыки и видео.Вы действительно не хотите убивать всю свою пропускную способность и тратить кучу ценного дискового пространства. Если вы не один из таких людей, то вот почему это так необходимо.
Занимает меньше места
Допустим, у вас есть огромное количество файлов на вашем компьютере, но вы не планируете что-либо с ними делать какое-то время (может быть, вы виртуальный накопитель, кто знает). Оставлять их на жестком диске, чтобы они занимали место, - не самое практичное занятие.
Вместо этого вы можете заархивировать большое количество файлов в одну архивную папку, которая освобождает место и делает организацию более чистой.
Храните свою коллекцию старых фильмов о кунг-фу на жестком диске? Сожмите их все в один ZIP-файл и удивитесь, сколько места вы сэкономите.
Более эффективные переводы
Если вы когда-либо пытались отправить по электронной почте действительно большой файл, вы знаете, что это может занять много времени.Еще хуже - попытка отправить сразу несколько документов по электронной почте. Часто ваше сообщение не удается, потому что некоторые почтовые клиенты не разрешают передачу файлов более определенного размера.
Конечно, вы можете отправить серию нескольких писем с небольшими вложениями к каждому, но это отнимает много времени и сложно отслеживать (и вы, вероятно, рассердите получателя).
Благодаря сжатию ваших документов в один ZIP-файл, он займет меньше места и будет передаваться намного быстрее.Получателю просто нужно использовать такую программу, как WinZip, для извлечения файлов, и у него будет все, что вы отправили, в одной организованной папке.
Можно сэкономить деньги
Жесткие диски дорогие - я не должен вам об этом говорить. Очевидно, что для хранения большого количества данных требуется много места, так почему бы не получить максимальную отдачу от вложенных средств?
Допустим, у вас есть 200 ГБ данных, которые вам нужно спрятать на вашем компьютере, но на вашем жестком диске всего 250 ГБ.Конечно, он подойдет, но тогда у вас останется только 50 ГБ, что в наши дни немного.
Вы можете пойти и купить более крупный и дорогой жесткий диск, перенести все со старого на новый и все готово.
ИЛИ
Вы можете сжать 200 ГБ данных в ZIP-файл, который занимает всего 100 ГБ. У вас все еще есть все ваши файлы, готовые к использованию, когда они вам понадобятся, но вам не нужно тратить деньги на дополнительное пространство для хранения.
Как сжимать / распаковывать файлы
На этом этапе у вас должно быть достаточно четкое представление о сжатии файлов - как оно работает и почему это полезно. Это здорово и все такое, но вы, вероятно, хотите знать, как самостоятельно архивировать и распаковывать файлы, не так ли?
Ниже приводится ускоренный курс по процессу сжатия и распаковки файлов. К счастью, если файлы, которые вы пытаетесь сжать, относительно небольшие, ваша операционная система должна иметь возможность заархивировать их без использования стороннего программного обеспечения.Об этом позаботится простой вариант щелчка правой кнопкой мыши.
Но что, если вы имеете дело с несколькими гигабайтами данных? Вам понадобится что-то более привлекательное, чтобы заботиться о вещах. К счастью для вас WinZip - ведущий файловый компрессор.
Нужно скачать Winzip?
Загрузите бесплатную 30-дневную пробную версию прямо сейчас!
Сжатие больших файлов в WinZip
- Эта часть довольно сложная.Во-первых, вам нужно открыть WinZip (сложно, правда?).
- Затем вам нужно найти и выбрать все файлы, которые вы хотите сжать, на панели Файлы .
- После того, как все они выбраны, нажмите Добавить в архив.
- Щелкните Сохранить как.
- Выберите целевое местоположение, дайте ему имя и нажмите Сохранить. И это все.
Сжатие больших файлов за пределами WinZip (для работы необходимо установить WinZip)
- Откройте папку, содержащую все файлы, которые вы хотите сжать.
- Выделите каждую, которую собираетесь застегнуть.
- Щелкните правой кнопкой мыши в выделенной области, и появится подменю WinZip. У вас есть пара вариантов на выбор.
- Теперь ваш Zip-файл создан для хранения или передачи.
* Добавить в Zip-файл: , щелкнув эту опцию, вы сможете присвоить имени вашему Zip-файлу, определить, как он должен быть сжат, и добавить шифрование.
* Добавить в [имя файла] .zip: Эти параметры работают намного быстрее, но у вас не так много свободы.По сути, он создаст Zip-файл с именем содержащей его папки, но вы не сможете настроить параметры.
Распаковка файлов
Распаковать файл очень просто:
- Перетаскивание файла или папки из заархивированной папки в новое место.
ИЛИ
- Щелкните правой кнопкой мыши внутри заархивированной папки, выберите Извлечь все , затем следуйте инструкциям.
Вот и все
Итак, это подводит итог основам сжатия файлов. Кажется невозможным уменьшить размер файла, а затем снова собрать его в другом месте, но, по сути, происходит именно это.
Если вы хотите узнать больше, посетите веб-сайт WinZip для получения дополнительной документации.
Нужно скачать Winzip?
Загрузите бесплатную 30-дневную пробную версию прямо сейчас!
.Сжатие и декомпрессия файлов - приложения Win32
- 3 минуты на чтение
В этой статье
Тома файловой системы NTFS поддерживают сжатие файлов для отдельных файлов. В файловой системе NTFS используется алгоритм сжатия файлов Lempel-Ziv. Это алгоритм сжатия без потерь , что означает, что никакие данные не теряются при сжатии и распаковке файла, в отличие от алгоритмов сжатия с потерями , таких как JPEG, где некоторые данные теряются каждый раз при сжатии и распаковке данных.
Сжатие данных уменьшает размер файла за счет минимизации избыточных данных. В текстовом файле избыточными данными могут быть часто встречающиеся символы, такие как пробел, или общие гласные, такие как буквы e и a; это также могут быть часто встречающиеся символьные строки. Сжатие данных создает сжатую версию файла за счет минимизации этих избыточных данных.
Каждый тип алгоритма сжатия данных уникальным образом минимизирует избыточные данные. Например, алгоритм кодирования Хаффмана назначает код символам в файле в зависимости от того, как часто эти символы встречаются.Другой алгоритм сжатия, называемый кодированием длины серий , генерирует двухчастное значение для повторяющихся символов: первая часть определяет количество повторений символа, а вторая часть идентифицирует символ. Другой алгоритм сжатия, известный как алгоритм Лемпеля-Зива , преобразует строки переменной длины в коды фиксированной длины, которые занимают меньше места, чем исходные строки.
Сжатие файлов файловой системы NTFS
В файловой системе NTFS сжатие выполняется прозрачно.Это означает, что его можно использовать, не требуя внесения изменений в существующие приложения. Сжатые байты файла недоступны для приложений; они видят только несжатые данные. Следовательно, приложения, открывающие сжатый файл, могут работать с ним, как если бы он не был сжат. Однако эти файлы нельзя скопировать в другую файловую систему.
Если вы сжимаете файл размером более 30 гигабайт, сжатие может не завершиться успешно.
В следующих разделах описывается сжатие файлов файловой системы NTFS:
Библиотеки сжатия и декомпрессии файлов
Библиотеки сжатия и распаковки файлов берут существующий файл или файлы и создают файл или файлы, которые являются сжатыми версиями оригиналов.Сжатие также осуществляется без потерь, но оно не прозрачно для приложений. Приложение может работать с такими файлами только с помощью библиотеки сжатия файлов. Кроме того, единственные операции, которые вы можете выполнять с такими файлами, - это создание сжатого файла из оригинала и восстановление исходных данных из распакованной версии. Редактирование обычно не поддерживается, а поиск ограничен, если он вообще поддерживается.
Обычно приложение вызывает функции в Lz32.dll для распаковки данных, сжатых с помощью Compress.exe. Функции также могут обрабатывать файлы, не пытаясь их распаковать.
Вы можете использовать функции Lz32.dll для распаковки одного или нескольких файлов. Вы также можете использовать их для распаковки сжатых файлов по частям.
В следующих разделах описывается распаковка файлов, обеспечиваемая функциями в Lz32.dll:
Шкафы
Шкафысоздаются библиотекой сжатия, которая поддерживает такие функции, как охват дисков и сжатие нескольких файлов.Для получения дополнительной информации см. Комплект для разработки программного обеспечения кабинета: https://msdn.microsoft.com/library/dncabsdk/html/cabdl.asp.
В этом разделе
.Сжатие данных- что такое сжатие данных? Объясните сжатие без потерь и сжатие с потерями.
- Перейти к основному содержанию
- Перейти к основной боковой панели
- Перейти к дополнительной боковой панели
- Перейти к нижнему колонтитулу
Компьютерные заметки
Библиотека-
- Computer Fundamental
- Computer Memory
- Операционная система
- Компьютерные сети
- Программирование на C
- Программирование на C ++
- Программирование на Java
- Программирование на C #
- Учебное пособие по SQL
- Учебное пособие по управлению графикой
- Компьютерное руководство по управлению графикой
- Style Sheet
- JavaScript Tutorial
- Html Tutorial
- Wordpress Tutorial
- Python Tutorial
- PHP Tutorial
- JSP Tutorial
- Angular4 Tutorial
- Angular4 Tutorial 14 Структуры данных
- E Commerce Tutorial
- Visual Basic
- Structs2 Tutorial
- Digital Electronics