Как найти файл в интернете
Ищем и скачиваем непопулярные и старые файлы в интернете / Хабр
Преимущественно медиафайлы. На полном серьезе, без шуток.Бывает, случается так, что вы хотите скачать альбом 2007 года исполнителя, который кроме вас известен 3.5 людям, какой-нибудь испанский ска-панк или малопопулярный спидкор европейского происхождения. Находите BitTorrent-раздачу, ставите на закачку, быстро скачиваете 14.7%, и… все. Проходит день, неделя, месяц, а процент скачанного не увеличивается. Вы ищете этот альбом в поисковике, натыкаетесь на форумы, показывающие ссылки только после регистрации и 5 написанных сообщений, регистрируетесь, флудите в мертвых темах, вам открываются ссылки на файлообменники вроде rapidshare и megaupload, которые уже сто лет как умерли.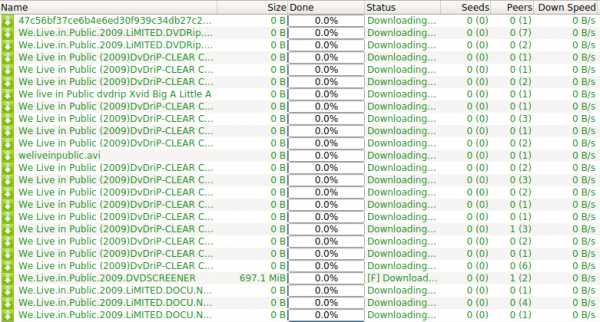
Увы, частая ситуация в попытке хоть что-то скачать
Такое случается. В последнее время, к сожалению, случается чаще: правообладатели и правоохранительные органы всерьез взялись за файлообмен; в прошлом году закрылись или были закрыты KickassTorrents, BlackCat Games, what.cd, btdigg, torrentz.eu, EX.ua, fs.to, torrents.net.ua, и еще куча других сайтов. И если поиск свежих рипов фильмов, сериалов, музыки, мультиков все еще не представляет большой проблемы, несмотря на многократно участившееся удаления со стороны правообладателей контента из поисковых систем, торрент-трекеров и файлообменников, то поиск и скачивание оригинала (DVD или Blu-Ray) фильмов и сериалов или просто ТВ-рипов 7-летней давности на не-английском и не-русском языке — не такая уж простая задача.
Зачем это нужно?
• Отсутствие некоторых релизов на дискахВ случае с видео, иногда случается так, что картину дублируют и транслируют по телевидению в какой-то стране, а на дисках не выпускают. Капперы выкладывают ТВ-рипы в файлообменные сети или BitTorrent, затем выходят DVD в другой стране, без соответствующей аудиодорожки, например, французской, и люди вынуждены либо качать DVDRip с хорошим качеством видео без французской дорожки, либо ТВ-рип с ней. Проходит время, ТВ-рип раздают все меньше и меньше людей, он удаляется с файлообменников из-за неактивности, и все — французский релиз становится скачать гораздо сложнее.
Проблему можно было бы решить, совместив аудиодорожку из ТВ-рипа с доступным видео из DVD, что не всегда так просто, как кажется. Этим никто не занялся и ТВ-версия умерла.
• Отличие контента ТВ- и DVD-версии
Например, мультсериал «Дарья» лишился почти всей музыки, которая была в ТВ-версии, из-за юридических проблем с перелицензированием. Долгое время люди, желающие посмотреть данный сериал, стояли перед выбором: либо полноценная ТВ-версия с музыкой и плохим качеством видео, либо DVD-версия с хорошим качеством, но без музыки.
• Региональные различия
Справедливы как для видео, так и для музыки. Мультсериал W.I.T.C.H. выпускался с 4 разными опенингами, только один из которых попал на DVD.
Зачастую, музыкальные альбомы, выпускаемые для рынка Японии, содержат бонусные треки, которых нет в других изданиях.
Как вы уже поняли, причин может быть множество. Где искать непопулярные и старые файлы?
Usenet — распределенная сеть из серверов, синхронизирующих информацию между собой. Структура Usenet напоминает что-то среднее между форумами и электронной почтой: в «новостных группах» (так называются тематические категории в Usenet) сообщения имеют древовидную структуру, пользователи могут подписываться на конкретные группы, читать и писать в них. Как и в Email, у сообщений есть тема (subject), которая позволяет ориентироваться в содержании дискуссий. Сейчас используется преимущественно для обмена файлами.История Usenet
Появившаяся в 1979 году, в до-интернетовскую эпоху сеть использовала прямые модемные соединения для передачи информации через UUCP и была инструментом преимущественно текстового общения. В свое время Usenet конкурировал с BBS, существовали специальные шлюзы в и из Fidonet. С приходом интернета, сообщения Usenet начали передаваться по TCP/IP, используя протокол NNTP, который остается относительно используемым и вне Usenet (например, можно читать огромное количество публичных списков рассылок через gmane и RSS-фиды через gwene, причем, в отличие от списков рассылок, вы всегда можете посмотреть всю историю, а не только сообщения с момента вашей подписки).
С увеличением пропускной способности линий, улучшением модемов и их протоколов, к девяностым сеть уже вовсю использовали для передачи бинарных файлов: вареза, музыки, видеофайлов. Делалось это примерно таким же образом, как и в Email: файл разбивается на небольшие части (тома), кодируется печатными символами в 7-битной кодировке с использованием Base64 или uuencode, и отправляется в ньюсгруппу. Кодирование в 7 бит добавляет около 30% накладных расходов на передачу файла. Спецификация позволяет использовать большинство символов из ASCII-таблицы, поэтому в 2001 году появляется алгоритм передачи файлов yEnc, увеличивающий файл всего на 1-2%, экранируя только символы переноса строки, NULL-байты и символ равенства (=). Им пользуются и по сей день.
Для контроля целостности и восстановления поврежденных или отсутствующих данных используется Parchive.
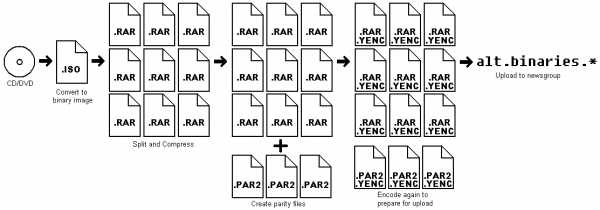
До 2008 года крупнейшие Usenet-провайдеры хранили бинарные файлы около 100-150 дней с момента их загрузки (так называемый retention time, срок хранения файлов). С 2008 года самые крупные провайдеры вообще перестали что-либо удалять, и на текущий момент можно без проблем скачать файлы восьмилетней давности, а провайдеры поменьше выставили retention time в 1000+ дней, что тоже немало. К этому моменту текстовое общение в Usenet сошло на нет и сеть использовалась преимущественно для хранения и передачи файлов.
Начиная где-то с середины 2011 года за сетью начали следить правообладатели, из-за чего Usenet-провайдерам пришлось удалять файлы, что сильно повлияло на целостность релизов. Некоторые провайдеры сделали автоматизированные системы удаления файлов, чтобы правообладатели могли удалять загрузки самостоятельно. Дабы предотвратить или хотя бы замедлить обнаружение файлов правообладателями, энтузиасты начинают загружать файлы с обфусцированными именами, в архивах под паролями, и добавляют их в каталоги систем индексации релизов (indexers), доступ к которым, как правило, осуществляется либо за деньги, либо по приглашениям. Обычными способами ни найти, ни скачать такие релизы не удастся.
В современной России о Usenet почти никому не известно, хотя рунет зарождался именно с него, по протоколу UUCP, и был одним из двух рабочих каналов для связи с Западом во время путча 1991 года (второй — FIDO). Сейчас Usenet наиболее популярен в странах, законы которых позволяют штрафовать пользователей за скачивание или раздачу контента, защищенного авторским правом, например, в Германии. В отличие от BitTorrent, узнать IP-адресы пользователей Usenet сторонней организации невозможно.
Подключение к Usenet
Полноценно пользоваться сетью бесплатно, скорее всего, не получится: либо столкнетесь с низким временем хранения файлов (10-30 дней), либо с низкой скоростью, либо получите доступ только к текстовым группам. Придется купить доступ у какого-нибудь провайдера или их реселлеров. Большинство провайдеров имеют два типа тарифов: месячный абонемент без ограничений по количеству скачанного (unlimited) и пакет трафика без ограничения по времени (block). Если вы собираетесь качать файлы из сети пару раз в месяц, block-доступа вам хватит надолго.Крупнейшими провайдерами являются Altopia, Giganews, Eweka, NewsHosting, Astraweb.
Теперь нужно каким-то образом получить nzb-файл с метаинформацией, это что-то вроде .torrent-файла. Если у вас его нет, нужно воспользоваться поисковиком-индексатором.
Индексаторы
Общедоступные индексаторы завалены спамом с вирусами и ищут, как правило, плохо, но, тем не менее, подходят для поиска устаревших файлов, загруженных около 5 и более лет назад.Вот некоторые из них:
Бесплатные индексаторы, требующие регистрацию, больше подходят для файлов посвежее. Они хорошо каталогизированы, релизы имеют не только название, но и описание с картинкой.
Последние два особенно рекомендую, в них можно найти множество обфусцированных релизов.
Существуют и узконаправленные сайты. Например, индексатор аниме anizb и музыки albumsindex.
Скачивание с Usenet
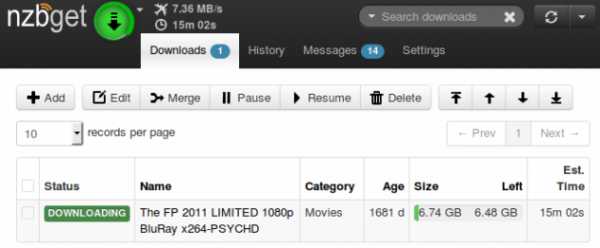
Давайте попробуем скачать фильм The FP 2011 года, достаточно неизвестный и непопулярный, BDRip'а которого в 1080p так просто найти мне не удалось. Для этого вам нужно найти nzb-файл и импортировать его в программу для закачки, например, NZBGet или SABnzbd, предварительно ее установив.Заходим на nzbking.com, выполняем поиск по «the.fp.2011».
Видим в индексе файл, у которого доступна только одна часть из 3867. Такой файл не скачать, поэтому индексатор отображает этот параметр красным цветом.
Файлы, защищенные паролем, как правило, являются просто фейками.
На второй странице обнаруживается DVDRip, с адекватным размером, в архиве без пароля — хороший знак.
На третьей странице находим BDRip и несколько DVDRip'ов, похожих на настоящие (судя по размеру файла и дате загрузки).
Выбираем файлы, которые хотим скачать, нажимаем кнопку «Download NZB», скачиваем .nzb-файл и импортируем его в NZBGet или SABnzbd, предварительно вписав данные своего Usenet-аккаунта в настройки программы. Начинается скачивание со скоростью канала моего провайдера.
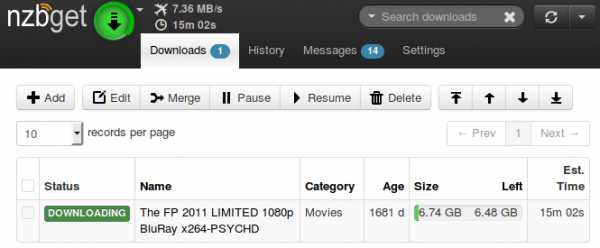
По окончанию скачивания, NZBGet автоматически распакует архивы и удалит их. Файл размером 6.74 ГБ, загруженный 4.5 года назад, скачался за 15 минут!
На сегодняшний день существуют как отдельные каналы, так и целые серверы, посвященные файлообмену через XDCC. Почти у любой мало-мальски серьезной аниме релиз-группы, у которой даже может не быть веб-сайта, есть свой бот, с которого можно скачать все релизы группы независимо от их возраста. Популярность XDCC обусловлена функциональностью скриптов, легкостью их настройки и администрирования: выкладывающему релиз достаточно загрузить каким-либо образом файл на сервер с ботом, например по FTP, а бот сам добавит его в индекс, оповестит пользователей на канале о появлении нового файла, автоматически отправит его пользователям, подписавшимся на обновления этого бота (например, если это новый эпизод сериала).
В специальных IRC-сетях распространяют варез, свежие и не очень фильмы, музыку, игры, книги. XDCC не наделен вниманием правообладателей, поэтому у ботов можно найти множество вещей, которые сложно найти в других местах.
Индексаторы
Многие (но не все) XDCC-боты индексируются специальными скриптами, предоставляющими веб-интерфейс для эффективного поиска файлов.Общие индексаторы контента:
Индексаторы аниме:
Скачивание из IRC
Вам потребуется IRC-клиент, подойдет практически любой (подавляющее большинство клиентов поддерживает DCC). Подключаемся к интересующему вас серверу из списка, заходим на канал. Крупнейшие серверы с книгами:- irc.undernet.org, канал #bookz
- irc.irchighway.net, канал #ebooks
Варезом:
- irc.criten.net, канал #elitewarez
- irc.infatech.net, канал #elitewarez
- irc.scenep2p.net, канал #the.source
Фильмами:
- irc.abjects.net, канал #moviegods
- irc.abjects.net, канал #beast-xdcc
Мультфильмами и аниме:
- irc.rizon.net, канал #news
- irc.xertion.org, канал #cartoon-world
Все версии ботов принимают команду
!find или @find для поиска файлов, после чего отправляют результаты личным сообщением. Для популярных запросов на каналах с большим количеством ботов вас буквально заспамит ответами, поэтому, если канал поддерживает команду @search, лучше воспользоваться ей — специальный индексатор канала отправит вам результаты одним файлом через DCC.Попробуем скачать «How Music Got Free» («Как музыка стала свободной» по-русски) — замечательная книга об истории музыкальной индустрии, технологиях обмена музыкой и человеке, который почти в одиночку стащил 2000 альбомов и выложил их в сеть.
Бот присылает результат поиска в виде ZIP-архива с текстовым файлом:
Отправляем боту запрос на скачивание файла:
…и принимаем его!
Конечно, не обязательно искать напрямую на канале. Если вы нашли нужный файл через индексатор, можете сразу запросить его у бота командой, которую вам сгенерирует сайт.
Direct Connect-сеть представляет собой клиент-серверную архитектуру, где все коммуникации, кроме непосредственно обмена файлами, происходят через сервер. В DC++ есть возможность расшаривания файлов и директорий, поиск файлов с учетом их типа (видео, аудио, архивы, документы, образы дисков), ссылки на файлы, независящие от имени файла и, конечно же, чат, из-за чего DC++-хабы были очень популярны в локальных сетях интернет-провайдеров РФ. Сибирский провайдер GoodLine рекламировал свой внутрисетевой хаб на уличных рекламных щитах, писал ПО для упрощения файлообмена и даже встраивал его в свои Set-top box, чтобы клиенты могли смотреть новинки кинематографа прямо с телевизора. На хабе сидело более 100000 человек — больше, чем в любом другом хабе в мире.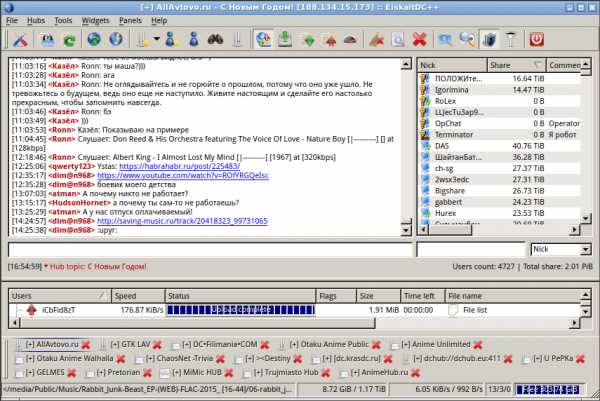
Из-за того, что пользователю достаточно указать путь к файлам, к которым он хочет открыть публичный доступ, в DC++ можно найти жуткое, малоизвестное старьё, которое, по мнению пользователя с этим файлом, уж точно никому не сдалось, но он его все равно расшарил, так, на всякий случай.
3 человека раздают видеоурок 11-летней давности, который ни одному вменяемому человеку смотреть не захочется, поверьте.
Скачивание из DC++
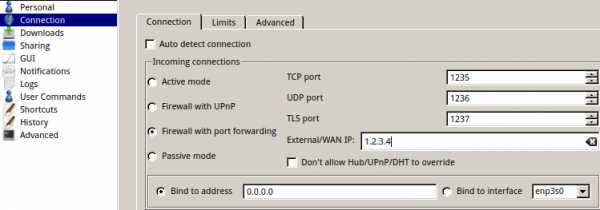
Вам потребуется какой-нибудь DC-клиент. Под Windows рекомендую FlylinkDC++ (который, к тому же, поддерживает BitTorrent), под Linux — EiskaltDC++ и AirDC++ Web. Далее нужно подключиться к популярным хабам, лучше сразу к десятку. Список хабов есть в самих программах, но можно воспользоваться специальной страницей и скопировать адреса оттуда.Настоятельно рекомендую включить «активный» режим, пробросить порты, ввести ваш внешний IP-адрес в настройках программы и удостовериться, что к вам возможны подключения извне, иначе, в «пассивном» режиме у вас будут ограничения на количество результатов поиска, вы не сможете качать файлы с других пользователей в «пассивном» режиме.
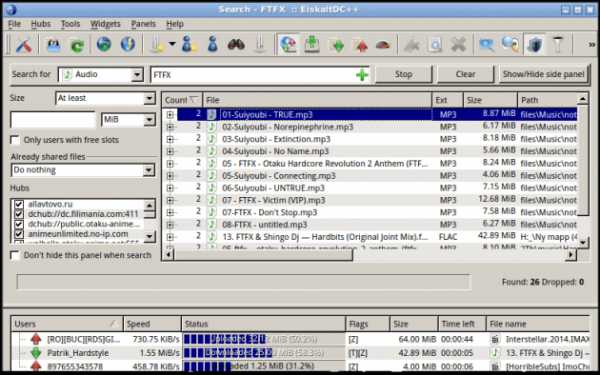
Поиск и скачивание файлов интуитивно понятно: вводите название, опционально выбираете тип контента и фильтр по размеру, нажимаете кнопку поиска, кликаете два раза по результату, файл начинает скачиваться. Также можно посмотреть все файлы пользователя (и, например, скачать папку с найденным файлом целиком), нажав правой кнопкой по конкретному результату и выбрав соответствующий пункт меню.
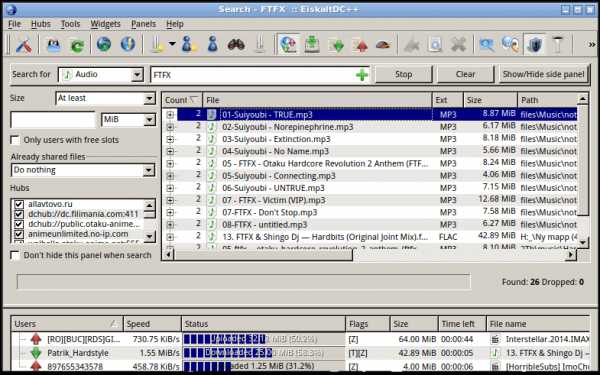
Если нужного вам файла не нашлось, имеет смысл периодически повторять поиск. Некоторые люди запускают DC-клиент только тогда, когда им нужно что-то скачать, и вам нужно поймать момент, чтобы найти файл у таких пользователей.
Из-за ограничений протокла NMDC, одновременный поиск нескольких файлов затруднен, результаты одного поискового запроса могут перемешиваться и отображаться в соседних окнах поиска, поэтому лучше не искать несколько файлов одновременно. У хабов, работающих по протоколу ADC, таких ограничений нет, но и таких хабов удручающе мало (их URI начинается с adc://, а не с dchub://).
Индексаторы
Поиск внутри программы может найти только файлы пользователей, находящихся в DC-сети на момент поиска, поэтому индексаторы очень полезны для нахождения и скачивания файлов с редко запускающих программу людей.Насколько мне известно, полноценный индексатор DC++ есть только один — spacelib.dlinkddns.com (и его второй адрес dcpoisk.no-ip.org). Поиск основан на движке Sphinx и учитывает морфологию (в том числе и русского языка). Поисковик генерирует magnet-ссылки для результатов поиска, которые можно поставить на закачку в клиенте.
Иногда он подолгу недоступен, например, в прошлый раз он не работал два месяца подряд.
eDonkey2000 выжил. Этому поспособствовал протокол полностью децентрализованного обмена Kad, который был внедрен в сторонние клиенты незадолго до закрытия Razorback 2 и главного сервера оригинальной программы, уступающей в функциональности и скорости альтернативным реализациям.
В ed2k можно найти примерно то же самое, что и в DC++ — старые файлы, ТВ-шоу на разных языках, разнообразную музыку, игры, варез, старые книги по программированию, математике, биологии. Новинки, разумеется, тоже в наличии. Хоть протокол и поддерживает чаты и просмотр всех файлов пользователя в открытом доступе, эти функции по умолчанию отключены, и, скорее всего, вам не удастся пообщаться с интересующими вас людьми через программу.
Скачивание в eDonkey2000 / Kad
Как вы уже догадались, потребуется ed2k-клиент. Хороший выбор для Linux — aMule, для Windows, наверное, eMule, хоть он и не обновлялся с 2011 (Обновление: появилась официальная версия eMule от сообщества, доступная для скачивания на официальном сайте, она обновляется). Крайне рекомендую пробросить порты, чтобы иметь возможность скачивать с пользователей за NAT (LowID).Процесс поиска и скачивания файлов очень похож на таковой в DC++ — вводим поисковой запрос, получаем результаты поиска с пользователей, находящихся онлайн, кликаем на файлы для начала скачивания.
Файл отобразится в результатах даже в том случае, у пользователей, находящихся онлайн, есть только его части, но не файл целиком.
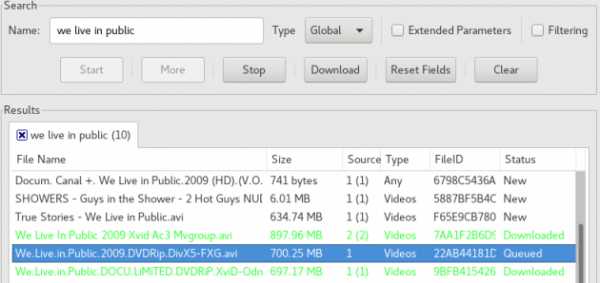
Попробуем найти малоизвестный документальный фильм 2009 года We Live In Public — картину, повествующую о событиях 90-х, которые частично предсказали современный интернет. Часть времени в фильме уделяется сайту pseudo.com — сервису аудио- и видеотрансляций, основанном в 1993 году.
Вводим поисковую фразу, получаем результаты: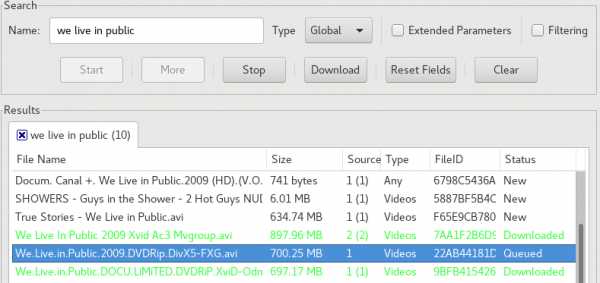
Кликаем, начинается скачивание:
Загрузка файла может растянуться на недели и месяцы. По какой-то причине, многие пользователи сети имеют отвратительное интернет-соединение, да еще и появляются раз в неделю на пару часов, а то и меньше.
Soulseek — централизованная сеть обмена музыкальным файлами по принципу P2P, созданная в 2000 году одним из разработчиков Napster. Долгое время была популярна среди слушателей и авторов IDM и прочей электронной музыки, и по сей день сеть развивается и остается хорошим местом для поиска аудиофайлов. Есть групповые и приватные чаты, возможность раздачи файлов только друзьям, удобный поиск музыки с указанием битрейта и других характеристик аудиофайлов. Некоторые поисковые запросы цензурируются.Существует официальный кроссплатформенный проприетарный клиент SoulseekQt и два развивающихся неофициальных: Nicotine+ и Museek+.
Все популярные клиенты BitTorrent могут искать пиров и обмениваться торрент-файлами через распределенную хеш-таблицу (DHT). Этим пользуются не только компании, отслеживающие раздающих файл пользователей, по договору с правообладателями контента, но и индексаторы, которые пытаются получить torrent-файл с infohash из DHT-запроса и сохранить его в своей базе. Индексаторы могут найти нигде не опубликованный или просто редкий торрент по названию директории или файла, а также различные дубликаты интересующего вас торрента с потенциальными сидерами.Ранее самым популярным индексатором был ныне неработающий btdigg, на смену ему, с некоторым запозданием, пришли следующие сайты:
К сожалению, подобные сервисы не живут долго: два моих любимых, fastbot и BTKitty.red, не открывались на момент написания статьи.Почти в каждом регионе существуют свои местные файлообменники, пользующиеся популярностью у конкретной языковой группы. Например, на uloz.to можно найти много чешского и словацкого контента, zone-telechargement.ws подойдет любителям французского языка, а chomikuj.pl для поляков.
Индексаторы FTP-серверов нечасто находят нужные файлы, но попытаться стоит:
Поисковики по популярным файлообменникам тоже существуют, но не всегда эффективны:
До совсем недавнего времени большое количество контента можно было найти на ex.ua, но увы.
Не всегда достаточно искать файлы только по названию материала, так можно упустить сценические релизы.
Рели́зная гру́ппа — сообщество людей-энтузиастов, объединенных идеей свободы информации. Выпускает электронные копии CD или DVD с фильмами, музыкой, программами и играми для компьютеров и игровых приставок, руководствуясь правилами релизов и соревнуясь со своими коллегами-конкурентами в скорости и качестве выпуска таких копий (релизов). Сообщество релизных групп, объединенных одной темой (музыка определенного жанра, кинофильмы или варез), называется сценой.https://ru.wikipedia.org/wiki/Релизная_группа
Сценические релизы очень часто содержат сокращенные или намеренно испорченные имена архивов, которые нельзя найти обычным поиском по имени файла. Чтобы узнать настоящее имя, нужно поискать его в специальных индексаторах сцен-релизов: layer13.net, pre.corrupt-net.org и predb.me.
Попробуем узнать сценическое название архивов с релизом We Live In Public от PUZZLE на Layer13:
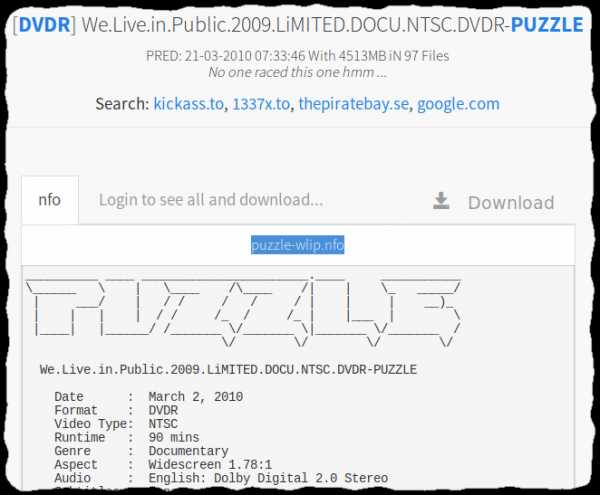
NFO-файл называется «puzzle-wlip.nfo». Названия архивов практически всегда, в 99% случаев совпадают с названием NFO, поэтому попробуем поискать это название в Usenet-индексаторе: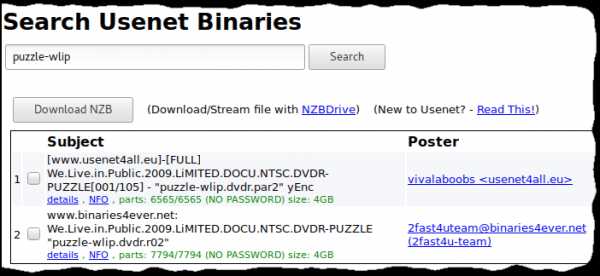
Ура, теперь мы можем скачать DVD фильма!
Обычные поисковые системы вроде Google не всегда будут вам помощниками. Во-первых, Google следует букве закона и удаляет (скрывает) результаты с сайтов, о которых сообщают ему правообладатели в рамках DMCA, во-вторых, поиск контента с названием из спецсимволов затруднен: проблемно найти что-либо о W.I.T.C.H., вам постоянно подсовывают информацию о Witch, The Witch или Blair Witch. Я предпочитаю пользоваться DuckDuckGo, Bing и метапоисковиком SearX — через них можно найти материалы, недоступные в Google.
Если вас интересует релиз на конкретном языке, уместней узнать локализованное название и совершать поиск по нему. Получить подобную информацию можно на Wikipedia, IMDb и других подобных сайтах.
Для аниме есть anidb, хранящий информацию о релизах групп на разных языках. Карточка группы, как правило, содержит ссылку на сайт или IRC-канал, где можно пообщаться с ее членами и скачать файлы через XDCC.
Помимо источника, разрешения видео, языков аудиодорожек и субтитров, на anidb есть TTH-хеш для DC++ и ed2k-ссылка для каждого файла.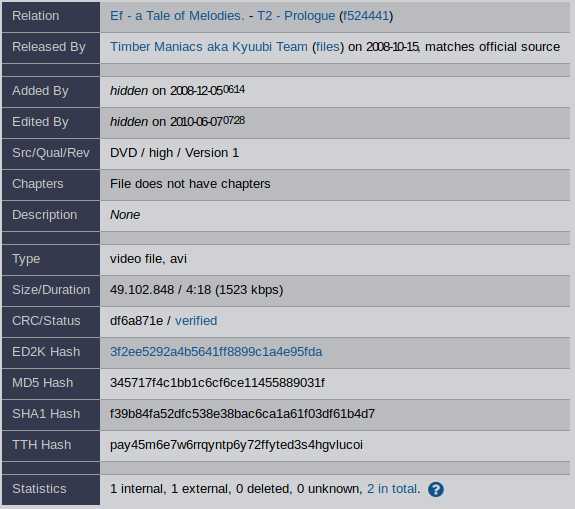
Скрытый текст
А еще Usenet можно использовать для дешевого хранения резервных копий: шифруем файлы, покупаем доступ в Usenet за $10, загружаем файлы, через 4 года опять покупаем доступ и скачиваем их за еще одни $10. В отличие от облаков, в Usenet не нужно оплачивать хранение файлов. Но без фанатизма, а то удалят.
Как искать в интернете малоизвестные и непопулярные файлы
Иногда случается так, что вы хотите скачать свободно распространяемый музыкальный альбом 2007 года, выпущенный исполнителем, которого знает три с половиной человека. Вы находите торрент-файл, запускаете его, загрузка доходит до 14,7% и… всё. Проходят дни и недели, а загрузка стоит на месте. Вы начинаете искать альбом в Google, рыщете по форумам и наконец находите ссылки на какие-нибудь файлообменники, но они уже давно не работают.
Такое происходит всё чаще и чаще — правообладатели постоянно закрывают полезные ресурсы. И если популярный контент найти по-прежнему не проблема, отыскать какой-нибудь телевизионный сериал семилетней давности на испанском языке может быть крайне трудно.
Что бы вам ни понадобилось в интернете, есть ряд способов это отыскать. Мы предлагаем все нижеперечисленные варианты исключительно для ознакомления с контентом, но ни в коем случае не для воровства.
Usenet
Usenet — распределённая сеть серверов, между которыми синхронизируются данные. Структура Usenet напоминает гибрид форума и электронной почты. Пользователи могут подключаться к специальным группам (Newsgroups), что-то в них читать или писать. Как и в случае с почтой, у сообщений есть тема, которая помогает определить тему группы. Сегодня Usenet используется по большей части для обмена файлами.
До 2008 года крупные провайдеры Usenet хранили файлы лишь 100–150 дней, однако затем файлы стали храниться вечно. Более мелкие провайдеры оставляют контент на 1 000 и более дней, чего зачастую тоже достаточно.
Примерно в середине 2001 года Usenet стали замечать правообладатели, из-за чего провайдерам пришлось удалять защищённый авторским правом контент. Но энтузиасты быстро нашли обходной путь: они стали давать файлам запутанные названия, защищать архивы паролями и добавлять их на специальные сайты, к которым можно получить доступ только по приглашению.
В России о существовании Usenet почти никто не знает, чего не скажешь о странах, где власти усердно борются с пиратством. В отличие от протокола BitTorrent, в Usenet нельзя определить IP-адрес пользователя без помощи провайдера сервиса или поставщика интернет-услуг.
Как подключиться к Usenet
В большинстве случаев бесплатно подключиться не выйдет. Придётся довольствоваться либо малым временем хранения файлов, либо низкой скоростью, либо доступом только к текстовым группам.
Провайдеры предлагают два типа платного доступа: ежемесячную подписку с неограниченным объёмом загружаемых данных или неограниченные по времени тарифы с лимитированным трафиком. Второй вариант — для тех, кому лишь иногда требуется что-то скачать. Крупнейшие поставщики таких услуг — Altopia, Giganews, Eweka, NewsHosting, Astraweb.
Теперь нужно понять, где брать NZB-файлы с метаинформацией — что-то вроде торрент-файлов. Для этого используются специальные поисковые движки — индексаторы.
Индексаторы
Публичные индексаторы полны спама и вирусов, но они всё ещё годятся для поиска файлов, загруженных пять или более лет назад. Вот некоторые из них:
Бесплатные индексаторы, требующие регистрации, больше подходят для поиска новых файлов. Они хорошо структурированы, у контента есть не только названия, но и описания с картинками. Можно попробовать следующие:
Также существуют индексаторы только для определённых типов контента. Например, anizb подойдёт поклонникам аниме, а albumsindex — тем, кто ищет музыку.
Скачивание из Usenet
В качестве примера возьмём «Фрейзер Парк» (The FP) — малоизвестный фильм 2011 года, вариант которого в разрешении 1080p отыскать практически невозможно. Нужно найти NZB-файл и запустить его через программу вроде NZBGet или SABnzbd.
Заходим на nzbking.com и ищем the.fp.2011.
medium.comЗдесь доступна только одна часть из 3 867. Вы не можете скачать такой файл, он помечен красным.
medium.comЗащищённые паролями файлы (Password protected) обычно являются фальшивками.
medium.comНа второй странице видим нормальный DVDRip — подходящий размер файла, никаких паролей.
medium.comНа этой странице есть BDRip и несколько нормальных DVDRip, судя по размеру и дате загрузки.
 medium.com
medium.comВыберите нужный фильм, нажмите «Загрузить NZB» (Download NZB) и импортируйте файл в NZBGet или SABnzbd, в которых необходимо ввести данные аккаунта Usenet. Когда скачивание закончится, программа сама распакует архивы и удалит их.
IRC / DCC / XDCC
IRC — старый протокол для текстового общения, из-за своей простоты по-прежнему популярный среди разработчиков, администраторов торрент-трекеров и любителей аниме. IRC поддерживает передачу файлов посредством DCC.
Сегодня существуют IRC-каналы и даже серверы, предназначенные исключительно для передачи файлов с помощью скрипта XDCC. Он популярен благодаря простоте использования и администрирования ботов: пользователю достаточно загрузить файл на FTP, а бот автоматически добавит его в индекс и уведомит об этом членов канала.
Есть специальные приватные IRC-сети с программами, новыми и не очень фильмами, музыкой и играми. Агентства по борьбе с нарушителями авторских прав об XDCC почти ничего не знают, поэтому в таких сетях можно найти много того, чего нет в других местах.
Индексаторы
У большинства XDCC-ботов есть веб-интерфейсы. Контент общей направленности можно найти здесь:
Аниме можно найти на nibl.co.uk.
Как качать через IRC
Вам потребуется IRC-клиент. Подойдёт почти любой — подавляющее большинство поддерживает DCC. Подключитесь к интересующему вас серверу и начинайте качать.
Крупнейшие серверы с книгами:
- irc.undernet.org, комната #bookz;
- irc.irchighway.net, комната #ebooks.
Фильмы:
- irc.abjects.net, комната #moviegods;
- irc.abjects.net, комната #beast-xdcc.
Западная и японская анимация:
- irc.rizon.net, комната #news;
- irc.xertion.org, комната #cartoon-world.
Для поиска файлов можно использовать команды !find или @find. Бот отправит результаты в виде личного сообщения. Если возможно, отдавайте предпочтение команде @search — она запускает специального бота, который предоставляет результаты поиска в виде одного файла, а не огромного потока текста.
Попробуем скачать «Как музыка стала свободной» (How Music Got Free) — книгу о музыкальной индустрии, написанную Стивеном Уиттом (Stephen Witt).
medium.comБот отреагировал на запрос @search и отправил результаты в виде ZIP-файла по DCC.
medium.comОтправляем запрос на скачивание.
medium.comИ принимаем файл.
medium.comЕсли вы нашли файл с помощью индексатора, то вам не нужно искать его на канале. Просто отправьте боту запрос на загрузку, используя команду с сайта индексатора.
DC++
В DC-сети все коммуникации осуществляются через сервер, называемый хабом. В ней можно искать конкретные типы файлов: аудио, видео, архивы, документы, образы дисков.
Делиться файлами в DC++ очень просто: достаточно поставить галочку напротив папки, к которой вы хотите предоставить общий доступ. За счёт этого можно отыскать что-то совершенно невообразимое — что-то, о чём вы сами уже давно забыли, но что может кому-то внезапно пригодиться.
Как качать через DC++
Подойдёт любой клиент. Для Windows лучшим вариантом является FlylinkDC++. Пользователи Linux могут выбирать между EiskaltDC++ и AirDC++ Web.
Подключитесь к разным хабам — чем больше, тем лучше. Список хабов есть в самом клиенте, также их можно найти по специальной ссылке.
Поиск и загрузка реализованы удобно: введите запрос, выберите тип контента, нажмите «Искать» и два раза щёлкните по результату, чтобы скачать файл. Также можно просмотреть список всех открытых пользователем файлов и загрузить все файлы из выбранной папки. Для этого нужно правой кнопкой мыши щёлкнуть по поисковому результату и выбрать соответствующий пункт.
 medium.com
medium.comЕсли что-то не нашли, попробуйте позже. Зачастую люди включают DC-клиент только когда им самим нужно что-то загрузить.
Индексаторы
Встроенный поиск находит только файлы в списках пользователей, находящихся в онлайн-режиме. Чтобы отыскать редкий контент, вам понадобится индексатор.
Единственный известный вариант — spacelib.dlinkddns.com, а также его зеркало dcpoisk.no-ip.org. Результаты представлены в виде magnet-ссылок, при нажатии на которые файлы сразу начинают скачиваться через DC-клиент. Стоит учитывать, что порой индексатор долгое время недоступен — иногда до двух месяцев.
eDonkey2000 (ed2k), Kad
Как и DC++, ed2k — протокол децентрализованной передачи данных с централизованным хабом для поиска и соединения пользователей друг с другом. В eDonkey2000 можно найти почти то же самое, что и в DC++: старые сериалы с разной озвучкой, музыку, программы, игры, старые книги для программистов, а также книги по математике и биологии. Впрочем, есть здесь и новые релизы.
Как качать через eDonkey2000 / KAD
Вам нужен ed2k-клиент. Хороший выбор для Linux — aMule. Пользователям Windows подойдёт eMule, несмотря на то что он не обновлялся с 2011 года.
Поиск и скачивание реализованы почти так же, как в DC++. Введите запрос, получите результаты от онлайн-пользователей, два раза щёлкните по нужному файлу, чтобы загрузить его.
Поищем «Мы живём на людях» (We Live In Public) — малоизвестный документальный фильм 2009 года, в котором рассказывается об интернете 90-х годов.
Введите запрос, нажмите «Пуск» (Start) и ждите, пока не появятся результаты.
 medium.com
medium.comДва раза щёлкните по файлу, чтобы начать загрузку.
medium.comСкачивание одного файла может длиться недели и даже месяцы. По какой-то непонятной причине у большинства пользователей ed2k невероятно низкая скорость соединения с интернетом, причём в онлайн они выходят лишь на несколько часов в неделю. Поэтому запаситесь терпением.
Soulseek
Это централизованная сеть для прямого обмена музыкой. Известна в IDM-сообществе и всё ещё находится в активной разработке. Здесь есть группы и приватные чаты, возможность делиться файлами с друзьями и поиск по битрейту.
Самый популярный клиент — официальный SoulseekQt. Есть также два неофициальных — Nicotine+ и Museek+.
BitTorrent DHT
Все современные BitTorrent-клиенты могут искать пиров через распределённую хеш-таблицу (DHT). Эта функция используется DHT-индексаторами: они получают торрент-файлы с данными из сторонних DHT-запросов и сохраняют их в свои базы. Через такие индексаторы можно искать редкие и неопубликованные торрент-файлы или похожие на них, но с большим количеством раздающих.
Список некоторых популярных индексаторов:
DHT-индексаторы известны тем, что долго не живут. Поэтому что-то из списка на момент публикации материала уже может не работать.
Сайты и FTP-серверы для обмена файлами
Почти в каждом регионе есть свои сайты для обмена файлами. Например, среди чехов популярен uloz.to, среди французов — zone-telechargement.ws, а среди поляков — chomikuj.pl.
FTP-индексаторы редко помогают найти что-то нужное, но попытаться всё равно можно:
Сайты для поиска на файлообменниках тоже малоэффективны, но не стоит забывать и о них:
Читайте также:
Поисковики файлов - что это, зачем и почему мы не слышали об этом раньше?
В Интернете доступно огромное количество серверов, работающих по протоколу FTP. (Чем протокол FTP отличается от HTTP/HTTPS, что будет, если заменить начало URL-адреса большинства сайтов — можно прочитать в любом специализированном справочнике, сейчас же интересно рассмотреть поисковики, индексирующие файлы на FTP-серверах).
Так как большинство FTP-серверов хранит данные в свободном доступе, без необходимости ввода логина и пароля, (а если с паролем — то создатели поисковой системы стараются узнать его и предоставить доступ своим пользователям) потому, что не каждый хост определен владельцем как хранилище приватных данных или данных сайта — очевидно, что возникает возможность просматривать и индексировать файлы, лежащие на серверах, допускающих анонимное подключение.
Вот, вкратце, и вся предыстория появление FTP-поисковиков: они «проходят» по доступным серверам, создают базу данных файлов, создают точную копию расположения и иерархического устройства директорий и предоставляют расположение файла в ответ на запрос пользователя с названием, фрагментом или другими параметрами файла, доступными к пониманию поисковой системы. Да, хорошие решения в это сфере ищут по любому фрагменту, доступному внутри файла.
Подобные поисковики — это история только про файлы. Без агрессивной рекламы, редиректов, всплывающих окон, внезапных звуков, громоздких фреймов и т.д. Просто ссылки на файлы — и все. Вы получаете комплект файлов, подключаетесь к серверу и загружаете к себе на компьютер нужные вам файлы через FTP-клиент или «проводник».
FTP-поисковики нужны для быстрого поиска, быстрой загрузки и концентрации ресурсов компьютера и пользователя исключительно на поиске файлов — без навязчивой рекламы, всплывающих окон и потери скорости.
Сразу стоит сказать, что рассматриваемые ниже сервисы — это далеко не полный список решений, доступных в нише поисковых систем, работающих по протоколу FTP, но это список наиболее крупных и мощных сервисов с обширной базой доступных серверов и мощным функционалом поиска.
Проект запущен более 20 лет назад. FS индексирует огромное количество российских FTP-серверов и тысячи зарубежных. Доступны только серверы с анонимным доступом. На момент написания данной статьи, индексная база составляет 31 595 791 файлов общим объемом 51565.6 Gb. Сервис регулярно обновляет индексы и следит за наличием файлов на серверах, что видно при поиске — неактивных ссылок в выдаче практически нет, так как они удаляются из базы индексации в течение нескольких недель
Данный поисковик предлагает искать файлы, каталоги, аудио и видео файлы, изображения и сервера по их именам. Данный сервис поддерживает поиск внутри домена, а также поиск конкретной папки на сервере, поиск по размеру, по маске, по регулярным выражениям или точному фрагменту текста. Кроме того сервис выдает всю информацию о файле и внесенных в него изменениях.
Проект Константина Айги, на который обязательно стоит обратить внимание, так как проект разрабатывал всего один человек с абсолютного нуля.
Во многом функционал этого поисковика совпадает с FileSearch.ru, уступает в количестве проиндексированных файлов, поддерживает обычный веб-поиск по сайтам, а также поиск внутри архивов.
На фоне остальных рассмотренных поисковиков выглядит пестрой рекламной доской объявлений, с нелогично составленными блоками и внешне (как и многие другие FTP-поисковики) похож на сайт двадцатилетней давности. По функционалу беднее, чем FileSearch.ru, выдает до 2000 результатов и не поддерживает поиск по регулярным выражениям.
Как уже было сказано выше, это далеко не все имеющиеся решения, позволяющие осуществлять FTP-поиск, а лишь список, состоящий из нескольких крупных проектов, и необходимый для получения общего представления о теме статьи. С появлением файлообменников и развитием таких поисковых гигантов как Google, изолированные FTP-поисковики постепенно уходят в прошлое, становятся заброшенными (частично или полностью) или вовсе уходят в историю развития интернет-технологий.
Скорее всего, буквально через несколько лет поиск по протоколу FTP уйдет в прошлое так как современные поисковые решения уже стирают границы, во всяком случае, для конечного пользователя и умеют находить и текстовые документы, и архивы, и музыку по напеваемому фрагменту, а с помощью нейронных сетей могут догадываться о том, что конкретно хочет увидеть конкретный пользователь на видео. К сожалению, основное преимущество FTP-поисковиков в скорости уничтожается, становится незаметным и неосязаемым с развитием вычислительной мощности, а также технологий индексации и хранения данных. Но, если вам интересен поиск файлов по FTP — теперь вы знаете, куда обратиться.
Как в интернете найти файл? Поиск файлов, документов в интернете
Как найти файл в интернете
Современному человеку очень часто требуется та или иная информация. Уже не принято подолгу сидеть в библиотеке в поисках определенной книги или изображения или бегать по всевозможным музыкальным магазинам города в поисках определенной песни. У передового человека попросту нет на это времени. Сегодня найти какой-либо файл можно в интернете. Причем на поиски Вы можете потратить от одной до нескольких минут. Спорить нет нужды, всемирная сеть – источник информации на тысячи тематик.

Составим пошаговую инструкцию, облегчающую Ваш поиск файла в интернете:
1. Вы должны располагать хотя бы минимальными сведениями о требуемом файле. Если это музыкальный или видео файл достаточно названия песни, фильма или музыкальной группы. Для упрощения самого процесса поиска компьютерщики разработали различные поисковые сервисы, именуемые в народе «поисковики». Самыми популярными на сегодня являются Яндекс или Гугл.
2. Вы должны зайти на сайт поисковика, вбив его адрес в адресную строку. Некоторые браузеры специально разработаны таким образом, что открывают тот или иной поисковик при открытии самого браузера. Если же этого не произошло, переходим на сайт поискового сервера самостоятельно.
3. Если Вы уже находитесь на странице поисковика, можете смело вбивать соответствующий запрос в форму поиска и жать кнопку «Найти». После этого поисковый сервер выдаст Вам перечень ресурсов, отвечающих условиям Вашего поиска. Ищете среди них необходимый файл.
Удачного Вам поиска в интернете, и наши рекомендации в помощь!
( Пока оценок нет )
Глава 2 Секреты поиска файлов в Интернете
Прежде чем станет возможной загрузка искомого файла, этот самый файл необходимо найти. А чтобы результат поиска был именно таким, каким вы его ожидаете — успешным, необходимо правильно и точно формулировать запросы в поисковой системе. В этой главе я рассмотрю примеры запросов и использовать буду Google — наиболее эффективный поисковый инструмент в Интернете. Но прежде чем приступать к поиску, сформулируйте свою цель — что вы конкретно хотите найти. Далее по тексту все поисковые запросы буду приводить «в кавычках», чтобы не путаться где запрос, а где просто текст.
Итак, цель ясна, и теперь пора приступать к поиску. Сложные запросы с операторами оставлю на потом, а сейчас открою некоторые несекретные приемы поиска. Допустим, вы ищете бесплатную программу Winamp. Самое простое, что можно сделать, — это загрузить главную страницу поисковой системы, к примеру Google (http://www.google.ru/), ввести в поле ввода запрос «winamp» и нажать кнопку Поиск (рис. 2.1).
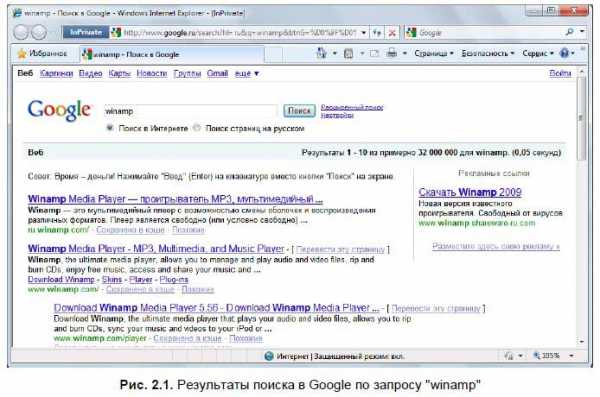
Как видно из результатов, первая ссылка (или несколько первых ссылок) в результатах приведет вас на официальный веб-сайт программы Winamp (об этом можно догадаться по адресам этих ссылок). Так как компании-разработчики в большинстве случаев оплачивают размещение своих вебсайтов в каталогах, рейтингах, поисковых системах и подобных службах, эти веб-узлы оказываются в числе первых результатов поиска по названию компании или продукта, ею разработанного. Таким образом, если вам требуется перейти на официальную страницу какого-либо программного продукта, достаточно выполнить поиск по его названию: «Adobe Photoshop», «Sony Vegas», «Mac OS X» и т. п. Точно так же можно найти официальные страницы звезд шоу-бизнеса, других персоналий, фильмов в прокате и т. п.: «Astral Projection», «Наутилус Помпилиус», «Ice Age», «Папины дочки».
В том случае, если требуется уточнить условия поиска, допустим, найти определенную версию программы Winamp 2.81 — так и пишите: «Winamp 2.81» или «Winamp 2.81 Скачать» или «Winamp 2.81 Download». Регистр букв при вводе поисковых запросов соблюдать необязательно.
Если вы не помните название программы, песни или видеофильма, можно попробовать выполнить поиск, указав в качестве запроса любые сведения, касающиеся искомой информации. Например, про фильм можно написать так «мультфильм про белку» или «фильм с Киану Ривз». Запросы, связанные с поиском программы, можно сформулировать так: «программа для видеомонтажа» или «редактор звуковых файлов». При поиске песни результативным может стать запрос с фрагментом текста песни.
Не стесняйтесь производить поиск, формулируя запросы так, как если бы вы задали вопрос живому человеку (ищу Winamp): «в какой программе можно слушать mp3 файлы», «как воспроизвести песню на компьютере» или «лучшая программа для mp3» (рис. 2.2).
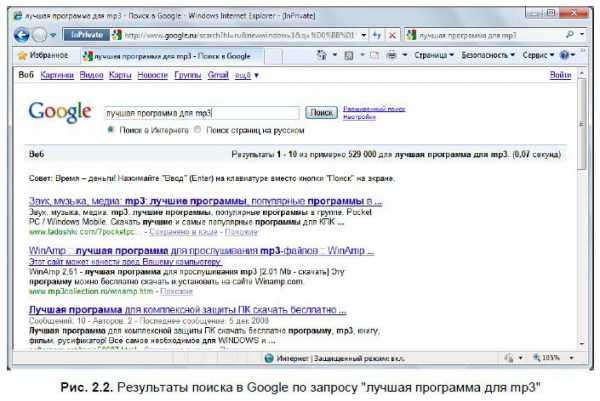
Эффективность поиска с подобными запросами обуславливается тем, что поисковые системы индексируют содержимое всех веб-сайтов автоматически, вне зависимости от того, оплачена ли эта услуга или нет, принадлежит сайт компании или обычному пользователю. Пользователи активно высказывают свое мнение о программах, книгах, аудио- и видеозаписях на форумах, в блогах, персональных страничках, и вы легко можете попасть на подобный ресурс, «предугадав» текст на нем и указав его в качестве запроса. Как видно из рис. 2.2, поисковый запрос «лучшая программа для mp3» привел к результату (имени программы и даже ссылки на ее дистрибутив) уже во втором пункте.
Данный текст является ознакомительным фрагментом.Читать книгу целиком
Поделитесь на страничкеОбзор программ для поиска документов и данных
Говорить о том, что в наше время информационных технологий и бесконечного роста объема данных, доступных как отдельно взятому человеку, так и обществу, существует много проблем с обработкой информации и ее поиском - это уже кощунство. Кто только эту тему не поднимает. И дабы не загружать вас субъективными и, частью, объективными суждениями, почерпнутыми из различных информационных источников касательно проблемы, я перейду непосредственно к ее решению. Сегодня поговорим о поиске. То есть о программах и серьезных информационных системах, осуществляющих поиск нужных нам документов и данных.
Апгрейд «прямого поиска»
Не так давно, когда деревья были большими, и информации даже в локальной сети предприятия было не так много, любой поиск осуществлялся банальным перебором горстки доступных файлов и последовательной проверкой их названий и содержимого. Такой поиск называется прямым, и программы (утилиты), использующие технологию прямого поиска, традиционно присутствуют во всех операционных системах и инструментальных пакетах. Но, даже мощности современных компьютеров не хватит для быстрого и адекватного поиска в гигантских объемах данных при прямом поиске. Перебор пары сотен документов на диске и поиск в громадной библиотеке и нескольких десятках почтовых ящиков - разные вещи. Поэтому, программы прямого поиска сегодня явно уходят на второй план - если речь идет об универсальных средствах.
Конечно, в корпоративном секторе такой вид поиска уже давно не востребован. Объемы не те. И, поэтому, уже который год, а в последнее время однозначно, технологии, способные осуществлять быстрый и точный поиск документов различных форматов и из различных источников, более чем актуальны. Не так давно "папа" Microsoft Билл Гейтс, позавидовав, судя по всему, феноменальному успеху Интернет-поисковика Google, на одной из пресс-конференций обнародовал желание софтверного (уже и не только) всячески способствовать, развивать и углублять создание поисковых систем и технологий. Но до создания какой-либо феноменально работающей программы от Microsoft или конкурентоспособного сервера в Интернет пока рано (MSN все равно до Google не дотягивает). Поэтому обратимся к уже существующим разработкам. Индекс, запрос, релевантность
В основе современных технологий лежат два основополагающих процесса. Во-первых, это индексация доступной информации и обработка запроса с последующим выводом результатов. Что касается первого, то любая программа (будь то настольный поисковик, корпоративная информационная система или Интернет поисковый движок) создает свою область поиска. То есть обрабатывает документы и формирует индекс этих документов (организованная структура, в которой содержится информация об обработанных данных). В дальнейшем именно созданный индекс используется для работы - быстрого получения списка нужных документов согласно запросу. Дальнейшее хоть и отнюдь не просто в плане технологии, но зато вполне понятно обычному пользователю. Программа обрабатывает запрос (по ключевому слову-фразе) и выводит список документов, в которых эта ключевая фраза содержится. Так как информация содержится в структурированном индексе, то обработка запроса проходит значительно (в десятки и сотни раз!) быстрее, чем в случае с прямым поиском (выборка документов осуществляется не перебором файлов, а анализом текстовой информации в индексе).
Найденные документы программа выводит в результирующем списке согласно релевантности - соответствия документа тексту запроса. В различных технологиях, конечно, присутствуют различные методы поиска и определения релевантности документа (количество "вхождений" слова и его частота упоминания в документе, соотношение этих параметров к общему количеству слов в документе, расстояние между словами фразы запроса в искомых файлах и так далее). На основе этих параметров определяется "вес" документа и, в зависимости от него тот или иной файл оказывается в списке результатов на определенной позиции. В случае с Интернет-поиском дело обстоит еще сложнее. Ведь в данном случае надо учитывать и множество иных факторов (Page Rank Google тому пример). Но это тема для отдельной статьи, поэтому Интернет трогать не будем.Обзор поисковиков
В данном материале рассмотрены возможности нескольких популярных программ поиска, которые могут похвастаться как приличными скоростями, так и неплохим функционалом. Но хвастаться в рекламных проспектах - это одно, а вот выдержать пристальный взгляд эксперта - совсем другое. А экспертов нашлось ни много, ни мало полный офис любителей поковырять софт на предмет его юзабилити. На подопытный компьютер (Athlon 2,2 MHz, с объемом оперативной памяти 1 Гб, 160 гигабайтным IDE жестким диском Seagate на 7200 оборотов в минуту и системой Windows XP) был установлен набор программ: dtSearch Desktop, Ищейка Проф Deluxe, Google Desktop Search, SearchInform, Copernic Desktop Search, ISYS Desktop. Для тестов была скомпонована текстовая база документов в форматах doc, txt и html общим размером ни много, ни мало, а 20 гигабайт. Группа товарищей под руководством вашего покорного слуги тестировала, сравнивала и делилась своими субъективными впечатлениями по каждой софтине. Сводное изложение полученных данных читайте ниже. dtSearch Desktop
Программа, претендующая, по заявлению разработчиков, на самую быструю, удобную и лучшую поисковую систему. Как, в общем, и все остальные из данного обзора. Интерфейс dtSearch довольно прост, но некоторые окна или вкладки несколько перегружены элементами, из-за чего создается впечатления сложности использования. Но на самом деле особых трудностей не возникает. Единственным действительно неприятным моментом является отсутствие поддержки софтиной русского языка (не смотря на то, что искать документы программа может на нескольких языках, интерфейс ее исключительно английский).
Зато dtSearch одна из немногих программ, которая может индексировать веб-страницы на заданную пользователем "глубину" (правда, с учетом "дозакупки" в комплект адд-она dtSearch Spider). Это кроме поддержки файлов на диске различных текстовых форматов и электронных писем из почтового ящика Outlook. В то же время, программа не умеет работать с базами данных, которые являются таким лакомым кусочком для поисковиков из-за больших объемов информации, находящихся в них, и широкого распространения в компаниях, а значит и в корпоративных сетях. Скорость индексирования документов dtSearch оказалась на должном уровне. Забегая вперед, скажу, что эта программа справилась с индексацией заданного объема информации на уровне с другим конкурсантом - iSYS - и поделила с ним второе место в списке самых быстрых систем. Тестовые 20 гигабайт информации dtSearch проиндексировала за 6 часов 13 минут, создав для нужд последующего поиска индекс размером 7.9 Гб.
Что касается возможностей поиска, то здесь они на должном уровне. Во-первых, в dtSearch присутствует морфологический поиск (поиск слова во всех его морфологических формах). Используя данную возможность, вы освобождаете себя от, скажем, таких раздумий, как "в каком же падеже было употреблено некоторое слово в необходимом мне документе?". Использование морфологического поиска почти всегда оправдано, поэтому должно присутствовать в любом профессиональном поисковике.
Поиск по звучанию является нестандартной возможностью даже для профессиональных поисковиков. Суть его заключается в том, что программа будет искать слова, которые звучат так же, как введенное вами слово. И что самое приятное, эта функция работает и для русского языка! Например, набирая слово "ухо" в поисковом запросе, вы увидите в результате не только слова "ухо", но и "уха".
Поиск с коррекцией ошибок - очень важная функция. Применяется для поиска слов, содержащих синтаксические ошибки - это могут быть как опечатки, так ошибки в документах, полученных при помощи систем распознавания символов, например. Простой пример - вы ищете слово клавиатура. В некотором документе содержится слово "клавиатупа", очевидно, что на самом деле это слово "клавиатура", просто человек при наборе текста опечатался. Так вот, поиск с коррекцией ошибок, это обнаружит и включит документ со словом "клавиатупа" в результат. Также в dtSearch есть настройка, позволяющая определять степень возможных ошибочных символов.
Поиск с использованием синонимов. Эта возможность использует список синонимов для различных слов. Так, например, введя слово "быстрый", программа также найдет слова "скоростной" и другие, являющиеся синонимами для слова "быстрый", если таковые, конечно, присутствуют в списке синонимов. Готового списка синонимов вместе с программой dtSearch не поставляется, однако есть возможность воспользоваться списками в Интернет (соответственно, требуется подключение, что не всегда удобно), либо можно составить свой список синонимов.
Кроме перечисленных возможностей, dtSearch может производить поиск с использованием фраз, состоящих из слов, соединенных логическими операциями. Каждому слову в запросе можно устанавливать свой "вес", то есть значимость. Полезная опция - использование словаря, состоящего из не значимых слов для того, чтобы не учитывать их при поиске, однако этот словарь также пуст и его придется заполнять самостоятельно.
Далее рассмотрим возможности программы при работе в сети. По сути, никаких специфических возможностей для работы с сетью dtSearch не предлагает. Тем не менее, использовать его в сети вполне возможно. Как вариант, можно создать некоторый индекс и положить его в общедоступную (расшаренную) папку. Саму же программу можно установить каждому пользователю на компьютер, либо выложить ее также на папку, открытую для общего доступа, и создать специальным образом ярлыки для каждого пользователя отдельно, используя параметры командной строки, предназначение которых описано в файле помощи, поставляемым с программой. Также, есть возможность автоматической установки программы в сеть при помощи MSI файла. При этом будут учтены настройки для каждого подключаемого пользователя.
В общем и целом - неплохая программа из разряда профессиональных поисковиков. Может претендовать на хорошую оценку, однако завоевание доверия и уважения со стороны пользователей может оказаться непростым для dtSearch в силу некоторых факторов (не все гладко с интерфейсом, русские пользователи обделены, нет ярких особенностей для работы с сетью). Что касается непосредственно поиска документов, то накладок с русским текстом у программы не было. Как не было их ни с заявленной морфологией, ни с нечетким поиском. Система вполне адекватно находила нужные документы и по простому запросу в одно слово и по использовании в качестве ключевой фразы пары абзацев, какого-либо документа.
Официальный сайт: www.dtsearch.com
Размер дистрибутива: 23 MbИщейка Проф Deluxe
Исходя из названия, можно догадаться, что поддержка русского языка в этой программе есть. Это уже приятно. Что касается интерфейса, в общем-то, он несколько необычен, но с виду весьма привлекателен. Другое дело - удобство. Весьма спорный критерий, но все же, наверно, многооконное решение - не самый удачный вариант (запрос вводится в одном окне, результат отображается в другом и тому подобное).
Ищейка использует все те же индексы для осуществления быстрого поиска, однако индексирование проходит значительно медленнее, нежели у других программ. Это весьма странно, особенно учитывая то, что возможности по обработке поисковых запросов у нее весьма слабые, а значит и структура индекса не сложная. Скорее всего, дело тут в неоптимизированных алгоритмах. Эта программа оказалась явным аутсайдером скоростей индексации и поиска: время, затраченное на создание индекса, в шесть раз больше, чем у тех же dtSearch и iSYS. Индексация 20 гигабайт текстов для ищейки вылилась в 38 часов 46 минут работы. А созданная "область поиска" заняла на жестком диске тот же размер, что и исходные данные за небольшим минусом - 19 гигабайт.
Ищейка может быть представлена как альтернатива стандартному поиску в Windows, на большее она вряд ли способна. О том, что первоочередная задача Ищейки - простейший поиск файлов указывает не только малое количество функций для анализа текста поисковых запросов и расширенный поиск по атрибутам файлов, но даже окно результатов, выдающее прямые ссылки на найденные файлы, а также на папки, содержащие эти файлы. Окно результатов не слишком информативно в том плане, что прочитать весь найденный файл можно, только запустив его, то есть, встроенного просмотрщика файлов у него нет. Зато выдается выдержка из файла, где встретилось искомое слово, в общем, такая схема отображения очень напоминает Интернет поисковики.
Говоря о конкретных возможностях по обработке поисковых запросов, стоит отметить, что здесь нет такого понятия как "искать текст", максимум, что можно искать - это фраза, хотя бы потому, что здесь нет многострочного поля ввода текста. Тем не менее, анализировать можно и введенную фразу и Ищейка предлагает нам здесь стандартный поисковый набор: логические операции, поиск по маске и цитатный поиск... не густо. В программе присутствуют некоторые зачатки морфологического поиска, но, наверно, настолько сырого, что он, скорее, мешает корректной работе (во время тестов было замечено множество накладок с неправильным использованием морфологии).
Зато программа позволяет указывать при поиске атрибуты файлов (дата документа, имя файла, имя папки), причем в этих запросах также можно использовать тот же поисковый набор. Также, можно осуществлять поиск писем, указывая параметры (От, Тема.... и т.п.).
Итак, с самим поиском разобрались, чем же еще интересным обладает программа, за что она получила столь многочисленные награды, по информации с официального сайта? Трудно сказать, что в ней такого особенного, скорее всего, интерфейс Ищейки располагает к себе (именно внешне, не говоря о юзабилити).
Операции с индексами весьма стандартны, приятным моментом является возможность обновления индексов по расписанию. Кроме того, индексы также могут использоваться в сети. С этого момента надо поподробнее.
Несмотря на примитивность поисковых запросов, программу можно использовать для поиска файлов, поэтому ее применение может быть оправдано в сетях. Хоть и с большой натяжкой, так как в большой сети приоритетной задачей является быстрый поиск данных с использованием сложных поисковых запросов из-за огромного количества информации - а со скоростью поиска и программы явно проблемы. Надо сказать, что работа с сетью у Ищейки продумана, как следует. Специально для этого предназначено отдельное приложение - Ищейка Сервер. Оно работает так же, как и просто Ищейка (поисковой движок у них один), только для документов, размещенных на центральном сервере или на общих ресурсах в корпоративной сети. Ищейка Сервер создает новые индексы на общих ресурсах, либо использует ранее созданные. Любой пользователь корпоративной сети может подключиться к Ищейке Сервер и использовать ее для доступа к любому документу (находящемуся в текущем индексе) используя Интернет браузер. Согласитесь, такая схема является крайне удобной: получается, что файлы в собственной сети можно искать таким же образом, как информацию в Интернете через, например, Google.
Оценивая все преимущества и недостатки этой программы, сам собой напрашивается вывод, что для корпоративных сетей ее возможностей, скорее всего, не хватит (несмотря доже на неплохую организацию работы с сетью), а вот для домашнего компьютера или даже для домашней сети она, в принципе, может и подойти. Хотя ни скорость работы, ни возможности по поиску не внушают оптимизма...
Официальный сайт на русском языке: www.isleuthhound.com/ru
Размер дистрибутива: 6 MbGoogle Desktop Search + GDS Enterprise
Щелкните по картинке, чтобы увеличить
Конечно, мы не могли обойти стороной такого именитого разработчика. Имя Google уже говорит о многом. Народ, годами пользовавшийся мощнейшим Интернет поисковиком, наверняка без единого сомнения решит установить на компьютере именно этот поисковик. Это же подумать: Google на домашнем компьютере! Однако, не поддаваясь на провокации с широко раскрученным брэндом, попробуем трезво, а главное объективно, рассмотреть возможности "настольного" поисковика от Google.
Первое, что бросается в глаза - отсутствие собственной оболочки для программы. Google Desktop Search по-прежнему находится в окне браузера, соответственно, весь интерфейс настольной версии достался софтине от старшего Интернет-брата. Хорошо это или плохо - спорный вопрос: кому-то по душе минимализм в дизайне этого поисковика, а кому-то хочется видеть полноценное приложение, наполненное всякого рода кнопочками и так далее.
Что бросается в глаза сразу после дизайна? А то, что этот самый Google Desktop Search начинает индексировать на компьютере все подряд, без всякого на то спроса! И что самое интересное, выбрать пути индексации при помощи Google Desktop Search невозможно. Придется скачать отдельную программку (TweakGDS), которая позволит несколько расширить настройки Google Desktop, в том числе и указать необходимые для индексации места. Хотя, пока со всем этим разберешься, стандартный винчестер он уже проиндексирует, так что такая настройка нужна скорее при работе с большими массивами данных, что очень актуально при использовании в корпоративных сетях (версии Enterprise). Однако не факт, что после скачивания TweakGDS, ваши проблемы решатся. Ведь для работы ей необходимы Microsoft .NET Framework и Microsoft Scripting Runtime. Да уж... установку, как и доступ к настройкам, можно было сделать и проще, хотя, наверно разработчиков можно понять: зачем писать что-то новое, когда есть уже готовый поисковик, портировал его на локальный компьютер и пускай пользователь "наслаждается", а известное имя сделает из "этого" очередной шедевр. Да ладно, закончим на этом лирическое отступление и перейдем к поиску.
Что касается анализа поисковых запросов и выдачи результатов, то здесь все абсолютно идентично Google в Интернет: такая же система отображения результатов, тот же стандартный набор логических операций для поисковых запросов. В общем Google Desktop Search, как и предыдущая программа, предназначен исключительно для поиска файлов - внутреннего просмотрщика этих файлов в нем, разумеется, нет. Количества форматов файлов, поддерживаемых Google Desktop Search, вполне достаточно, а также приятно, что он осуществляет поиск по посещенным Интернет страницам, беря данные из кэша. Скорости поиска и индексирования вполне приемлемые. Правда, для домашнего использования. С внушительными 20 гигабайтами текстов Google Desktop Search справилась за 8 часов 17 минут. Потратить несколько дней на обработку информации из корпоративной сети крупного предприятия не улыбается ни одному сисадмину. Из плюсов: размер создаваемого индекса оказался на уровне (4,5 Гб) с другим поисковиком, протестированном в этом обзоре - SearchInform.
Большое преимущество (или упущение - решать вам) Google Desktop Search заключается в том, что он поддерживает плагины, которые способны многое переменить к лучшему. Другое дело, что подключение плагинов и их настройка настолько усложняет задачу установки поисковика, что начинаешь задумываться - а надо ли все это, когда можно установить нормальную, полноценную программу, в которой уже будет все присутствовать. Ведь для задействования каждой возможности придется устанавливать новый плагин. Даже для того, чтобы программа могла полноценно работать с архивами, нужна отдельная примочка. Завораживает и прельщает бесплатность всех этих дополнительных модулей. Однако если не брать в расчет десктоповую версию поисковика, то грамотная настройка GDS Enterprise может оказаться вам не под силу - ведь не зря специалисты из Google предлагают свои услуги по настройке их же программного обеспечения для вашей сети всего лишь за 10000$.
Если же вы все-таки осилите процедуру настройки и установки (или заплатите 10000$ бригаде быстрого реагирования из конторы Google), то поймете, что сложность установки с лихвой компенсируется очень гибкими настройками при использовании в корпоративных сетях. Немаловажным моментом работы Google Desktop в корпоративной сети является использование групповых политик, что дает возможность установить настройки для каждого пользователя.
Подводя итог, следует сказать, что самое разумное применение для этой программы - домашний или рабочий компьютер. Ведь для обычного компьютера достаточно просто установить программу - остальное она сделает сама (вас даже ни о чем не спросит).
Тем не менее, Google Desktop Search Enterprise будет приемлема в случаях острой необходимости гибкой настройки сетевой политики для использования поисковика, при этом возможности обработки поисковых запросов будут на втором месте по значимости, а время (или деньги), затраченное на настройку программы, - на первом месте.
Официальный сайт: www.google.com
Размер дистрибутива вместе с TweakGDS: 1,2 MbCopernic Desktop Search
Щелкните по картинке, чтобы увеличить
Интерфейс программы вызывает исключительно положительные эмоции - все сделано в соответствии с общепринятыми стандартами, ничего лишнего, одним словом приятный дизайн. Новичку разобраться в интерфейсе Copernic Desktop Search будет очень просто. Хотя, несколько смущает то, что дизайнеры явно создавали интерфейс программы с учетом того, что программа будет работать в стандартной теме оформления Windows XP. При использовании же классической темы, программа смотрится уже не настолько симпатичной. Но это уже скорее дело вкуса.
При первом же запуске, программа предлагает создать индексы для поиска. Несколько необычным показалось то, что после выбора папок для индексирования, программа не предлагает нажать какую-нибудь кнопку, вроде "Начать индексацию", при этом индексация не начинается автоматически, только потом было замечено, что Copernic пытается начать индексацию во время простоя компьютера. Придется несколько покопаться в опциях программы, чтобы настроить все должным образом. Следует отметить, что здесь представлены довольно широкие возможности по настройке автоматического создания индекса: встроенный планировщик, возможность индексации во время простоя компьютера, в фоновом режиме, с низким приоритетом. Индексация проходила не слишком быстро - 10 часов 51 минута - это медленнее, чем в других поисковиках (кроме Ищейки, все же Copernic быстрее разработки iSleuthHound Technologies на порядок.
Теперь о структуре индекса. В общем, ничего особенного в ней нет. Есть возможность выбора типов файлов, причем, как в обобщенном виде, так и в подробном. То есть изначально вы можете выбрать, что требуется индексировать - Документы, Изображения, Видео, Музыку. На другой же вкладке окна опций будет возможность выбрать конкретно типы файлов по расширению. Дополнительно можно настроить индекс таким образом, чтобы, например, не индексировались картинки, размером менее 16х16 или не индексировались звуковые файлы длиной менее 10 секунд. Помимо индексации файлов из папок, Copernic умеет работать с электронными письмами и контактами из адресной книги Microsoft Outlook и Microsoft Outlook Express, возможна индексация Избранного и Истории из Internet Explorer.
Что касается возможностей поиска, то здесь они весьма слабы. Во время тестов даже было выявлено, что программа не ищет документы форматов txt и html на русском языке, позволяя найти их только по заголовкам, а отнюдь не по содержанию. Единственное, что программа предоставляет для повышения эффективности поиска - это использование стандартного набора логических операций, да и то, эта возможность была обнаружена экспериментальным путем, так как документирована она не была. Кстати, со справкой у программы также не все в порядке - она доступна только через Интернет, что, согласитесь, весьма неудобно, да и в сети справочной информации не слишком много. Видимо, разработчики решили, что простой интерфейс программы не предполагает наличия нормальной справки. Продолжая разговор о возможностях поиска, следует отметить, что, несмотря на слабый анализ запросов, программа предоставляет интересную систему поиска - пользователь может выбрать тип файлов (изображения, видео, музыка и т.п.), ввести поисковый запрос и выбрать атрибуты, присущие именно выбранному типу файлов. Например, для звуковых файлов, это могут быть значения из mp3 тегов (артист, альбом, дата и т.п.), для изображений, например, можно выбирать их размер (по разрешению), в общем, каждому типу - свои настройки. После осуществления поиска по определенному типу файлов, программа выдаст весьма информативный список в окне результатов, причем, если под ваш запрос попали файлы других типов, то вы сможете открыть и их, нажав на определенную ссылку.
Отдельно стоит упомянуть про окно отображения результатов. Под списком найденных файлов отображается содержимое этих файлов (аналогичная схема часто используется в почтовых клиентах). Правда, просмотр текста можно осуществлять лишь в родном формате, а режима отображения plain текста нет, что не всегда удобно, так как открытие документа в этом случае занимает больше времени. Зато, учитывая, что Copernic умеет искать изображения и музыку, здесь есть возможность просмотра и этих мультимедийных файлов.
Основные принципы работы этой программы описаны, теперь посмотрим, что Copernic Desktop Search может нам предложить для работы с сетью... В принципе смотреть можно очень долго, но увидеть что-либо вряд ли удастся. Другими словами, эта программа и не задумывалась как сетевая. Copernic Desktop Search - исключительно домашний поисковик.
Очевидно, что единственное (самое логичное) применение этой программы - домашний компьютер. Здесь она вполне справится со всеми незамысловатыми поисковыми запросами пользователей, состоящими из одного двух слов, найдет нужную информацию, а разделение поиска по типам файлов и поддержка мультимедийных файлов вместе с фоновой индексацией в режиме низкого приоритета вкупе с приятным интерфейсом только придают программе сил для завоевания доверия среди неискушенных пользователей.
Официальный сайт www.copernic.com
Размер дистрибутива: 2,6 MbISYS Desktop
Щелкните по картинке, чтобы увеличить
Очень мощная программа. По уровню оснащенности всевозможными функциями она находится где-то рядом со следующей в списке системой поиска SearchInform. При этом размер установочного файла более 40Mb! Сложно сказать, что можно было засунуть в такие размеры, ведь тот же SearchInform, с похожей функциональностью занимает 15Mb.
Процесс установки здесь также не слишком приятен, точнее даже не процесс установки. Еще до скачивания программы вас попросят зарегистрироваться, а иначе - никак. Далее, интерфейс. Сделан он весьма симпатично, ничего лишнего в глаза не бросается, однако - это впечатления человека, уже несколько привыкшего к нему. Разобраться, где и что находится, куда нажимать и где осуществить наконец-то поиск новичку будет непросто. Очень рекомендуется прочитать справку перед началом работы - сэкономите много нервов и времени. Ко всему прочему добавляется также полное отсутствие поддержки русского языка в программе. Нехорошо. Вдобавок, окна здесь не перегружены элементами управления, однако расплатиться за это пришлось многомодульностью и использованием дополнительных окон. Например, запросы для поиска вводятся при помощи запуска одной программы, а управление индексами производится при помощи уже другой программки. Поисковые запросы вводятся здесь также в отдельных, появляющихся окошках. Что лучше - перегруженность интерфейса или повсеместная многооконность - сказать трудно, скорее, это дело вкуса.
Что касается создания индексов, то программа предоставляет возможности по упрощению процесса установки опций для нового индекса. Эти возможности включают в себя несколько готовых шаблонов для создания индексов по папке "Мои документы", "Почта", "Почта и документы", "Определенная папка", "Папка с выбором типов файлов" и др. Такие шаблоны упрощают создание индексов на первом этапе. Утилита для работы с индексами обладает не слишком удачным интерфейсом, отпугивающим некоторой сложностью (это весьма субъективная оценка, по правде говоря), однако, если разобраться, он предоставляет множество полезных опций и в целом его использование особого труда не вызывает. ISYS Desktop умеет индексировать данные из различных источников данных, а также предоставляет множество гибких настроек для такой индексации. Среди дополнительных возможностей по индексированию: поддержка SQL, FTP, TRIM Context, WORLDOX 2002, скрипты. При создании индекса, если вы выбирали пункт "Папка с выбором типов файлов", у вас есть возможность выбрать типы файлов для индексации вручную (по расширению). Надо сказать, что поддерживаемых типов файлов просто огромное количество, однако свой тип (расширение) добавить в существующий список не удастся. Можно также отметить наличие планировщика индексации. Созданием индекса и обработкой 20 гигабайт информации ISYS Desktop занималась 6 часов 13 минут, в конечном итоге показав неплохое время и размер созданного файла - 7.9 Гб.
Возможности поиска у этой программы неплохи. То, что используется в ISYS, значительно мощнее обычной поддержки логических операций. Из продвинутых возможностей по поиску программа предлагает использование синонимов, фильтра сортировки (по пути, имени и дате создания файла). Набор логических операторов несколько шире стандартного набора. Помимо логических операций, программа позволяет работать со многими другими операторами, которые в принципе способны заменить некоторые виды поиска, например, поиск с синтаксическим разбором вполне можно заменить использованием специальных операторов. Очень удивило то, что в программе отсутствует поиск с использованием морфологии. Это серьезное упущение, так как эффективность поиска сильно повышается при использовании морфологического анализа. Кроме того, нет списка значимых слов, зато присутствует обширный список незначимых слов. Также заявлены такие функции при поиске как "приблизительный поиск" и "эвристический анализ".
ISYS предоставляет на выбор несколько видов поисковых запросов, именно, видов - визуальных. Это осуществлено при помощи разных видов окон для ввода поисковых запросов, однако, фактически, ни одно окно не позволяет использовать технологии, отличные от перечисленных выше.
Результаты поиска весьма информативны, отображаются в виде списка документов, отсортированных по релевантности. Ниже отображается предпросмотр выбранного документа. В отличие от Copernic Desktop Search, предпросмотр здесь доступен лишь в виде plain текста, добиться отображения документов в родном формате, будь то Word, Html или PDF так и не удалось, хотя это в принципе и не слишком критично. Программа позволяет разбивать найденные документы на группы по определенным признакам (по умолчанию они разделены по релевантности). Можно также просматривать уже найденные документы, выбирая отдельные папки (это удобно, когда результат выдает очень большое количество документов).
Использование программы в корпоративной сети также весьма оправдано, так как она предоставляет неплохие возможности по организации сетевого поиска. Система поиска основана на создании общедоступного индекса, который содержит проиндексированные данные с общедоступных сетевых ресурсов.
По сути, программа от ISYS достойна внимания, хотя бы ознакомления с ней. Эта программа - зрелый проект, обладающий огромным количеством функций (не всегда и не всем, конечно, они бывают нужны, но все же). Шансы на то, что в программе появятся некоторые улучшения со стороны обработки поисковых запросов, не известны, но и на данный момент ее можно рекомендовать практически для повсеместного использования. А учитывая, что для домашних систем она все же слишком грузная, то основные места ее инсталляции - корпоративные сети.
Официальный сайт: www.isys-search.com
Размер дистрибутива: 40 MbSearchInform
Щелкните по картинке, чтобы увеличить
Сразу начинать с описания интерфейса SearchInform, наверно, не стоит. Следует для начала описать процесс установки, а точнее одну его деталь: вы не сможете установить программу без подключения к Интернет. Дело в том, что перед первым запуском программа требует регистрации пользователя (бесплатной) и отправляет все введенные данные на сервер. Видимо, разработчикам пришлось принять такие меры в борьбе с пиратством, однако на удобстве установки это положительным образом не отразилось.
Интерфейс программы выполнен с соблюдением всех общепринятых правил, однако, на первый взгляд, несколько громоздок. Используя программу в первый раз, кажется, что он чересчур сложный, иногда бывает не просто вспомнить в каком меню или на какой вкладке находится нужная опция, однако, при более длительном использовании, интерфейс уже не кажется таким ужасающе сложным. Главное, предварительно почитать справку.
Немного разобравшись с интерфейсом, можно приступить к созданию индекса. Сам процесс весьма прост и скорость индексации даже на глаз значительно выше всех других поисковиков из обзора. Четкие цифры тестов показывают, SearchInform в два раза обогнала dtSearch и iSYS по скорости индексации! Программа проиндексировала предоставленные данные в размере 20 гигабайт за рекордное время - 3 часа 17 минут. Да и размер созданного индекса оказался самым небольшим 4.4 Гб - на 100 мегабайт меньше, чем у Google Desktop Search.
Программа поддерживает, помимо обычных файлов и папок, также индексацию электронных писем, подключение и индексацию баз данных (!) и других внешних источников (DMS, CRM), сразу же при индексации можно указать словарь для проведения морфологического поиска, а также индексироваться могут все атрибуты файлов. После создания индекса, при попытке провести первый пробный поиск документов, можно прийти в некоторое замешательство: "здесь присутствует два вида поиска, а какой же из них нужен мне?". Как уже говорилось ранее - главное прочитать справку, тогда все станет понятно. Программа действительно умеет осуществлять два вида поиска - это фразовый поиск и поиск документов, похожих по содержанию на текст запроса.
Описание всех основных функций для анализа поискового запроса было приведено выше, поэтому сейчас лишь перечислим возможности поиска, предоставляемые этой программой. Начнем с фразового поиска: конечно, морфологический поиск, цитатный поиск, логические операции, поиск с синтаксическим разбором слова (поиск по началу слова, по окончанию, по средней части, либо полное совпадение), смешанный цитатный поиск (когда все слова из запроса должны присутствовать в документе, но необязательно во введенном порядке), поиск с коррекцией ошибок, использование синонимов, "почти цитатный поиск" (поиск введенной фразы как цитаты, но между введенными словами могут присутствовать другие слова) и т.п. Некоторые из перечисленных опций имеют свои специфические настройки. Кроме того, есть возможность использования словаря незначимых слов, причем в программе уже есть готовый список этих слов, также для поиска можно использовать словарь приоритетных слов (его, разумеется, придется заполнять самостоятельно).
Вот, в принципе, вкратце пробежали все основные возможности фразового поиска.
Перейдем к рассмотрению особенности данной программы - поиска похожих документов. Разработчики утверждают, что это отнюдь не простой поиск текста, это именно "поиск похожих" - именно так он описан у них везде, да ладно, называть это можно как угодно - главное суть. Недолгие поиски в Интернете могут быстро дать информацию о том, что так называемый "поиск похожих" - новая разработка в области анализа текста. Эта система позволяет находить тексты, похожие именно по смысловому содержанию. Самым приятным оказалось то, что после проведения тестовых поисковых запросов, оказалось, что теория вполне совпадает с практикой! Программа действительно ищет похожие по содержанию документы и отображает их в списке, упорядочивая по проценту похожести.
Далее рассмотрим, что предлагает SearchInform (в частности, ее корпоративная версия SearchInform Corporate) для работы в корпоративной сети. Существуют два вида приложений: серверная часть и пользовательская. Серверная часть самостоятельно обрабатывает указанные индексы, а пользователи могут использовать их для поиска, в зависимости от назначенных им прав доступа. Пользователи могут быть настроены автоматически, используя учетные записи Windows (говоря профессиональным языком, SearchInform использует NTFS аутентификацию Windows), так и вручную (пользователей придется добавлять по отдельности). Каждому пользователю можно разрешить или запретить доступ к определенным индексам, можно также объединять пользователей в группы. В общем, настройки для работы в сети у SearchInform опережают по гибкости Google, а по удобству и простоте Ищейку Сервер.
Подводя итог по этой программе, можно порекомендовать ее к использованию в любых условиях. Тестирование показало, что скорость работы SearchInform достаточно высока, и она качественно анализирует запросы.
Официальный сайт: www.searchinform.com
Размер дистрибутива: 14,7 MbСравнение скоростей индексирования
| Система поиска | Время индексации | Размер индекса |
| Ищейка Проф Deluxe 4.5 | 38 часов 46 минут | 19 Гб |
| Isys Desktop 7.0 | 6 часов 13 минут | 7.9 Гб |
| DtSearch 7.0 | 6 часов 3 минуты | 8.6 Гб |
| Google Desktop Search Enterprise | 8 часов 17 минут | 4,5 Гб |
| Copernic Desktop Search * | 10 часов 51 минута | 7 Гб |
| SearchInform 1.5.02 | 3 часа 17 минут | 4.4 Гб |
* Большинство документов .html и .txt, содержащих русский текст, хоть и были проиндексированы, но кроме как по названиям, найти их было невозможно.Резюме
Все программы достойны внимания.
На основе тестов и внимательного осмотра каждой программы, представленной в обзоре, можно сделать определенные выводы. Итак, Google Desktop Search Copernic Desktop Search вполне подойдут неискушенному пользователю как домашние системы поиска информации. Они неплохо справляются с простыми запросами, не сильно загрузят пользователя настройками и, притом, совершенно бесплатны. Попытка Google выйти на рынок корпоративных поисковиков, пока не сильно оправдана: для полноценной работы программу нужно обвешивать дополнительными модулями, да и в настройке она далеко не проста. Поэтому, говорящие названия Desktop Search, что Copernic, что Google отставляю за ними нишу "настольных" поисковиков.
Правда, более мощные решения - dtSearch, iSYS и SearchInform тоже не лыком шиты и предлагают пользователям свои "настольные" версии. Но по сходной цене, в отличие от бесплатных софтин от Google и Copernic. Конечно, за мощность, скорость и функционал приходится платить. Но главный прицел разработчики dtSearch, iSYS и SearchInform делают, конечно, на корпоративный сектор. Работа с сетью, функциональность, скорость индексации и поиска – вот, что отличает эти продукты от своих "конкурентов". По результатам теста был определён фаворит - SearchInform. Программа предоставляет возможность искать похожие документы, обладает наибольшей скоростью индексирования и поиска, имеет хороший набор функций.
Как найти информацию в Интернете
Обновлено: 30.04.2020 компанией Computer Hope
Большую часть информации можно найти в Интернете с помощью поисковых систем. Поисковая машина - это веб-служба, которая использует веб-роботов для запроса миллионов страниц в Интернете и создает индекс этих веб-страниц. Пользователи Интернета могут затем использовать эти службы для поиска информации в Интернете. При поиске информации в Интернете имейте в виду следующее.
Объемный поиск в кавычках
Если вы ищете определенную фразу, например компьютерная справка , заключите фразу в кавычки, чтобы получить результаты для этой точной комбинации слов.Например, введите «компьютерная справка» в качестве критерия поиска, чтобы найти страницы, на которых эти два слова встречаются вместе.
Этот прием также можно использовать в частях вашего поискового запроса. Например, Microsoft «компьютерная справка» будет искать все, что содержит Microsoft , а также компьютерную справку вместе.
Вы можете включить в поиск несколько цитируемых фраз. Например, поиск "Microsoft Windows" "компьютерная справка" даст результаты для страниц, содержащих обе эти точные фразы.
Не забывайте о стоп-словах
Многие поисковые системы будут вырезать общие слова, которые они называют стоп-словами, для каждого выполняемого поиска. Например, вместо поиска , почему мой компьютер не загружается , поисковая система будет искать компьютер и загрузочный . Чтобы предотвратить удаление этих стоп-слов, заключите поиск в кавычки.
НаконечникЕсли стоп-слова не важны, не вводите их в поиск.
Ознакомьтесь с логическими значениями
Многие поисковые системы позволяют использовать логические операторы для фильтрации плохих результатов. Хотя общие логические значения включают «и», «или» и «не», большинство поисковых систем заменили эти ключевые слова символами. Например, чтобы найти справку по компьютеру без результатов, содержащих Linux, введите computer help -linux . "-Linux" указывает поисковой системе исключить любые результаты, содержащие слово Linux.
Знайте, какие функции доступны
Многие поисковые системы позволяют использовать дополнительный синтаксис для ограничения строк поиска.Например, Google позволяет пользователям искать ссылки на определенную страницу, набирая «ссылка:» и другие ключевые слова в начале поискового запроса. Например, чтобы узнать, кто связан с Computer Hope, введите: ссылка: https: //www.computerhope.com в поле поиска.
- Дополнительные советы и функции см. В разделе советов Google.
Попробуйте альтернативные поисковые системы
Наконец, если вы по-прежнему не можете найти то, что ищете, попробуйте другую поисковую систему.Список поисковых систем можно найти в статье о поисковых системах в Интернете.
.Скачать файлы из Интернета
Новый браузер, рекомендованный Microsoft, находится здесь
Получите скорость, безопасность и конфиденциальность с новым Microsoft Edge.
Учить больше
Существует несколько типов файлов, которые вы можете загружать из Интернета, среди прочего, документы, изображения, видео, приложения, расширения и панели инструментов для вашего браузера. Когда вы выбираете файл для загрузки, Internet Explorer спросит, что вы хотите сделать с файлом.Вот некоторые действия, которые вы можете сделать в зависимости от типа загружаемого файла:
-
Откройте файл, чтобы просмотреть его, но не сохраняйте его на свой компьютер.
-
Сохраните файл на своем ПК в папке для загрузки по умолчанию. После того, как Internet Explorer выполнит сканирование безопасности и завершит загрузку файла, вы можете выбрать: открыть файл, папку, в которой он хранится, или просмотреть ее в диспетчере загрузки.
-
Сохраните как файл с другим именем, типом или местом для загрузки на вашем ПК.
-
Запустите приложение, расширение или файл другого типа. После того, как Internet Explorer выполнит сканирование безопасности, файл откроется и запустится на вашем компьютере.
-
Отмените загрузку и вернитесь к просмотру веб-страниц.
Вы также можете сохранять файлы меньшего размера, например отдельные изображения, на свой компьютер. Щелкните правой кнопкой мыши изображение, ссылку или файл, который вы хотите сохранить, а затем выберите Сохранить изображение или Сохранить цель как .
Найдите файлы, которые вы скачали на свой компьютер
Download Manager отслеживает изображения, документы и другие файлы, которые вы загружаете из Интернета. Скачанные вами файлы автоматически сохраняются в папке «Загрузки».Эта папка обычно находится на диске, на котором установлена Windows (например, C: \ users \ your name \ downloads). Вы всегда можете переместить загрузки из папки «Загрузки» в другое место на вашем компьютере.
Чтобы просмотреть файлы, которые вы загрузили при использовании Internet Explorer, откройте Internet Explorer, нажмите кнопку Инструменты , а затем выберите Просмотр загрузок . Вы сможете увидеть, что вы скачали из Интернета, где эти элементы хранятся на вашем компьютере, и выбрать действия, которые нужно предпринять для ваших загрузок.
Изменить папку загрузки по умолчанию на вашем ПК
-
Откройте Internet Explorer, нажмите кнопку Инструменты , а затем выберите Просмотреть загрузки .
-
В диалоговом окне View Downloads выберите Options в нижнем левом углу.
-
Выберите другое место загрузки по умолчанию, выбрав Обзор , а затем нажав ОК , когда закончите.
Почему некоторые файлы не открываются в Internet Explorer
Internet Explorer использует надстройки, такие как Adobe Reader, для просмотра некоторых файлов в браузере. Если файл, которому требуется надстройка, не открывается, возможно, у вас более старая версия надстройки, которую необходимо обновить.
О загрузке и предупреждения о безопасности
Когда вы загружаете файл, Internet Explorer проверяет наличие признаков того, что загрузка является вредоносной или потенциально опасной для вашего ПК.Если Internet Explorer определит загрузку как подозрительную, вы получите уведомление, чтобы вы могли решить, сохранять, запускать или открывать файл. Не все файлы, о которых вас предупреждают, являются вредоносными, но важно убедиться, что вы доверяете сайту, с которого загружаете, и действительно хотите загрузить файл.
Если вы видите предупреждение системы безопасности, в котором говорится, что издатель этой программы не может быть проверен, это означает, что Internet Explorer не распознает сайт или организацию, которые просят вас загрузить файл.Убедитесь, что вы знаете издателя и доверяете ему, прежде чем сохранять или открывать загрузку.
Загрузка файлов из Интернета всегда сопряжена с риском. Вот некоторые меры предосторожности, которые вы можете предпринять, чтобы защитить свой компьютер при загрузке файлов:
-
Установите и используйте антивирусную программу.
-
Загружайте файлы только с сайтов, которым вы доверяете.
-
Если файл имеет цифровую подпись, убедитесь, что подпись действительна и файл находится в надежном месте.Чтобы увидеть цифровую подпись, выберите ссылку издателя в диалоговом окне предупреждения системы безопасности, которое открывается при первой загрузке файла.
Как загрузить весь веб-сайт для чтения в автономном режиме
Хотя в наши дни Wi-Fi доступен повсюду, время от времени вы можете оказаться без него. И когда вы это сделаете, могут быть определенные веб-сайты, которые вы хотите сохранить и получить к ним доступ в автономном режиме - возможно, для исследований, развлечений или для потомков.
Достаточно легко сохранить отдельные веб-страницы для чтения в автономном режиме, но что, если вы хотите загрузить целиком веб-сайта ? Что ж, это проще, чем вы думаете! Вот четыре изящных инструмента, которые вы можете использовать для загрузки любого веб-сайта для чтения в автономном режиме, не требуя никаких усилий.
Доступно только для Windows.
WebCopy от Cyotek берет URL-адрес веб-сайта и сканирует его на предмет ссылок, страниц и мультимедиа.Находя страницы, он рекурсивно ищет больше ссылок, страниц и мультимедиа, пока не будет обнаружен весь веб-сайт. Затем вы можете использовать параметры конфигурации, чтобы решить, какие части загружать в автономном режиме.
В WebCopy интересно то, что вы можете создать несколько «проектов», каждый из которых имеет свои собственные настройки и конфигурации.Это упрощает повторную загрузку множества разных сайтов в любое время, каждый раз одинаково и точно.
Один проект может копировать множество веб-сайтов, поэтому используйте их с упорядоченным планом (например,грамм. проект «Тех» по копированию технических сайтов).
Как загрузить весь веб-сайт с помощью WebCopy
- Установите и запустите приложение.
- Перейдите к File> New , чтобы создать новый проект.
- Введите URL-адрес в поле Website .
- Измените значение в поле Сохранить папку на место, где вы хотите сохранить сайт.
- Поэкспериментируйте с Project> Rules… (узнайте больше о правилах WebCopy).
- Перейдите к File> Save As… , чтобы сохранить проект.
- Щелкните Копировать веб-сайт на панели инструментов, чтобы начать процесс.
После завершения копирования вы можете использовать вкладку «Результаты», чтобы увидеть статус каждой отдельной страницы и / или медиафайла. На вкладке «Ошибки» отображаются все проблемы, которые могли возникнуть, а на вкладке «Пропущенные» показаны файлы, которые не были загружены.
Но наиболее важным является карта сайта, которая показывает полную структуру каталогов веб-сайта, обнаруженную WebCopy.
Чтобы просмотреть веб-сайт в автономном режиме, откройте проводник и перейдите в указанную вами папку для сохранения.Откройте index.html (или иногда index.htm ) в своем браузере, чтобы начать просмотр.
Доступно для Windows, Linux и Android.
HTTrack более известен, чем WebCopy, и, возможно, лучше, потому что он имеет открытый исходный код и доступен на платформах, отличных от Windows, но интерфейс немного неуклюжий и оставляет желать лучшего.Тем не менее, это работает хорошо, поэтому не позволяйте этому отвратить вас.
Как и WebCopy, он использует проектный подход, который позволяет копировать несколько веб-сайтов и сохранять их все организованными.Вы можете приостановить и возобновить загрузку, а также обновить скопированные веб-сайты, повторно загрузив старые и новые файлы.
Как загрузить веб-сайт с помощью HTTrack
- Установите и запустите приложение.
- Щелкните Next , чтобы начать создание нового проекта.
- Дайте проекту имя, категорию, базовый путь, затем щелкните Далее .
- Выберите Загрузить веб-сайты для действия, затем введите URL-адреса каждого веб-сайта в поле Веб-адреса , по одному URL-адресу в строке. Вы также можете сохранять URL-адреса в файле TXT и импортировать его, что удобно, если вы хотите повторно загрузить те же сайты позже.Щелкните Далее .
- Если хотите, настройте параметры, затем нажмите Готово .
После того, как все будет загружено, вы можете просматривать сайт как обычно, перейдя туда, где были загружены файлы, и открыв в браузере index.html или index.htm .
Доступно для Mac и iOS.
Если вы используете Mac, лучшим вариантом будет SiteSucker .Этот простой инструмент копирует целые веб-сайты и поддерживает ту же общую структуру, а также включает все соответствующие медиафайлы (например, изображения, PDF-файлы, таблицы стилей).
У него чистый и простой в использовании интерфейс, который как никогда не может быть проще: вы буквально вставляете URL-адрес веб-сайта и нажимаете Enter.
Одной из отличных функций является возможность сохранить загрузку в файл, а затем использовать этот файл для повторной загрузки тех же файлов и структуры в будущем (или на другом компьютере).Эта функция также позволяет SiteSucker приостанавливать и возобновлять загрузки.
SiteSucker стоит 5 долларов и не поставляется с бесплатной версией или бесплатной пробной версией, что является его самым большим недостатком.Для последней версии требуется macOS 10.13 High Sierra или новее. Более старые версии SiteSucker доступны для старых систем Mac, но некоторые функции могут отсутствовать.
Доступно для Windows, Mac и Linux.
Wget - это утилита командной строки, которая может получать все типы файлов по протоколам HTTP и FTP.Поскольку веб-сайты обслуживаются через HTTP, а большинство файлов веб-мультимедиа доступны через HTTP или FTP, это делает Wget отличным инструментом для копирования веб-сайтов.
В то время как Wget обычно используется для загрузки отдельных файлов, он может использоваться для рекурсивной загрузки всех страниц и файлов, обнаруженных на начальной странице:
wget -r -p https: // www.makeuseof.com Однако некоторые сайты могут обнаруживать и предотвращать то, что вы пытаетесь сделать, потому что копирование веб-сайта может стоить им большой пропускной способности.Чтобы обойти это, вы можете замаскироваться под веб-браузер с помощью строки пользовательского агента:
wget -r -p -U Mozilla https: // www.makeuseof.com Если вы хотите быть вежливым, вам также следует ограничить скорость загрузки (чтобы не перегружать пропускную способность веб-сервера) и делать паузу между каждой загрузкой (чтобы не перегружать веб-сервер слишком большим количеством запросов):
wget -r -p -U Mozilla --wait = 10 --limit-rate = 35K https: // www.makeuseof.com Wget входит в состав большинства систем на базе Unix.На Mac вы можете установить Wget с помощью одной команды Homebrew: brew install wget (как настроить Homebrew на Mac). В Windows вам нужно будет использовать эту портированную версию.
Какие сайты вы хотите скачать?
Теперь, когда вы знаете, как загрузить весь веб-сайт, вас никогда не поймают без того, что почитать, даже если у вас нет доступа в Интернет.
Но помните: чем больше сайт, тем больше загрузка.Мы не рекомендуем загружать огромные сайты, такие как MakeUseOf, потому что вам понадобятся тысячи МБ для хранения всех используемых нами мультимедийных файлов.
Лучше всего загружать сайты с большим количеством текста и небольшим количеством изображений, а также сайты, которые не добавляют регулярно новые страницы или не изменяются.Сайты со статической информацией, электронные книги в Интернете и сайты, которые вы хотите заархивировать на случай, если они выйдут из строя, - идеальный вариант.
Если вас интересуют дополнительные возможности для чтения в автономном режиме, ознакомьтесь с тем, как настроить Google Chrome для чтения книг в автономном режиме.А чтобы узнать о других способах чтения длинных статей вместо их загрузки, ознакомьтесь с нашими советами и рекомендациями.
Кредит изображения: RawPixel.ru / Shutterstock
Что означает FYP на TikTok?
Об авторе Джоэл Ли (Опубликовано 1598 статей)
Джоэл Ли (Опубликовано 1598 статей) Джоэл Ли - главный редактор MakeUseOf с 2018 года.У него есть B.S. Кандидат компьютерных наук и более девяти лет профессионального опыта написания и редактирования.
Ещё от Joel LeeПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
.Цифровая библиотека бесплатных и бесплатных книг, фильмов, музыки и Wayback Machine
4,7 В 4,7 В
14 декабря 2005 г. 12/05
от Аудио сообщества
Вам предлагается просмотреть или загрузить аудио в коллекцию сообщества.Все эти тысячи записей были предоставлены пользователями архива и членами сообщества. Пожалуйста, выберите лицензию Creative Commons во время загрузки, чтобы другие знали, что они могут (или не могут) делать с вашим аудио. Щелкните здесь, чтобы поделиться своим аудио! Поиск по стилям: блюз, кантри, электроника, экспериментальная музыка, хип-хоп, инди, джаз, рок, разговорная речь.
2,6 В 2,6Б
26 февраля 200502/05
от Интернет-архив
Вам предлагается просмотреть или загрузить свои видео в коллекцию Сообщества.Эти тысячи видео были предоставлены пользователями архива и членами сообщества. Эти видео доступны для бесплатного скачивания. Пожалуйста, выберите лицензию Creative Commons во время загрузки, чтобы другие знали, что они могут (или не могут) делать с вашим видео. Нажмите здесь, чтобы загрузить свое видео!
Тема: Движущиеся изображения
2 Б 2.0Б
18 янв.200501/05
от Интернет-архив
Эти книги внесены сообществом.Щелкните здесь, чтобы поделиться своей книгой! Для получения дополнительной информации и инструкций см. Help.archive.org/hc/en-us/articles/360002360111-Uploading-A-Basic-Guide Uploaders, обратите внимание: Archive.org поддерживает метаданные об элементах практически на любом языке, поэтому пока символы имеют кодировку UTF8. Поиск книг по языкам: Afar Books Afrikaans Books Akan Books Албанские книги Арабские книги Армянские книги Aymara Books Азербайджанские книги Balochi Books Bambara ...
Тема: Тексты
Коллекция американских библиотек включает материалы, предоставленные со всех концов Соединенных Штатов.Учреждения варьируются от Библиотеки Конгресса до многих местных публичных библиотек. В целом, этот сборник материалов приносит в общественное достояние холдинги, охватывающие многие аспекты американской жизни и науки. Значительные части этой коллекции были щедро спонсированы Microsoft, Yahoo! , Фонд Слоуна и другие.
Коллекция данных и различных носителей, переданных частными лицами Интернет-архиву.
LibriVox, основанная в 2005 году, представляет собой сообщество добровольцев со всего мира, которые записывают тексты, являющиеся общественным достоянием: стихи, рассказы, целые книги, даже драматические произведения на многих языках. Все записи LibriVox находятся в открытом доступе в США и доступны для бесплатной загрузки в Интернете. Если вы находитесь за пределами США, перед загрузкой ознакомьтесь с законом об авторских правах в вашей стране. Посетите веб-сайт LibriVox, где вы можете найти книги, которые вас интересуют.Вы можете искать или ...
535.2 м 535 м
16 июня 200506/05
от Интернет-архив Канады
Добро пожаловать на страницу канадских библиотек.Центр сканирования в Торонто был основан в 2004 году на территории Университета Торонто. С момента своего скромного начала Internet Archive Canada работала с более чем 250 учреждениями, предоставляя свои уникальные материалы с открытым доступом и распространяя эти коллекции по всему миру. От Архива сестер службы до Университета Альберты IAC оцифровал более 600 000 уникальных текстов по состоянию на сентябрь 2019 года. Многие тексты / коллекции ...
Тема: Тексты
Electric Sheep - это проект распределенных вычислений для анимации и развития фрактального пламени, который, в свою очередь, распространяется на подключенные к сети компьютеры, которые отображают их в качестве заставки.Процесс Процесс прозрачен для обычного пользователя, который может просто установить программное обеспечение в качестве заставки. В качестве альтернативы пользователь может более активно участвовать в проекте, вручную создав файл фрактального пламени для загрузки на сервер, где он преобразуется в видеофайл анимированного фрактального пламени ....
Тема: электрическая овца
Обзор: все исполнители · этот день в истории · средний рейтинг обзора · количество отзывов · дата просмотра -требовать потоковую передачу.В 2002 году Интернет-архив объединился с etree.org для создания архива живой музыки, чтобы сохранить и заархивировать как можно больше живых концертов для нынешнего и будущих поколений ...
Тема: Живая музыка
Изображения предоставлены пользователями Интернет-архива и членами сообщества. Эти изображения доступны для бесплатной загрузки. Пожалуйста, выберите лицензию Creative Commons во время загрузки, чтобы другие знали, что они могут (или не могут) делать с вашими изображениями.
Тема: изображения
Исследовательская библиотека Джона П. Робартса, обычно называемая Библиотекой Робартса, является основной библиотекой гуманитарных и социальных наук в Библиотеке Университета Торонто и крупнейшей отдельной библиотекой в университете. Библиотека, открытая в 1973 году и названная в честь Джона Робартса, 17-го премьер-министра Онтарио, содержит более 4,5 миллиона единиц книжных форм, 4,1 миллиона единиц микроформ и 740 000 других единиц.Здание библиотеки - один из самых ярких образцов бруталистской архитектуры в ...
Фольксономия: система классификации, основанная на практике и методе совместного создания тегов и управления ими для аннотирования и категоризации контента; эта практика также известна как совместная маркировка, социальная классификация, социальная индексация и социальная маркировка. Созданный Томасом Вандером Валом, он представляет собой набор фолка и систематики.Фолксоундомия: набор звуков, музыки и речи, полученный в результате усилий добровольцев по максимально широкому распространению информации. Потому что ...
Калифорнийская цифровая библиотека поддерживает сбор и творческое использование мировых стипендий и знаний для библиотек Калифорнийского университета и сообществ, которым они служат. Кроме того, CDL предоставляет инструменты, которые поддерживают создание информационных онлайн-сервисов для исследований, преподавания и обучения, включая сервисы, которые позволяют библиотекам UC эффективно обмениваться своими материалами и обеспечивать больший доступ к цифровому контенту.
Эти видеоролики о религии и духовности были предоставлены пользователями архива.
Добро пожаловать в коллекцию Netlabels в Интернет-архиве. Эта коллекция содержит полные, свободно загружаемые / потоковые, часто лицензированные Creative Commons каталоги «виртуальных звукозаписывающих компаний». Эти «сетевые лейблы» представляют собой некоммерческие организации, созданные сообществом и занимающиеся предоставлением высококачественной, некоммерческой, свободно распространяемой музыки в формате MP3 / OGG для онлайн-загрузки во множестве жанров.Стили включают: мелодичную электронику (например, Observatory Online, Please Do Something), минимальный хаус (...
(1 отзывов)
207,3 м 207 м
26 февраля 200502/05
от Интернет-архив
Для просмотра и скачивания доступны художественные фильмы, короткометражки, немое кино и трейлеры.Наслаждайтесь! Просмотрите список всех полнометражных фильмов, отсортированных по популярности. Хотите разместить художественный фильм? Во-первых, выясните, находится ли он в общественном достоянии. Прочтите этот FAQ, чтобы определить, является ли что-то PD. Если вы все еще не уверены, задайте вопрос на форуме ниже, указав как можно больше информации о фильме. У одного из наших пользователей может быть соответствующая информация.
Тема: Движущиеся изображения
Отсканированные книги из различных европейских библиотек.
Программы на & nbsp; Архив телевизионных новостей для исследовательских и образовательных целей. Эти программы позволяют пользователям выполнять поиск в коллекции телевизионных новостных программ, датируемых 2009 годом, для исследовательских и образовательных целей, таких как проверка фактов. Пользователи могут просматривать короткие клипы, делиться ссылками на индивидуальные короткие цитаты, вставлять индивидуальные короткие цитаты или брать копию полной программы.
(1 отзывов)
Смотрите тысячи фильмов из архива Prelinger! Prelinger Archives был основан в 1983 году Риком Прелингером в Нью-Йорке.За следующие двадцать лет он вырос в коллекцию из более чем 60 000 «эфемерных» (рекламных, образовательных, индустриальных и любительских) фильмов. В 2002 году коллекция фильмов была приобретена Библиотекой Конгресса США, Отделом кино, радиовещания и звукозаписи. Архивы Prelinger продолжают существовать, в них хранится около 11000 оцифрованных и ...
Kodi (ранее XBMC) - это бесплатное программное обеспечение для медиаплеера с открытым исходным кодом, разработанное XBMC Foundation, некоммерческим технологическим консорциумом.Kodi доступен для нескольких операционных систем и аппаратных платформ с программным 10-футовым пользовательским интерфейсом для использования с телевизорами и пультами дистанционного управления. Он позволяет пользователям воспроизводить и просматривать большинство потоковых мультимедиа, таких как видео, музыка, подкасты и видео из Интернета, а также все распространенные цифровые мультимедийные файлы из локального и сетевого хранилища ...
Коллекция программ APK (Android Package), загруженных разными пользователями.
Документы Управления США по патентам и товарным знакам предоставлены Think Computer Foundation.
Тема: Патент США
Элементы, включенные в службу поиска телевизионных новостей. Часть архива теленовостей.
147,9 млн 148 млн
27 марта 200403/04
от Благодарный мертвец
Просмотр: это только в · шоу только в потоке (SBD) · шоу для скачивания (AUD) · этот день в истории · средний рейтинг обзора · количество обзоров · дата просмотра · количество просмотров · поиск по форумам Созданная в 2004 году эта коллекция состоит из аудитории и деки записи.Нередко можно найти несколько версий одного и того же шоу. Для получения дополнительной информации см. FAQ. Коллекция Grateful Dead в настоящее время не открыта для публичной загрузки. Поиск шоу: загружаемые шоу - обычно ...
Тема: grateful dead, jam, rock, jerry garcia
Вдохновляющие открытия благодаря свободному доступу к знаниям о биоразнообразии. | Библиотека наследия биоразнообразия улучшает методологию исследований, совместно делая литературу по биоразнообразию доступной для всего мира как части глобального сообщества по биоразнообразию.BHL также является основным литературным компонентом Энциклопедии жизни. Библиотека наследия биоразнообразия (BHL) - это консорциум естественнонаучных и ботанических библиотек, которые сотрудничают в целях оцифровки унаследованной литературы ...
Фольксономия: система классификации, основанная на практике и методе совместного создания тегов и управления ими для аннотирования и категоризации контента; эта практика также известна как совместная маркировка, социальная классификация, социальная индексация и социальная маркировка.Созданный Томасом Вандером Валом, он представляет собой набор фолка и систематики. Folkscanomy: сборник книг и текстов, созданный благодаря усилиям добровольцев по максимально широкому распространению информации. Потому что ...
Коллекция Vintage Software объединяет различные усилия групп по классификации, сохранению и предоставлению исторического программного обеспечения. Эти старые программы, многие из которых работают на неработающем и редком оборудовании, предназначены для изучения, образования и исторической справки.& nbsp;
Internet Arcade - это веб-библиотека аркадных (монетных) видеоигр с 1970-х по 1990-е годы, эмулированная в JSMAME, части пакета программного обеспечения JSMESS. Содержая сотни игр, самых разных жанров и стилей, Arcade обеспечивает исследования, сравнение и развлечения в сфере Video Game Arcade. Коллекция игр варьируется от видеоигр раннего «бронзового века» с черно-белыми экранами и простыми звуками до масштабных...
The Magazine Rack - это собрание оцифрованных журналов и ежемесячных публикаций.
бесплатных книг: загрузка и потоковая передача: электронные книги и тексты: Internet Archive
Эти книги внесены сообществом. Щелкните здесь, чтобы поделиться своей книгой! Для получения дополнительной информации и инструкций см. Help.archive.org/hc/en-us/articles/360002360111-Uploading-A-Basic-Guide Uploaders, обратите внимание: Archive.org поддерживает метаданные об элементах практически на любом языке, поэтому пока символы имеют кодировку UTF8. Поиск книг по языку: Afar Books Afrikaans Books Akan Books Албанские книги Арабские книги Армянские книги Aymara Books Азербайджан Книги Balochi Books Bambara...
Тема: Тексты
Коллекция американских библиотек включает материалы, предоставленные со всех концов Соединенных Штатов. Учреждения варьируются от Библиотеки Конгресса до многих местных публичных библиотек. В целом, этот сборник материалов приносит в общественное достояние холдинги, охватывающие многие аспекты американской жизни и науки. Значительные части этой коллекции были щедро спонсированы Microsoft, Yahoo! , Фонд Слоуна и другие.
Здесь представлены дополнительные коллекции отсканированных книг, статей и других текстов (обычно сгруппированных по темам).
535 М 535 М
-
от Интернет-архив Канады
Добро пожаловать на страницу канадских библиотек.Центр сканирования в Торонто был основан в 2004 году на территории Университета Торонто. С момента своего скромного начала Internet Archive Canada работала с более чем 250 учреждениями, предоставляя свои уникальные материалы с открытым доступом и распространяя эти коллекции по всему миру. Из архива сестер служения в Университет Альберты IAC оцифровал более 600 000 уникальных текстов по состоянию на сентябрь 2019 г. Многие тексты / коллекции ...
Тема: Тексты
Джон П.Исследовательская библиотека Робартса, обычно называемая Библиотекой Робартса, является основной библиотекой гуманитарных и социальных наук в Библиотеке Университета Торонто и крупнейшей отдельной библиотекой в университете. Библиотека, открытая в 1973 году и названная в честь Джона Робартса, 17-го премьер-министра Онтарио, содержит более 4,5 миллиона единиц книжных форм, 4,1 миллиона единиц микроформ и 740 000 других единиц. Здание библиотеки - один из самых ярких образцов бруталистской архитектуры в ...
Калифорнийская цифровая библиотека поддерживает сбор и творческое использование мировых стипендий и знаний для библиотек Калифорнийского университета и сообществ, которым они служат.Кроме того, CDL предоставляет инструменты, которые поддерживают создание информационных онлайн-сервисов для исследований, преподавания и обучения, включая сервисы, которые позволяют библиотекам UC эффективно обмениваться своими материалами и обеспечивать больший доступ к цифровому контенту.
Отсканированные книги из различных европейских библиотек.
Документы Управления США по патентам и товарным знакам предоставлены Think Computer Foundation.
Тема: Патент США
Вдохновляющие открытия благодаря свободному доступу к знаниям о биоразнообразии. | Библиотека наследия биоразнообразия улучшает методологию исследований, совместно делая литературу по биоразнообразию доступной для всего мира как части глобального сообщества по биоразнообразию. BHL также является основным литературным компонентом Энциклопедии жизни. Библиотека наследия биоразнообразия (BHL) - это консорциум естественнонаучных и ботанических библиотек, которые сотрудничают с целью оцифровки унаследованной литературы...
Фольксономия: система классификации, основанная на практике и методе совместного создания тегов и управления ими для аннотирования и категоризации контента; эта практика также известна как совместная маркировка, социальная классификация, социальная индексация и социальная маркировка. Созданный Томасом Вандером Валом, он представляет собой набор фолка и систематики. Folkscanomy: сборник книг и текстов, созданный благодаря усилиям добровольцев по максимально широкому распространению информации.Потому что ...
The Magazine Rack - это собрание оцифрованных журналов и ежемесячных публикаций.
Эта библиотека книг, аудио, видео и других материалов из Индии и об Индии курируется и поддерживается Public Resource. Цель этой библиотеки - помочь студентам и ученикам, которые учатся на протяжении всей жизни в Индии, в их стремлении к образованию, чтобы они могли улучшить свой статус и свои возможности и обеспечить для себя и других справедливость, социальную, экономическую и политическую.Эта библиотека была размещена только для некоммерческих целей и способствует добросовестному использованию ...
Сборник научной литературы, созданный экспертами и профессионалами своего дела. Включены диссертации, книги, рефераты и статьи.
Темы: академический, научный, официальные документы, ученый, научный, экспертная оценка, jstor, arxiv, диссертация, ...
Вопрос или комментарий о оцифрованных объектах Библиотеки Конгресса, представленных на этом веб-сайте? Воспользуйтесь формой "Задайте вопрос библиотекарю" Библиотеки Конгресса.& nbsp; & nbsp; & Nbsp; Библиотека Конгресса - крупнейшая в мире библиотека, предлагающая доступ к творческой деятельности Соединенных Штатов и обширным материалам со всего мира как на месте, так и в Интернете. Это главное исследовательское подразделение Конгресса США и местонахождение Бюро регистрации авторских прав США. Изучить ...
Проект универсальной библиотеки, иногда называемый проектом «Миллион книг», был инициирован Хайме Карбонеллом, Раджем Редди, Майклом Шамосом, Глорианой Сент-Клер и Робертом Тибадо из Университета Карнеги-Меллона.Правительства Индии, Китая и Египта помогают финансировать эти усилия посредством сканирующих предприятий и персонала. Интернет-архив отправил в Индию 100 тысяч книг из публичной библиотеки Канзас-Сити вместе с серверами. Правительство Индии отсканировало соответствующие книги. В ...
Бесплатные книги для & nbsp; люди с ограниченными возможностями, влияющие на чтение. & nbsp; Если у вас есть инвалидность, которая мешает читать печатный текст, все эти книги могут быть мгновенно доступны в вашем браузере или через защищенную загрузку.Хотите доступ? Физические лица Если вы хотите подать заявку на доступ (это бесплатно), & nbsp; убедитесь, что у вас есть учетная запись Archive.org, а затем & nbsp; заполните эту форму, чтобы связаться с Vermont Mutual Aid Society. Если вы связаны с какой-либо из ...
Тема: печать отключена
Книги предоставлены Интернет-архивом.
Тема: Интернет-архив книг
Документы в этом сборнике получены из федеральных судов США.Большая коллекция поступила из проекта федерального правительства по общедоступному доступу к судебным электронным записям (PACER). Сервисный центр PACER - это централизованный центр регистрации, выставления счетов и технической поддержки Федеральной судебной системы для электронного доступа к записям окружных судов, банкротств и апелляционных судов США. Для получения дополнительной информации о проекте RECAP посетите https://www.recapthelaw.org
Тема: федеральные правовые данные
Книги Бостонского библиотечного консорциума.См. Облако тегов для коллекции Консорциума Бостонских библиотек.
Книги из этой коллекции могут получить во временное пользование зарегистрированные посетители. & nbsp; Вы можете читать книги в Интернете в своем браузере или, в некоторых случаях, загружать их в Adobe Digital Editions, бесплатное программное обеспечение, используемое для управления кредитами. & nbsp; Обратите внимание, что работы в этой коллекции защищены законом об авторском праве (Раздел 17 Кодекса США), и копирование, распространение или продажа получателем с целью получения прибыли или без нее не разрешены, если только это не разрешено правообладателем или законом.См. Ответы на часто задаваемые вопросы о ...
Сделайте снимок, он прослужит дольше По мере того, как книги стареют и начинают разваливаться, библиотекари зависят от микроформ, чтобы сохранить свой контент на будущее. Крошечные фотографии на длинных полосах пленки (микрофильм) или маленькие карточки с пленкой (микрофиши) - это все, что осталось от сотен тысяч документов, распавшихся за последнее столетие. Хотя микропленка идеально подходит для хранения и защиты этого материала, она не обеспечивает большого доступа.Следуя своей миссии по обеспечению ...
Библиотека медицинского наследия (MHL), цифровая библиотека, созданная совместно некоторыми ведущими медицинскими библиотеками мира, способствует свободному и открытому доступу к качественным историческим ресурсам в медицине. Наша цель - предоставить средства, с помощью которых читатели и ученые из множества дисциплин могут изучить взаимосвязанную природу медицины и общества, как для информирования современной медицины, так и для улучшения понимания мира, в котором мы живем.Растущая коллекция оцифрованных ...
Темы: исторические медицинские книги, история медицины
Оригиналы этих книг находятся в библиотеке Корнельского университета. Большинство из них были оцифрованы в 2008 году при финансовой поддержке корпорации Microsoft. Сканирование было выполнено Kirtas Technologies; OCR было выполнено Интернет-архивом, а производные форматы созданы им. Последовали и другие проекты оцифровки, пополнившие эту коллекцию.Один из таких проектов включал книги и журналы по наукам о жизни и естественной истории с целью добавления в Библиотеку наследия биоразнообразия или ...
Эта библиотека книг, аудио, видео и других материалов из Индии и об Индии курируется и поддерживается Public Resource. Цель этой библиотеки - помочь студентам и ученикам, которые учатся на протяжении всей жизни в Индии, в их стремлении к образованию, чтобы они могли улучшить свой статус и свои возможности и обеспечить для себя и других справедливость, социальную, экономическую и политическую.Эта библиотека была размещена только для некоммерческих целей и способствует добросовестному использованию ...
Фольксономия: система классификации, основанная на практике и методе совместного создания тегов и управления ими для аннотирования и категоризации контента; эта практика также известна как совместная маркировка, социальная классификация, социальная индексация и социальная маркировка. Созданный Томасом Вандером Валом, он представляет собой набор фолка и систематики.Folkscanomy: сборник книг и текстов, созданный благодаря усилиям добровольцев по максимально широкому распространению информации. Потому что ...
Федеральная библиотечно-информационная сеть (FEDLINK) - это организация федеральных агентств, работающих вместе для достижения оптимального использования ресурсов и возможностей федеральных библиотек и информационных центров путем продвижения общих служб, координации и совместного использования имеющихся ресурсов, а также обеспечения непрерывного профессионального образования для федеральных библиотечный и информационный персонал.FEDLINK служит форумом для обсуждения политик, программ, процедур и технологий, которые влияют на федеральные ...
Книги отсканированы в Шэньчжэне и Пекине, Китай.
Тема: книги
Интернет-архив национальной безопасности фокусируется на файлах, собранных из архива That 1, MuckRock, NARA, архива национальной безопасности в GWU, колледжа Худ, Черного хранилища, правительственного чердака, безбумажных архивов, Эрни Лазара, Международного центра исследований 11 сентября. а также различные другие историки, коллекционеры и активисты.
Темы: Правительство, Правительственные документы, Закон о свободе информации, Закон о свободе информации, Национальная безопасность, Закон ...
Эта коллекция содержит цифровые версии документов правительства США, а также других государственных документов.
Книги из Публичной библиотеки округа Аллен. Книги, оцифрованные Интернет-архивом Центра генеалогии публичной библиотеки округа Аллен в Форт-Уэйн, штат Индиана.Как пользоваться каталогами микрофильмов переписи населения НАРА Скоро! Индекс Soundex для переписи. Как использовать микрофильм системы индексирования Soundex, оцифрованный Интернет-архивом для публичной библиотеки округа Аллен: Все микрофильмы ACPL в Интернете. Перепись США 1930 года. Перепись населения США 1920 года. Перепись населения США 1910 года. 1900 США ...
Материалы раннего журнала JSTOR - это подборка журнальных материалов, опубликованных до 1923 г. в США и до 1870 г. в других странах.Он включает в себя дискуссии и исследования в области искусства и гуманитарных наук, экономики и политики, а также по математике и другим наукам - почти 500 000 статей из более чем 200 журналов. Он был загружен в Интернет-архив в 2013 году. Материалы раннего журнала JSTOR были бесплатно доступны на сайте www.jstor.org с сентября 2011 года. Содержание раннего журнала обновлено ...
Книги предоставлены Бостонской публичной библиотекой. Бостонская публичная библиотека (BPL), основанная в 1848 году постановлением Великого общего суда штата Массачусетс, была первой крупной бесплатной муниципальной библиотекой в Соединенных Штатах.В 1839 году французский чревовещатель М. Николас Мари Александр Ваттемар стал первым сторонником публичной библиотеки в Бостоне, когда он предложил идею обмена книгами и печатными изданиями между американскими и французскими библиотеками. Мэр города Бостона Джозайя Куинси, ...
Университет Альберты (U of A) - государственный исследовательский университет, расположенный в Эдмонтоне, Альберта, Канада. Основанный в 1908 году Александром Кэмероном Резерфордом, первым премьер-министром Альберты, и Генри Маршаллом Тори, ее первым президентом, он широко известен как один из лучших университетов Канады.Главный кампус охватывает 50 городских кварталов с более чем 90 зданиями прямо через реку Северный Саскачеван от центра Эдмонтона. Библиотечная система Университета Альберты получила огромный импульс ...
С 1848 года Оттавский университет является канадским университетом. Расположенный в самом сердце столицы страны, университет превратился в динамичный «центр обучения» с общим населением, включая студентов, преподавателей и вспомогательный персонал - 40 000 человек.Крупнейший двуязычный университет в Северной Америке, университет играет важную роль в культурном и экономическом развитии столичного региона. Livres de l’Université d’Ottawa L’Université d’Ottawa est ...
Коллекция публикаций начала 17 века о Канаде, написанных и опубликованных канадцами, отсканированных с микрофиш. Полный набор записей метаданных для этой коллекции можно загрузить по адресу: & nbsp; https: // doi.org / 10.7939 / DVN / 10710 Коллекция монографий CIHM представляет собой важную часть нашей национальной истории. Это собрание публикаций начала 17 века о Канаде, написанных и опубликованных канадцами. Чтобы ...
Тема: Университет Альберты - Коллекция монографий CIHM
Проект Gutenberg был начат в 1971 году Майклом Хартом как проект сообщества по обеспечению свободного доступа всех текстовых версий книг.
Тема: Тексты
Газеты в этом сборнике были отсканированы в рамках пилотного проекта с использованием микрофильмов и микрофиш. После использования сканера микрофильмов / микрофишей для создания цифрового изображения каждой страницы мы обрабатываем полученные изображения таким образом, чтобы каждая катушка содержалась в одном элементе с легко управляемыми файлами. Несколько примеров можно найти в: The New York Times (16 октября, 31 октября 1915 г.) The New York Times (1-15 июля 1919 г.) The New York Times (1-15 мая 1915 г.)
Открытый доступ к электронным печатным изданиям по физике, математике, информатике, количественной биологии, количественным финансам и статистике.arXiv принадлежит и управляется Корнельским университетом, частным некоммерческим образовательным учреждением. arXiv финансируется Библиотекой Корнельского университета, Фондом Саймонса и организациями-членами.
Темы: физика, математика, информатика, количественная биология, количественные финансы и статистика, ...
С ребрендингом вычислительной мощности и машин как чего-то желанного в доме, а не только в мастерской, ряд факторов повлиял на продажу этих машин и их программного обеспечения растущей и большой группе клиентов.Помимо введения более элегантных футляров и увеличения присутствия все более крупных фирм, можно привести веский аргумент в пользу того, что одной из движущих сил было распространение компьютерных журналов и информационных бюллетеней, которые служили центральным печатным домом для написания ...
Научно-информационный центр Герштейна - флагманская библиотека Университета Торонто, поддерживающая естественные и медицинские науки.Крупнейшая академическая библиотека науки и здравоохранения в Канаде, Герштейн имеет коллекцию из более чем 945 000 печатных томов журналов и книг, а также предоставляет доступ к более чем 100 000 онлайн-журналов и книг. Коллекция Научно-информационного центра им. Герштейна состоит в основном из материалов по естественным наукам, включая науки о здоровье, медицину, физику, ...
Государственный департамент Соединенных Штатов (DOS), часто называемый Государственным департаментом, является федеральным исполнительным департаментом Соединенных Штатов, отвечающим за международные отношения Соединенных Штатов, аналогично министерствам иностранных дел других стран.Департамент был создан в 1789 году и был первым учрежденным исполнительным отделом. Исполнительная власть и Конгресс США несут конституционную ответственность за внешнюю политику США. Департамент продвигает цели США и ...
Темы: Государственный департамент, Государственный департамент, Государственный департамент, Государственный департамент, Государственный департамент США
Загрузки от обычных пользователей ARCHIVE.ORG, связанные с исламской культурой, исследованиями и смежными предметами.Из статьи Википедии об исламоведении: исламоведение относится к академическому изучению ислама. Исламоведение можно рассматривать как минимум с двух точек зрения: с точки зрения секулярности, исламоведение - это область академических исследований, предметом которой является ислам как религия и цивилизация. С традиционной исламской точки зрения, исламоведение - это обобщающий термин для "религиозных ...
Как член Open Content Alliance, университетская библиотека Университета Северной Каролины в Чапел-Хилл вносит цифровой контент в Интернет-архив из нашей коллекции редких книг и коллекции Северной Каролины, включая редкие испанские драмы, ежегодники UNC и Северной Каролины. законодательные материалы.Также представлены другие предметные области, такие как ранние медицинские журналы Северной Каролины и судебные материалы Северной Каролины. Участие UNC в Open Content Alliance составляет ...