Как изменить кодировку в файле pdf
Как изменить кодировку в pdf
У меня есть проблема с PDF, с которого я пытаюсь скопировать текст . У меня есть этот текст в формате PDF, и мне нужно вставить его в страницу HTML, проблема в том, что при копировании текста некоторые буквы ( слова с диакритическими знаками (например, Ț или Ș) пропускаются, слова, содержащие их, больше не верны .
Я узнал, что это потому, что PDF использует кодировку шрифтов ASNI, а браузер использует UNICODE . как я могу изменить кодировку ANSI в PDF, чтобы преобразовать ее в UNICODE?
Ответы
Если проблема действительно в том, что вы описываете, Notepad ++ должен делать то, что вы хотите, это бесплатно. Создайте новый документ в Notepad ++, убедитесь, что в меню «Кодирование» выбран «Кодировать в ANSI», вставьте туда текст, затем выберите «Преобразовать в UTF-8 без спецификации» в меню «Кодирование».
Вы также можете попробовать использовать Decoder , бесплатный онлайн-инструмент для решения проблем кодирования. Это на русском языке, но использование довольно простое – вставьте искаженный текст в текстовое поле и нажмите кнопку с надписью «Расшифровать».
Автор: Zheka. Дата публикации: 17 июля 2019 . Категория: Офис. Просмотров: 2191

Электронные книги вошли в нашу повседневную жизнь и продолжают укреплять свою позицию. PDF – один из самых популярных форматов, который можно встретить на интернет просторах, посещая сайты и магазины. Но бывают досадные ситуации, когда текст, который мы хотим скопировать, просто превращается в непонятные символы. Кто-то на них говорит иероглифы, другие – кракозябры . Как же исправить такую ситуацию?
Я не уверен, что следующие советы помогут для всех решить проблему, но частичное решение ее все же возможно.
Давайте сразу отбросим отсканированые и нераспознанные PDF документы, из которых просто невозможно скопировать текст. Это равносильно попытке копирования текста из обычной фотографии, сделанной на ваш смартфон. В таком случае текст нужно распознать специальной программой, вроде ABBYY FineReader.
Наша книга (тестовая) полностью поддерживает копирование текста и изображений. Но при попытке перенести такой текст в Microsoft Office Word, можно видеть такие нечитабельные символы как на скриншоте сверху статьи.
Способ 1 (длинный).
Вся проблема в шрифтах и системе кодирования. PDF документ, с которого производится копирование имеет встроенные шрифты. И если такие шрифты отсутствуют в вашей операционной системе, то вы увидите такие кракозябры .
Чтобы можно было видеть нормальные буквы, при переносе текста нужно устанавливать соответствующие шрифты .
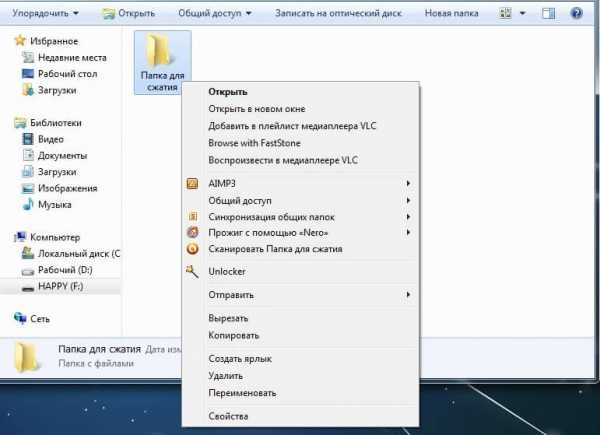
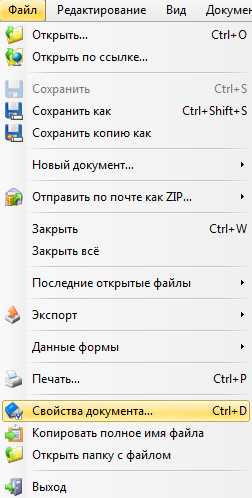
Чтобы узнать какие именно нужно инсталлировать на компьютер шрифты, нужно открыть наш PDF документ поддерживаемой программой (на примере PDF-XChange Viewer ). Далее идем в «Файл» → «Свойства документа» (можно нажать сочетание клавиш Ctrl + D).
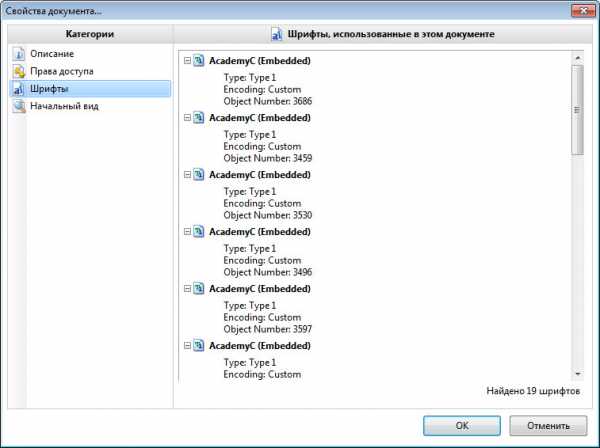
Далее нажимаем на параметр «Шрифты» и видим список шрифтов, установленных в документе. Их и нужно найти в интернете и установить на компьютер. Для этого на загруженном шрифте два раза нажимаем левой клавишей мыши (то есть, открываем его), а потом нажимаем на кнопку «Установить » .
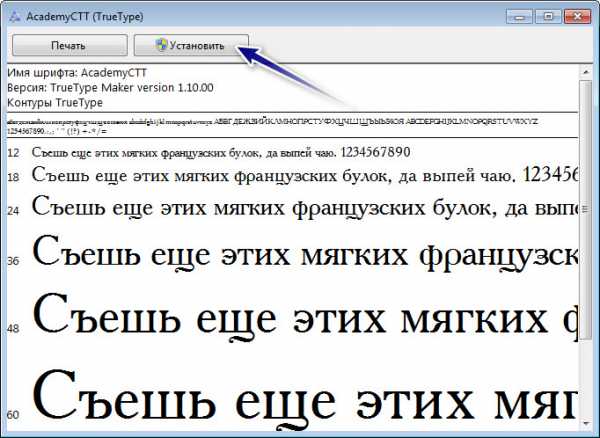
Далее копируем и вставляем текст из PDF документа, выделяем его в Microsoft Office Word (или в другом офисном редакторе, который у вас установлен) и выбираем из списка недавно установленный шрифт. Все должно быть нормально. Снизу на скриншоте видно, что я намеренно применил нужный шрифт только на одно предложение, другую часть текста прочитать невозможно.

Способ 2 (быстро и удобно).
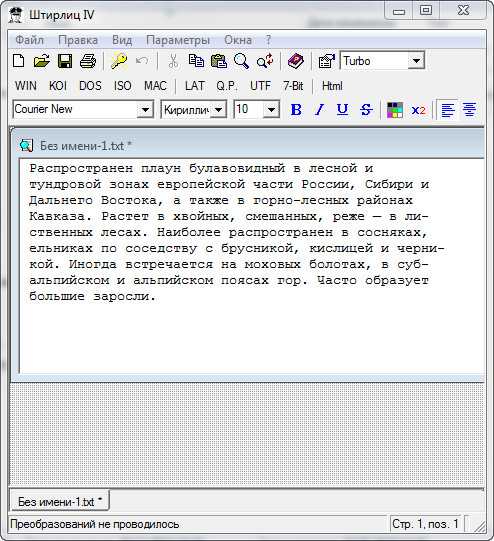
Другой, более правильный и простой вариант – это использование программы (или плагина к редактору Notepad ++ ), которая называется Shtirlitz. Программа старая, давно не обновлялась, однако работает отлично. Прямо на лету выполняется вставка нормального текста. Никаких шрифтов не требуется. После копирования текста с данной программы и дальнейшей вставкой его в редактор Microsoft Office Word, все буквы и символы будут читаться и с использованием любого шрифта. Первый вариант не позволяет изменить шрифт. То есть, всегда, и на каждом компьютере нужно будет инсталлировать нужные шрифты для чтения только определенного документа. А если таких документов несколько сотен? Поэтому желательно воспользоваться этой программой для декодирования.
Способ 3 (онлайн).
Кто не хочет использовать программу Shtirlitz или она не работает, может использовать следующие онлайн сервисы для перекодирования (отдельные сервисы имеют ограничения по объему текста).
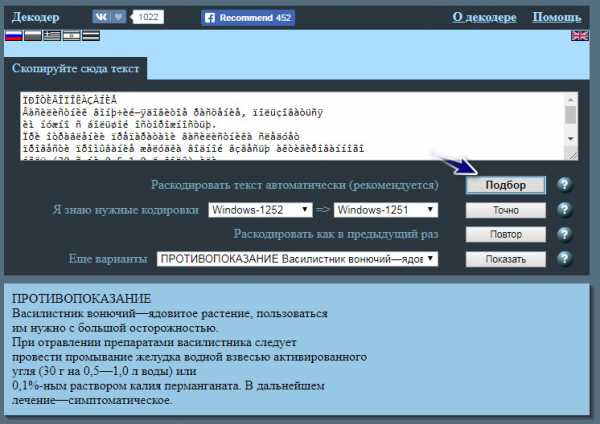
Обратите внимание, что кодирование нашей тестовой книги windows-1252. Для нас нужна кодировка windows-1251. Поэтому переходим на сервис online-decoder.com.
Там можно видеть окно, где написано «Скопируйте сюда текст». Вставляем наш непонятный текст и нажимаем на кнопку «Подбор». Такой способ будет правильно использовать если вам неизвестна система кодирования. Декодер попытается подобрать ее автоматически. Если вы знаете исходное кодирование своей кракозябры, то можете смело нажимать кнопку «Точно», указав перед этим кодирование, напротив текста «Я знаю нужные кодировки».
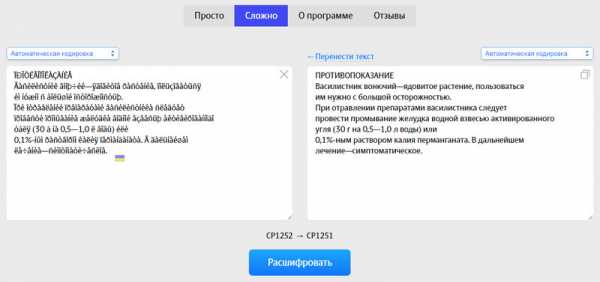
Второй сервис «artlebedev.ru». Есть два способа для декодирования: « Просто» и «Сложно». Первый вариант работает на автомате. Второй – дает возможность, при необходимости, указать исходное и конечное кодирование.
Третий онлайн сервис для декодирования текста «2cyr.com» имеет отличие от предыдущих в том, что позволяет выбирать язык. Кроме русского, доступен также и украинский язык интерфейса (и надеюсь, что кодирования также, просто не было возможности проверить).
Есть также два режима: автоматический и режим эксперта. Во втором можно указывать исходное и конечное кодирование. Рекомендуется автоматический режим. После того как вставили текст, напротив слов «Выберите кодировку : » , нужно выбрать «Автоматически (рекомендуется)» и нажать на кнопку «Ок».
Все три сервиса отлично работали на моей тестовой книге в формате PDF с кракозябрами.
Способ 4 (с помощью макросов для Microsoft Office Word ).
Еще один вариант для программы Microsoft Office Word. Никаких шрифтов ставить не нужно. Создаем макрос со следующим кодом:
Код 1: «Перекодирование 1252 в 1251»
Sub Corr1252_1251()
Dim s$, i&, j&
s = Selection
For i = 1 To Len(s)
j = AscW(Mid$(s, i, 1))
If j ‘ Debug.Print i & vbTab & Mid$(s, i, 1) & vbTab & j & vbTab & Chr(j)
End If
Next
Selection.Text = s
End Sub
Код 2: «Перекодирование 1252 в 1251 (с учетом русской буквы Ё)»
Sub changeToRus()
‘
‘ Замена кракозябр на кириллические буквы
‘ CP1252 -> CP1251
‘
For i = 192 To 255
a1 = i
a = Trim("^u") & Trim(Str(a1))
‘ Формирование запроса для поля Найти
sRus = Array("А", "Б", "В", "Г", "Д", "Е", "Ж", "З", "И", "Й", "К", "Л", "М", "Н", "О", _
"П", "Р", "С", "Т", "У", "Ф", "Х", "Ц", "Ч", "Ш", "Щ", "Ъ", "Ы", "Ь", "Э", "Ю", "Я", _
"а", "б", "в", "г", "д", "е", "ж", "з", "и", "й", "к", "л", "м", "н", "о", _
"п", "р", "с", "т", "у", "ф", "х", "ц", "ч", "ш", "щ", "ъ", "ы", "ь", "э", "ю", "я")
‘ Формирование массива кириллических букв для поля Заменить
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = a
.Replacement.Text = sRus(i – 192)
.Forward = True
.Wrap = wdFindContinue
.MatchCase = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
‘ Выполнение замены по тексту
Next i
‘ Замена Ё и ё
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(168)
.Replacement.Text = "Ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(184)
.Replacement.Text = "ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Выделяем вставленный текст с иероглифами. Тогда запускаем макрос на выполнение и получаем нормальный текст, который можно спокойно редактировать, изменять шрифты и т.д.
Для добавления готового макроса в Word делаем следующее:
Открываем редактор и переходим в «Вид».
Там находим кнопку «Макросы» и нажимаем на нее.
Даем для макроса имя (любое, оно будет автоматически изменено при полном копировании кода выше).
Откроется окно в котором можно заметить название нашего макроса. При желании можете оставить свое имя. Но лучше, чтобы не было ошибок, полностью заменить весь код на готовый (код смотрите сверху).
Как видно, макрос начинается так:
Sub названиемакроса()
дальше идет код макроса
End Sub
Название макроса может любым, но не цифры и не должно быть пробелов. Может быть так: декодирование_кракозябр_с_ё. Но не может быть так: декодирование кракозябр с ё.
То есть, для нас нужно заменить для нашего созданного пустого макроса весь текст с кодом, который показан выше.
После того как заменили, нужно закрыть окно редактирования макросов (можно нажать на иконку сохранения, хотя изменения сохраняются автоматически). Далее выделяем наш иероглифический текст, открываем макросы, выбираем из списка (если их у вас несколько) нужный и нажимаем на кнопку «Выполнить».
Ваш текст должен стать читабельным.

Источник макросов для Microsoft Office Word: http://wordexpert.ru
Как ни крути, но это не полное решение ситуации. Поиск после данных действий в самом PDF документе работать не будет. Проблема остается. Кто может подсказать ее решение, просьба писать в комментариях.
На этой странице
При экспорте PDF в файлы других форматов с помощью инструмента «Экспортировать PDF» для каждого из форматов существуют собственные уникальные параметры преобразования.
В этом документе приведены инструкции по работе с Acrobat DC. Инструкции по работе с Acrobat Reader DC см. в статье Возможности Adobe Reader. При использовании Acrobat XI см. Справка Acrobat XI.
Параметры Adobe PDF (Acrobat Pro DC)
С помощью диалогового окна «Оптимизация PDF» файлы PDF можно заново сохранить как оптимизированные. В окне «Оптимизация PDF» можно менять параметры совместимости файлов PDF так, чтобы просматривать их в старых версиях программ Acrobat DC или Reader DC. Если изменить параметры совместимости, более новые функции будут недоступны в файлах PDF. Сведения о каждом параметре совместимости см. в разделе Уровни совместимости PDF.
Если каждый раз при преобразовании документов PDF в конкретный формат нужно применять одни и те же настройки, укажите их в диалоговом окне «Установки». На панели Преобразование из PDF выберите файловый формат из списка и щелкните Изменить параметры (установки по умолчанию можно в любое время восстановить, нажав кнопку «Восстановить значения по умолчанию»).
Параметры преобразования изображений
Параметры JPEG и JPEG2000
Если в документе PDF содержится набор изображений, их можно экспортировать по отдельности как файлы JPEG, PNG или TIFF, выбрав меню «Инструменты» > «Экспортировать PDF» > «Изображение» > «Экспорт всех изображений».
Обратите внимание, что доступность параметров зависит от выбранного формата преобразования документа (JPEG или JPEG2000).
В градациях серого/Цветные
Задает сжатие, уравновешивающее размер файла и качество изображения. Чем меньше файл, тем хуже качество изображения.
Разделение сжимаемого изображения на сегменты заданного размера (если высота или ширина изображения не кратна размеру сегмента, по краям используются частичные сегменты). Данные изображения для каждого сегмента сжимаются отдельно, восстановление их также можно выполнять по отдельности. Рекомендуется использовать значение по умолчанию, равное 256. Этот параметр доступен только для формата JPEG2000.
Определяет способ отображения файла. Доступно только для формата JPEG.
Отображает изображение после его полной загрузки. Данный формат JPEG распознается почти всеми веб-браузерами.
Оптимизирует качество цветного изображения и создает файлы меньших размеров. Не поддерживается некоторыми веб-браузерами.
Прогрессивный (3 прохода – 5 проходов)
Начальная загрузка изображения – с низким разрешением, затем по мере загрузки качество изображения улучшается.
RGB/CMYK/В градациях серого
Задает тип управления цветом, применяемый к выходному файлу, и встраивает ICC-профиль.
Если команда «Экспорт в» или «Экспорт всех изображений» используется для PDF-файла, содержащего изображения JPEG и JPEG 2000, и содержимое экспортируется в формате JPEG или JPEG 2000, полученное изображение при открытии в Acrobat DC может выглядеть иначе. Это может произойти в том случае, если в изображения встроены цветовые профили на уровне страницы, а не внутри данных изображения. В таком случае Acrobat DC не может использовать цветовой профиль на уровне страницы для сохраняемого изображения.
Задает цветовое пространство и разрешение выходного файла. Acrobat может определить эти параметры автоматически. Для преобразования цветных изображений в файл в градациях серого выберите «В градациях серого».
Более высокое разрешение, например 2400 ppi, подходит только для страниц маленького размера (до 173,38 мм).
Параметры PNG
Формат PNG используется для изображений в Интернете.
Определение чересстрочного изображения. Изображение отображается в веб-браузере только после полной загрузки. Adam7 создает изображение, которое отображается в веб-браузере с низким разрешением, пока загружается полный файл изображения. Adam7 позволяет сократить время загрузки и информирует средства просмотра о процессе загрузки, но при этом увеличивается размер файла.
Выбор алгоритма фильтрации.
Сжатие изображения без фильтра. Рекомендуется для индексированных и битовых изображений.
Оптимизация сжатия изображений с четными горизонтальными узорами или переходами.
Оптимизация сжатия изображений с четными вертикальными узорами.
Оптимизация сжатия шумов низкого уровня с помощью усреднения цветовых значений соседних пикселов.
Оптимизация сжатия шумов низкого уровня с помощью перераспределения соседних цветовых значений.
Применение алгоритма фильтрации, наиболее подходящего для изображения – «Под», «Над», «Усредненный» или «Контур». Выберите «Адаптивный», если неизвестно, какой фильтр использовать.
RGB/В градациях серого
Задание типа управления цветом для выходного файла и встраивания ICC-профиля.
Задает цветовое пространство и разрешение выходного файла. Acrobat может определить эти параметры автоматически. Для преобразования цветных изображений в файл в градациях серого выберите «В градациях серого».
Более высокое разрешение, например 2400 ppi, подходит только для страниц маленького размера (до 173,38 мм).
Параметры TIFF
TIFF представляет собой гибкий формат растрового изображения, поддерживаемый практически всеми приложениями рисования, обработки изображений и верстки. Разрешение определяется автоматически.
Задание формата сжатия. Значение по умолчанию CCITTG4 обычно обеспечивает наименьший размер файла. Сжатие ZIP также позволяет получить файлы малых размеров.
В некоторых приложениях невозможно открыть файлы TIFF, сохраненные со сжатием JPEG или ZIP. В таких случаях рекомендуется использовать сжатие LZW.
RGB/CMYK/В градациях серого/Другое
Задание типа управления цветом выводного файла.
Задает цветовое пространство и разрешение выходного файла. Acrobat может определить эти параметры автоматически. Для преобразования цветных изображений в файл в градациях серого выберите «В градациях серого».
Более высокое разрешение, например 2400 ppi, подходит только для страниц маленького размера (до 173,38 мм).
Параметры файлов Microsoft Word и RTF
Файл PDF можно экспортировать в формат Word (DOCX или DOC) или расширенный текстовый формат (RTF). Доступны следующие параметры.
Сохранить обтекание текстом
Указывает на то, что обтекание текстом должно быть сохранено.
Сохранить макет страницы
Указывает на то, что макет страницы должен быть сохранен.
Включить комментарии
Комментарии экспортируются в выходной файл.
Включить изображения
Изображения экспортируются в выходной файл.
Распознать текст при необходимости
Распознает текст, если файл PDF содержит изображения с текстом.
Выбрать язык
Указывает язык для оптического распознавания символов.
Параметры веб-страницы HTML
Одна страница HTML
Указывает, что при экспорте в формат HTML создается один файл HTML. Чтобы добавить панель навигации, включите следующие параметры:
Добавить кадр навигации на базе заголовков
Добавить кадр навигации на базе закладок
Несколько страниц HTML
Указывает, что при экспорте в формат HTML создается несколько файлов HTML. Чтобы разделить документ на несколько файлов HTML, выберите один из критериев.
Разделить по заголовкам документа
Разделить по закладкам документа
Указывает, экспортировать ли изображения при экспорте файла PDF в HTML.
Найти и удалить верхний и нижний колонтитулы
Указывает, необходимо ли удалить содержимое верхнего и нижнего колонтитулов в документе PDF из файлов HTML.
Распознать текст при необходимости
Распознает текст, если файл PDF содержит изображения с текстом.
Указывает язык для оптического распознавания символов.
Параметры электронной таблицы
Настройки книги Excel
Указывает, будет ли создан рабочий лист для каждой таблицы, страницы или всего документа.
Настройки формата чисел
Указывает десятичный разделитель и разделитель разрядов для числовых данных. Выберите один из следующих вариантов.
Определить десятичный разделитель и разделитель разрядов исходя из региональных настроек
Рассматривать следующие символы как десятичный разделитель и разделитель разрядов. Введите или выберите разделители в соответствующих полях.
Распознать текст при необходимости
Распознает текст, если файл PDF содержит изображения с текстом.
Указывает язык для оптического распознавания символов.
Параметры PostScript и Encapsulated PostScript (EPS)
Возможен экспорт файлов PDF в PostScript® для использования в приложениях печати и допечатной подготовки. Файл PostScript включает все комментарии DSC ( Document Structuring Conventions ) и другую дополнительную информацию, сохраняемую программой Adobe Acrobat Distiller ®. Из любого файла PDF можно также создать файл EPS, который можно будет использовать вместо файла PDF или открывать в других приложениях. Набор доступных параметров зависит от того, преобразуется ли документ в PostScript или EPS.
При создании файлов EPS для цветоделения в программе Acrobat Pro DC все изображения должны находиться в цветовом пространстве CMYK.
Файл описания принтера
Файл описания принтера (PPD) предоставляет сведения, необходимые для правильного форматирования файла PostScript при выводе на определенное выводное устройство. Аппаратно-независимый – создает только совмещенные (не цветоделенные) файлы PostScript или EPS. Acrobat по умолчанию – предоставляет исходную точку и ссылку для создания всех типов файлов PostScript и восстанавливает для преобразования все параметры по умолчанию. Формат Adobe PDF 7.0 совместим с большинством устройств. Этот параметр доступен только для формата PostScript.
ASCII или двоичный
Определяет выходной формат данных изображений. Двоичный формат обеспечивает меньший размер файлов, но его можно использовать не во всех рабочих процессах.
Определяет уровень совместимости с языком PostScript. Следует использовать Level 3 только в том случае, если устройство вывода обеспечивает его поддержку. Level 2 подходит для файлов EPS, предназначенных для размещения в других документах, цветоделение которых выполняется в составе этого документа. Используйте Level 2 для файлов EPS, импортируемых в приложения Майкрософт.
Определяет шрифты, которые будут включены в PostScript. Встроенные шрифты берутся из PDF, все прочие — из системы используемого компьютера.
Сохраняет оформление комментариев в конечном файле PostScript.
Преобразовать шрифты TrueType в Type 1
Преобразует шрифты TrueType в Type 1 в конечном файле PostScript.
Определяет создание файла просмотра TIFF для конечного файла EPS. Этот параметр недоступен в случае сохранения файла в формате PostScript.
Задает страницы для экспорта. При экспорте страниц в EPS каждая страница в диапазоне сохраняется в отдельном файле EPS.
Текст и параметры XML
Двоичные значения на основе международных стандартов, используемых для представления текстовых символов. UTF-8 – кодировка Юникода, в которой на каждый символ приходится один или несколько байтов по 8 бит, а в кодировке UTF-16 используются байты по 16 бит. ISO-Latin-1 – 8-битовое представление символов, являющееся расширением набора ASCII. UCS-4 – универсальный набор символов с кодировкой в 4 октетах. HTML/ASCII – 7-битовое представление символов, разработанное Американским национальным институтом стандартизации.
В таблице преобразования по умолчанию используется кодировка по умолчанию, определенная в таблицах преобразования, расположенных в папке Plug-ins/SaveAsXML/MappingTables. Такие таблицы соответствия определяют различные характеристики вывода данных, включая следующие стандартные кодировки: UTF-8 (сохранение в виде XML или HTML 4.0.1) и HTML/ASCII (сохранение в виде HTML 3.2).
Создает закладки для перехода по содержимому документов HTML или XML. Закладки размещаются в начале создаваемого документа HTML или XML.
Создать теги в файлах, в которых они отсутствуют
Создает теги для файлов, в которых они отсутствуют (например, для файлов PDF, созданных с помощью Acrobat 4.0 или более ранних версий). Если этот параметр не установлен, неразмеченные файлы не преобразуются.
Теги создаются только в процессе преобразования, затем они удаляются. С помощью этого метода нельзя создавать файлы PDF с тегами из устаревших файлов
Контролирует преобразование изображений. Ссылки на преобразованные файлы изображений находятся в документах XML и HTML.
Использовать вложенную папку
Задает папку, в которую сохраняются созданные изображения. По умолчанию используется папка Images.
Задает префикс, добавляемый к именам файлов изображений (на тот случай, если будет создано нескольких версий одного файла изображения). Изображениям присваиваются имена в формате имяфайла_img_#.
Задает выходной формат изображений. Формат по умолчанию – JPG.
Понижает разрешение графических файлов до заданного разрешения. Если эта опция не используется, файлы изображений сохраняются с разрешением исходных файлов. Увеличение разрешения файлов не используется никогда.
Справки по другим продуктам
На посты, размещаемые в Twitter™ и Facebook, условия Creative Commons не распространяются.
Вопросы сообществу
Получайте помощь от экспертов по интересующим вас вопросам.
Кракозябры (иероглифы) при копировании с PDF документа
Электронные книги вошли в нашу повседневную жизнь и продолжают укреплять свою позицию. PDF – один из самых популярных форматов, который можно встретить на интернет просторах, посещая сайты и магазины. Но бывают досадные ситуации, когда текст, который мы хотим скопировать, просто превращается в непонятные символы. Кто-то на них говорит иероглифы, другие – кракозябры ... Как же исправить такую ситуацию?
Я не уверен, что следующие советы помогут для всех решить проблему, но частичное решение ее все же возможно.
Давайте сразу отбросим отсканированые и нераспознанные PDF документы, из которых просто невозможно скопировать текст. Это равносильно попытке копирования текста из обычной фотографии, сделанной на ваш смартфон. В таком случае текст нужно распознать специальной программой, вроде ABBYY FineReader.
Наша книга (тестовая) полностью поддерживает копирование текста и изображений. Но при попытке перенести такой текст в Microsoft Office Word, можно видеть такие нечитабельные символы как на скриншоте сверху статьи.
Способ 1 (длинный).
Вся проблема в шрифтах и системе кодирования. PDF документ, с которого производится копирование имеет встроенные шрифты. И если такие шрифты отсутствуют в вашей операционной системе, то вы увидите такие кракозябры.
Чтобы можно было видеть нормальные буквы, при переносе текста нужно устанавливать соответствующие шрифты.
Чтобы узнать какие именно нужно инсталлировать на компьютер шрифты, нужно открыть наш PDF документ поддерживаемой программой (на примере PDF-XChange Viewer). Далее идем в «Файл» → «Свойства документа» (можно нажать сочетание клавиш Ctrl + D).
Далее нажимаем на параметр «Шрифты» и видим список шрифтов, установленных в документе. Их и нужно найти в интернете и установить на компьютер. Для этого на загруженном шрифте два раза нажимаем левой клавишей мыши (то есть, открываем его), а потом нажимаем на кнопку «Установить».
Далее копируем и вставляем текст из PDF документа, выделяем его в Microsoft Office Word (или в другом офисном редакторе, который у вас установлен) и выбираем из списка недавно установленный шрифт. Все должно быть нормально. Снизу на скриншоте видно, что я намеренно применил нужный шрифт только на одно предложение, другую часть текста прочитать невозможно.
Способ 2 (быстро и удобно).
Другой, более правильный и простой вариант – это использование программы (или плагина к редактору Notepad ++), которая называется Shtirlitz. Программа старая, давно не обновлялась, однако работает отлично. Прямо на лету выполняется вставка нормального текста. Никаких шрифтов не требуется. После копирования текста с данной программы и дальнейшей вставкой его в редактор Microsoft Office Word, все буквы и символы будут читаться и с использованием любого шрифта. Первый вариант не позволяет изменить шрифт. То есть, всегда, и на каждом компьютере нужно будет инсталлировать нужные шрифты для чтения только определенного документа. А если таких документов несколько сотен? Поэтому желательно воспользоваться этой программой для декодирования.
Скачать программу и плагин для Notepad ++ Shtirlitz (даю прямую ссылку, поскольку сайта уже давно нет)
Способ 3 (онлайн).
Кто не хочет использовать программу Shtirlitz или она не работает, может использовать следующие онлайн сервисы для перекодирования (отдельные сервисы имеют ограничения по объему текста).
Обратите внимание, что кодирование нашей тестовой книги windows-1252. Для нас нужна кодировка windows-1251. Поэтому переходим на сервис online-decoder.com.
Там можно видеть окно, где написано «Скопируйте сюда текст». Вставляем наш непонятный текст и нажимаем на кнопку «Подбор». Такой способ будет правильно использовать если вам неизвестна система кодирования. Декодер попытается подобрать ее автоматически. Если вы знаете исходное кодирование своей кракозябры, то можете смело нажимать кнопку «Точно», указав перед этим кодирование, напротив текста «Я знаю нужные кодировки».
Открыть сервис «online-decoder.com»
Второй сервис «artlebedev.ru». Есть два способа для декодирования: «Просто» и «Сложно». Первый вариант работает на автомате. Второй – дает возможность, при необходимости, указать исходное и конечное кодирование.
Открыть сервис «artlebedev.ru»
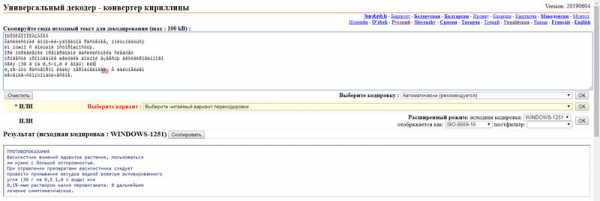
Третий онлайн сервис для декодирования текста «2cyr.com» имеет отличие от предыдущих в том, что позволяет выбирать язык. Кроме русского, доступен также и украинский язык интерфейса (и надеюсь, что кодирования также, просто не было возможности проверить).
Есть также два режима: автоматический и режим эксперта. Во втором можно указывать исходное и конечное кодирование. Рекомендуется автоматический режим. После того как вставили текст, напротив слов «Выберите кодировку :», нужно выбрать «Автоматически (рекомендуется)» и нажать на кнопку «Ок».
Открыть сервис «2cyr.com»
Все три сервиса отлично работали на моей тестовой книге в формате PDF с кракозябрами.
Способ 4 (с помощью макросов для Microsoft Office Word ).
Еще один вариант для программы Microsoft Office Word. Никаких шрифтов ставить не нужно. Создаем макрос со следующим кодом:
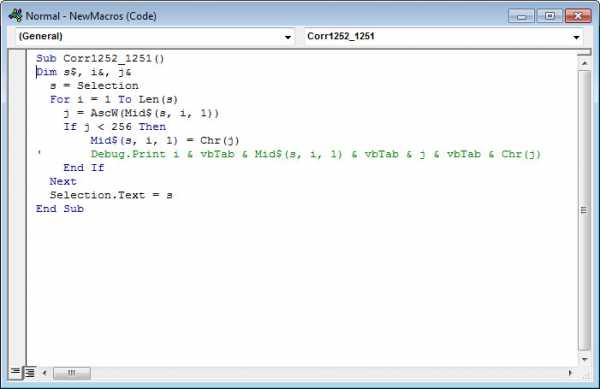
Код 1: «Перекодирование 1252 в 1251»
Sub Corr1252_1251()
Dim s$, i&, j&
s = Selection
For i = 1 To Len(s)
j = AscW(Mid$(s, i, 1))
If j < 256 Then
Mid$(s, i, 1) = Chr(j)
' Debug.Print i & vbTab & Mid$(s, i, 1) & vbTab & j & vbTab & Chr(j)
End If
Next
Selection.Text = s
End Sub
Код 2: «Перекодирование 1252 в 1251 (с учетом русской буквы Ё)»
Sub changeToRus()
'
' Замена кракозябр на кириллические буквы
' CP1252 -> CP1251
'
For i = 192 To 255
a1 = i
a = Trim("^u") & Trim(Str(a1))
' Формирование запроса для поля Найти
sRus = Array("А", "Б", "В", "Г", "Д", "Е", "Ж", "З", "И", "Й", "К", "Л", "М", "Н", "О", _
"П", "Р", "С", "Т", "У", "Ф", "Х", "Ц", "Ч", "Ш", "Щ", "Ъ", "Ы", "Ь", "Э", "Ю", "Я", _
"а", "б", "в", "г", "д", "е", "ж", "з", "и", "й", "к", "л", "м", "н", "о", _
"п", "р", "с", "т", "у", "ф", "х", "ц", "ч", "ш", "щ", "ъ", "ы", "ь", "э", "ю", "я")
' Формирование массива кириллических букв для поля Заменить
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = a
.Replacement.Text = sRus(i - 192)
.Forward = True
.Wrap = wdFindContinue
.MatchCase = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
' Выполнение замены по тексту
Next i
' Замена Ё и ё
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(168)
.Replacement.Text = "Ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(184)
.Replacement.Text = "ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Выделяем вставленный текст с иероглифами. Тогда запускаем макрос на выполнение и получаем нормальный текст, который можно спокойно редактировать, изменять шрифты и т.д.
Для добавления готового макроса в Word делаем следующее:
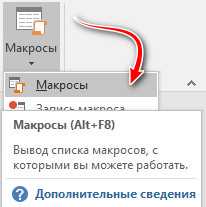
Открываем редактор и переходим в «Вид».
Там находим кнопку «Макросы» и нажимаем на нее.
Даем для макроса имя (любое, оно будет автоматически изменено при полном копировании кода выше).
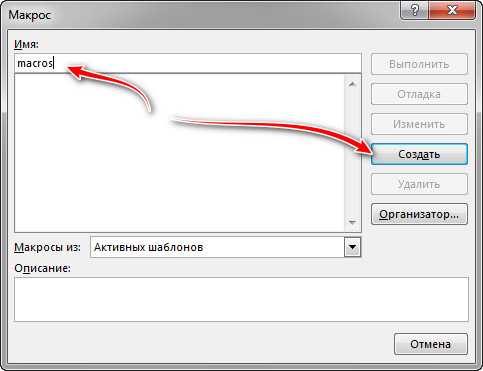
Откроется окно в котором можно заметить название нашего макроса. При желании можете оставить свое имя. Но лучше, чтобы не было ошибок, полностью заменить весь код на готовый (код смотрите сверху).
Как видно, макрос начинается так:
Sub названиемакроса()
дальше идет код макроса
End Sub
Название макроса может любым, но не цифры и не должно быть пробелов. Может быть так: декодирование_кракозябр_с_ё. Но не может быть так: декодирование кракозябр с ё.
То есть, для нас нужно заменить для нашего созданного пустого макроса весь текст с кодом, который показан выше.
После того как заменили, нужно закрыть окно редактирования макросов (можно нажать на иконку сохранения, хотя изменения сохраняются автоматически). Далее выделяем наш иероглифический текст, открываем макросы, выбираем из списка (если их у вас несколько) нужный и нажимаем на кнопку «Выполнить».
Ваш текст должен стать читабельным.
Источник макросов для Microsoft Office Word: http://wordexpert.ru
Как ни крути, но это не полное решение ситуации. Поиск после данных действий в самом PDF документе работать не будет. Проблема остается. Кто может подсказать ее решение, просьба писать в комментариях.
Параметры форматирования файлов для экспорта в PDF, Adobe Acrobat
Двоичные значения на основе международных стандартов, используемых для представления текстовых символов. UTF-8 — кодировка Юникода, в которой на каждый символ приходится один или несколько байтов по 8 бит, а в кодировке UTF-16 используются байты по 16 бит. ISO-Latin-1 — 8-битовое представление символов, являющееся расширением набора ASCII. UCS-4 — универсальный набор символов с кодировкой в четырех октетах. HTML/ASCII — 7-битовое представление символов, разработанное Американским национальным институтом стандартизации.
В таблице преобразования по умолчанию используется кодировка по умолчанию, определенная в таблицах преобразования, расположенных в папке Plug-ins/SaveAsXML/MappingTables. Такие таблицы соответствия определяют различные характеристики вывода данных, включая следующие стандартные кодировки: UTF-8 (сохранение в виде XML или HTML 4.0.1) и HTML/ASCII (сохранение в виде HTML 3.2).
Шрифты PDF, Adobe Acrobat
Шрифт можно встроить только в том случае, если поставщиком шрифта установлен параметр, допускающий встраивание. Встраивание исключает подстановку шрифта при просмотре или печати файла, поэтому читатель видит текст, набранный первоначальным шрифтом. Встраивание незначительно увеличивает размер файла, за исключением случая использования шрифтов CID — формата шрифтов, используемых для восточных языков. Встроить или подменить шрифты можно как в Acrobat, так и при экспорте документа InDesign в формат PDF.
Встраивать можно как весь шрифт целиком, так и подмножество символов, которые были реально использованы в файле. Использование подмножества обеспечивает применение при печати конкретных шрифтов и метрики шрифтов посредством создания пользовательского имени для шрифта. Таким образом, например, для просмотра и печати документа поставщиком услуг может использоваться ваша версия шрифта Adobe Garamond®, а не версия поставщика. Шрифты Type 1 и TrueType можно встраивать, если они включены в файл PostScript или доступны в одном из каталогов шрифтов, отслеживаемых приложением Distiller, и разрешены для встраивания.
Если шрифт невозможно встроить из-за настроек поставщика шрифта, или пользователь, который открывает или печатает PDF, не имеет доступа к оригинальному шрифту, выполняется временное замещение гарнитуры Multiple Master: гарнитурой AdobeSerifMM для отсутствующего шрифта serif и AdobeSansMM для sans serif.
Гарнитуру шрифта Multiple Master отличает способность сужаться и растягиваться, чтобы подходить по размерам к странице, и в результате строки и разбиение на страницы остаются такими же, как были в документе изначально. При подстановке, разумеется, не всегда удается воспроизвести форму оригинальных символов, особенно если использована нестандартная (например, рукописная) гарнитура шрифта.
[Решено] Исправляем иероглифы при печати pdf файла
При печати pdf файла на принтере печатаются иероглифы или как говорили мои бухгалтера на старой работе «Виталий подойди у нас при печати pdf абракадабра распечатывается «. Сегодня на работе возникла такая же фигня и т.к. я стараюсь в своем блоге описывать по максимуму решения таких проблем и решил выложить инструкцию по исправлению иероглифов в pdf файлах. Так вот эту проблему можно решить тремя способами(может есть и еще но я опишу те какие знаю ).

1 Способ
Это самый надежный и проверенный временем способ!!
- Открыть редактор реестра (Пуск -> Выполнить -> regedit.exe)
- Перейти в
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontSubstitutes - Удалить параметры: «Courier,0»=»Courier New,204″
«Arial,0»=»Arial,204″ - Перезагрузить ПК
PS перезагрузить комп нужно обязательно!!!
2 Способ
Самый долгий наверное из всех трех способ, это скачать русифицированную версию самого adobe reader:
- Скачать последнюю версию adobe reader с официального сайта http://get.adobe.com/ru/reader/
- После этого открываем фаил и радуемся жизни
2 Способ
Так вот первый способ самый быстрый но и самый не качественный в плане разрешения распечатывающегося документа:
- При печати документа зайдите в дополнительно и выберите печать как изображения (File — print -advanced — галочка print as image)
4 Способ
Этот способ самый действенный и кардинальный т.к. решение данного косяка будет осуществлен на уровне реестра windows:
- Скачать adobe reader (это важно на будущее потому как лучше иметь последнюю версию данной программы)
- Создаем reg фаил и вносим в него следующие строки, после чего запускаем, соглашаемся со всем что он скажет и перезагружаем комп.
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage] "1250"="c_1251.nls" "1251"="c_1251.nls" "1252"="c_1251.nls" "1253"="c_1251.nls" "1254"="c_1251.nls" "1255"="c_1251.nls" [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontMapper] "ARIAL"=dword:000000cc [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontSubstitutes] "Arial,0"="Arial,204" "Arial Cyr,0"="Arial,204" "Comic Sans MS,0"="Comic Sans MS,204" "Courier,0"="Courier New,204" "Courier,204"="Courier New,204" "Courier New Cyr,0"="Courier New,204" "Fixedsys,0"="Fixedsys,204" "Helv,0"="MS Sans Serif,204" "MS Sans Serif,0"="MS Sans Serif,204" "MS Serif,0"="MS Serif,204" "Small Fonts,0"="Small Fonts,204" "System,0"="Arial,204" "Tahoma,0"="Tahoma,204" "Times New Roman,0"="Times New Roman,204" "Times New Roman Cyr,0"="Times New Roman,204" "Tms Rmn,0"="MS Serif,204" "Verdana,0"="Verdana,204"
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage] "1250"="c_1251.nls" "1251"="c_1251.nls" "1252"="c_1251.nls" "1253"="c_1251.nls" "1254"="c_1251.nls" "1255"="c_1251.nls"
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontMapper] "ARIAL"=dword:000000cc
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontSubstitutes] "Arial,0"="Arial,204" "Arial Cyr,0"="Arial,204" "Comic Sans MS,0"="Comic Sans MS,204" "Courier,0"="Courier New,204" "Courier,204"="Courier New,204" "Courier New Cyr,0"="Courier New,204" "Fixedsys,0"="Fixedsys,204" "Helv,0"="MS Sans Serif,204" "MS Sans Serif,0"="MS Sans Serif,204" "MS Serif,0"="MS Serif,204" "Small Fonts,0"="Small Fonts,204" "System,0"="Arial,204" "Tahoma,0"="Tahoma,204" "Times New Roman,0"="Times New Roman,204" "Times New Roman Cyr,0"="Times New Roman,204" "Tms Rmn,0"="MS Serif,204" "Verdana,0"="Verdana,204" |
Вот и все!!! :-) таким образом мы научились исправлять иероглифы при печати pdf документа. Всем спасибо за внимание. иероглифы в pdf, pdf печатает иероглифы, в pdf кракозябры, иероглифы в пдф, в pdf вместо букв иероглифы, pdf печатается иероглифами, принтер печатает иероглифы pdf, при печати из pdf иероглифы, пдф печатает иероглифы, копирую из pdf иероглифы, копируются иероглифы из pdf, почему pdf печатает иероглифы, файл pdf печатает иероглифы, кракозябры при печати pdf, при распечатке pdf иероглифы, в файле pdf иероглифы, pdf распечатывается иероглифами, почему пдф печатает иероглифы, pdf печатает кракозябры
Вот и все!!! :-) таким образом мы научились исправлять иероглифы при печати pdf документа. Всем спасибо за внимание.
иероглифы в pdf, pdf печатает иероглифы, в pdf кракозябры, иероглифы в пдф, в pdf вместо букв иероглифы, pdf печатается иероглифами, принтер печатает иероглифы pdf, при печати из pdf иероглифы, пдф печатает иероглифы, копирую из pdf иероглифы, копируются иероглифы из pdf, почему pdf печатает иероглифы, файл pdf печатает иероглифы, кракозябры при печати pdf, при распечатке pdf иероглифы, в файле pdf иероглифы, pdf распечатывается иероглифами, почему пдф печатает иероглифы, pdf печатает кракозябры |
Как изменить кодировку текста PDF? (ANSI для UNICODE)
У меня есть проблема с PDF, с которого я пытаюсь скопировать текст ... У меня есть этот текст в PDF, и мне нужно вставить его в страницу HTML, проблема в том, что когда я копирую текст, некоторые буквы ( слова с диакритическими знаками (например, Ț или Ș) пропускаются, слова, содержащие их, больше не верны ...
Я узнал, что это потому, что PDF использует кодировку шрифтов ASNI, а браузер использует UNICODE ... как я могу изменить кодировку ANSI в PDF, чтобы преобразовать ее в UNICODE?
Флавий Францпожалуйста, не переносите этот вопрос на обмен стеками кода ... потому что, как дизайнер, вы иногда сталкиваетесь с этой проблемой, и нет ничего, что могло бы вам помочь ...
thebodzio
Как вы извлекаете свой текст? Например, из Adobe Reader / Acrobat с помощью выбора текста и копирования?
Флавий Франц
да есть другой способ?
thebodzio
На самом деле есть ... и несколько из них. Можно было бы использовать Acrobat «Export-> Text->…» (он точно присутствует в версии 9; доступны некоторые параметры экспорта, такие как результирующая кодировка файлов). Есть также пара инструментов для извлечения текста из файла PDF. Некоторые из них инструменты командной строки, такие как pdf2html, pdf2txt или что-то в этом роде. Но даже тогда получение текста из PDF может быть проблематичным.
Флавий Франц
Вот образец моего текста: pas «in crearea unei pieee unice, denumit apoi Comunitatea Economic», European »), Declaraleia Solemn privind
PDFBox - Как изменить кодировку с WinAnsiEncoding на Unicode?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
pdf - как проверить правильность кодирования и ToUnicode для pdf?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для
c ++ - Как найти и изменить кодировку существующего файла?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
Изменить кодировку файла на utf-8 через vim в скрипте
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами