Как файл pdf распознать
Как распознать текст в формате pdf 🚩 Программное обеспечение
Электронные документы, созданные текстовым редактором, легко распознает бесплатная программа Adobе Rеadеr. Откройте в программе нужный PDF файл, зайдите в меню «редактировать», в выпадающем окне выберите строку «копировать в буфер обмена». Создайте в «ворде» новый документ, вставьте в него из буфера обмена текс и редактируйте, затем сохраните в нужном формате.
Также конвертировать и редактировать пдф-файлы можете при помощи многофункциональной утилиты Acrobat Reader DC. Программный продукт располагает большим количеством инструментов для работы с электронными документами.
Это хорошие программы, но они не смогут распознать текст, если pdf-документы защищены от редактирования или отсканированы с бумажного носителя. В этом случае нужна специальная программа оптического распознавания символов.
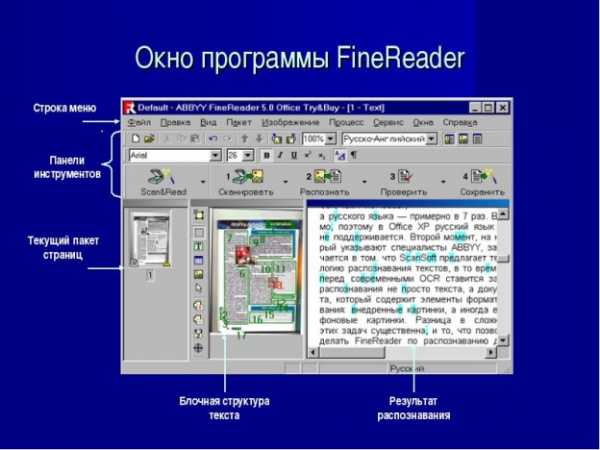
Безусловным лидером является ABBYY FineReader, программа распознает и отдельные страницы, и работает в пакетном режиме. Обработанный текст можно сохранить в txt, doc, html и других форматах. Программа довольно качественно распознает текст pdf. Возможен небольшой процент неправильно распознаных символов и документу потребуется ручная доработка, результат зависит от качества сканов. У этой программы один недостаток – она платная.
Существуют и другие платные, а также бесплатные программы, позволяющие распознать и конвертировать текст из pdf в word: бесплатные – CuneiForm, Freemore OCR, FreeOCR; платные – Readiris Pro, Nitro PDF Professional.
Если не каждый день преобразовываете электронные документы, просто возникла необходимость один раз поработать с форматом пдф, в этом случае нет смысла устанавливать на компьютер программу. Для таких эпизодов существуют онлайн сервисы. Также удобно пользоваться ими на работе, в путешествии, когда нет рядом компьютера с установленной программой. Онлайн сервисы позволяют распознать текст бесплатно и быстро. Вот некоторые:
- Online OCR - www.onlineocr.net
- NewOCR - www.newocr.com
- Free-OCR - www.free-ocr.com
- OCRConvert - www.ocrconvert.com
В распознавании текста онлайн много положительных моментов, но есть и минусы: на сервисе надо зарегистрироваться; не все сервисы имею функцию экспорта, надо самому распознанный текс копировать с веб-страницы; на некоторых сервисах установлен лимит на количество обрабатываемых документов; качество конечного результата зависит от скорости интернета.
Как выяснилось, распознать текст pdf несложно, существуют разные програмы, можите выбирать любую.
Бесплатный онлайн инструмент OCR (Распознавание текста) — Convertio
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Выберите файлыПоддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
Как распознать PDF файл онлайн
Извлечь текст из PDF-файла методом обычного копирования можно далеко не всегда. Часто страницы подобных документов представляют собой отсканированное содержимое их бумажных вариантов. Для преобразования таких файлов в полностью редактируемые текстовые данные используются специальные программы с функцией Optical Character Recognition (OCR).
Такие решения являются весьма сложными в реализации и, следовательно, стоят немалых денег. Если потребность в распознавании текста с PDF у вас возникает регулярно, вполне целесообразно будет приобрести соответствующую программу. Для редких же случаев более логичным будет воспользоваться одним из доступных онлайн-сервисов с подобными функциями.
Как распознать текст с PDF онлайн
Конечно, набор возможностей онлайн-сервисов OCR, в сравнении с полноценными десктопными решениями, более ограничен. Но и работать с такими ресурсами можно либо же совсем бесплатно, либо за символическую плату. Главное, что с основной своей задачей, а именно с распознаванием текста, соответствующие веб-приложения справляются так же хорошо.
Способ 1: ABBYY FineReader Online
Компания-разработчик сервиса — одна из лидеров в области оптического распознавания документов. ABBYY FineReader для Windows и Mac является мощным решением для преобразования PDF в текст и дальнейшей работы с ним.
Веб-аналог программы, конечно же, уступает ей по функционалу. Тем не менее сервис умеет распознавать текст со сканов и фотографий на более чем 190 языках. Поддерживается преобразование PDF-файлов в документы Word, Excel и т.п.
Онлайн-сервис ABBYY FineReader Online
- Прежде чем приступить к работе с инструментом, создайте аккаунт на сайте или войдите при помощи учетной записи Facebook, Google или Microsoft.
Чтобы перейти к окну авторизации, щелкните по кнопке «Вход» в верхней панели меню. - Осуществив вход, импортируйте нужный PDF-документ в FineReader, воспользовавшись кнопкой «Загрузить файлы».
Затем нажмите «Выбрать номера страниц» и укажите желаемый промежуток для распознавания текста. - Далее выберите языки, присутствующие в документе, формат итогового файла и нажмите на кнопку «Распознать».
- После обработки, длительность которой полностью зависит от объема документа, вы можете скачать готовый файл с текстовыми данными просто щелкнув по его названию.
Либо же экспортируйте его в один из доступных облачных сервисов.
Сервис отличается, вероятно, наиболее точными алгоритмами распознавания текста на изображениях и PDF-файлах. Но, к сожалению, его бесплатное использование ограничено пятью обрабатываемыми страницами в месяц. Чтобы работать с более объемными документами, придется купить годовую подписку.
Тем не менее, если функция OCR нужна совсем уж редко, ABBYY FineReader Online — отличный вариант для извлечения текста из небольших PDF-файлов.
Способ 2: Free Online OCR
Простой и удобный сервис для оцифровки текста. Без необходимости регистрации ресурс позволяет распознавать 15 полных PDF-страниц в час. Free Online OCR полноценно работает с документами на 46 языках и без авторизации поддерживает три формата экспорта текста — DOCX, XLSX и TXT.
При регистрации пользователь получает возможность обрабатывать многостраничные документы, однако бесплатное количество этих самых страниц ограничено 50 единицами.
Онлайн-сервис Free Online OCR
- Чтобы распознать текст из PDF как «гость», без авторизации на ресурсе, воспользуйтесь соответствующей формой на главной странице сайта.
Выберите нужный документ с помощью кнопки «Файл», укажите основной язык текста, выходной формат, затем дождитесь загрузки файла и нажмите «Конвертировать». - По окончании процесса оцифровки нажмите «Скачать выходной файл» для сохранения готового документа с текстом на компьютере.
Для авторизованных же пользователей последовательность действий несколько иная.
- Воспользуйтесь кнопкой «Регистрация» или «Вход» в верхней панели меню, чтобы, соответственно, создать учетную запись Free Online OCR либо зайти в нее.
- После авторизации в панели распознавания, удерживая клавишу «CTRL», выберите до двух языков исходного документа из предложенного списка.
- Укажите дальнейшие параметры извлечения текста из PDF и нажмите кнопку «Выбрать файл» для загрузки документа в сервис.
Затем, чтобы приступить к распознаванию, щелкните «Конвертировать». - По окончании обработки документа нажмите на ссылку с названием выходного файла в соответствующей колонке.
Результат распознавания сразу же будет сохранен в памяти вашего компьютера.
При необходимости извлечь текст из небольшого PDF-документа можно смело прибегать к использованию вышеописанного инструмента. Для работы же с объемными файлами придется купить дополнительные символы во Free Online OCR либо же прибегнуть к другому решению.
Способ 3: NewOCR
Полностью бесплатный OCR-сервис, позволяющий извлекать текст практически из любых графических и электронных документов вроде DjVu и PDF. Ресурс не накладывает ограничений на размер и количество распознаваемых файлов, не требует регистрации и предлагает широкий набор сопутствующих функций.
NewOCR поддерживает 106 языков и умеет корректно обрабатывать даже низкокачественные сканы документов. Есть возможность вручную выбирать область для распознавания текста на странице файла.
Онлайн-сервис NewOCR
- Так, приступить к работе с ресурсом вы можете сразу, без необходимости выполнения лишних действий.
Прямо на главной странице размещена форма для импорта документа на сайт. Чтобы загрузить файл в NewOCR, воспользуйтесь кнопкой «Выберите файл» в разделе «Select your file». Затем в поле «Recognition language(s)» укажите один или более языков исходного документа, после чего нажмите «Upload + OCR». - Задайте предпочитаемые настройки распознавания, выберите нужную страницу для извлечения текста и щелкните по кнопке «OCR».
- Прокрутите страницу немного ниже и найдите кнопку «Download».
Щелкните по ней и в выпадающем списке выберите необходимый формат документа для скачивания. После этого готовый файл с извлеченным текстом будет загружен на ваш компьютер.
Инструмент удобный и достаточно качественно распознает все символы. Впрочем, обработку каждой страницы импортированного PDF-документа нужно запускать самостоятельно и выводится она в отдельный файл. Можно, конечно, сразу копировать результаты распознавания в буфер обмена и объединять их с другими.
Тем не менее, учитывая вышеописанный нюанс, большие объемы текста с помощью NewOCR извлекать весьма затруднительно. С малыми же файлами сервис справляется «на ура».
Способ 4: OCR.Space
Простой и понятный ресурс для оцифровки текста, позволяет распознавать PDF-документы и выводить результат в TXT-файл. Никаких лимитов по количеству страниц не предусмотрено. Единственное ограничение — размер входного документа не должен превышать 5 мегабайт.
Онлайн-сервис OCR.Space
- Регистрироваться для работы с инструментом не нужно.
Просто перейдите по ссылке выше и загрузите PDF-документ на сайт с компьютера при помощи кнопки «Выберите файл» либо из сети — по ссылке. - В выпадающем списке «Select OCR language» выберите язык импортированного документа.
Затем запустите процесс распознавания текста, щелкнув по кнопке «Start OCR!». - По окончании обработки файла ознакомьтесь с результатом в поле «OCR’ed Result» и нажмите «Download», чтобы скачать готовый TXT-документ.
Если вам нужно просто извлечь текст из PDF и при этом финальное его форматирование совсем не важно, OCR.Space — хороший выбор. Единственное, документ должен быть «одноязычным», так как распознавание двух и более языков одновременно в сервисе не предусмотрено.
Читайте также: Бесплатные аналоги FineReader
Оценивая онлайн-инструменты, представленные в статье, следует отметить, что наиболее точно и качественно с функцией OCR справляется FineReader Online от ABBYY. Если для вас важна именно максимальная точность распознавания текста, лучше всего рассмотреть конкретно этот вариант. Но и заплатить за него, скорее всего, также придется.
Если же нужна оцифровка небольших документов и вы готовы самостоятельно исправлять ошибки за сервисом, целесообразно использовать NewOCR, OCR.Space или Free Online OCR.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТРаспознавание текста OCR в PDF JPG PNG BMP TIF Онлайн Бесплатно
1. ВЫ ПОНИМАЕТЕ И СОГЛАСНЫ С ТЕМ, ЧТО ИСПОЛЬЗУЕТЕ УСЛУГУ НА СВОЙ СТРАХ И РИСК И
ЧТО УСЛУГА ПРЕДОСТАВЛЯЕТСЯ "КАК ЕСТЬ" И "КАК ДОСТУПНО".
2. БЕСПЛАТНОЕ ИСПОЛЬЗОВАНИЕ УСЛУГИ НЕ ПРЕДОСТАВЛЯЕТ И НЕ ГАРАНТИРУЕТ ВАМ, ЧТО:
(A) ИСПОЛЬЗОВАНИЕ УСЛУГИ БУДЕТ ОТВЕЧАТЬ ВАШИМ ТРЕБОВАНИЯМ,
(Б) ИСПОЛЬЗОВАНИЕ УСЛУГИ БУДЕТ НЕПРЕРЫВНО, ГАРАНТИРОВАННО
И БЕЗ ОШИБОК,
(В) ЛЮБАЯ ИНФОРМАЦИЯ, ПОЛУЧЕННАЯ ВАМИ В РЕЗУЛЬТАТЕ ИСПОЛЬЗОВАНИЯ
УСЛУГИ БУДЕТ ТОЧНОЙ И НАДЕЖНОЙ, И
(Г) ЧТО ДЕФЕКТЫ В РАБОТЕ ИЛИ ФУНКЦИОНАЛЬНЫХ ВОЗМОЖНОСТЯХ
ЛЮБОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ, ПРЕДСТАВЛЕННОГО ВАМ КАК ЧАСТЬ УСЛУГИ БУДУТ ИСПРАВЛЕНЫ.
3. ЛЮБОЙ МАТЕРИАЛ ЗАГРУЖЕННЫЙ ИЛИ ПОЛУЧЕННЫЙ С ИСПОЛЬЗОВАНИЕМ УСЛУГИ ВЫ ОТКРЫВАЕТЕ
НА ВАШ СОБСТВЕННЫЙ РИСК, И ЧТО НА ВАС ЛЕЖИТ ОТВЕТСТВЕННОСТЬ ЗА ЛЮБЫЕ ПОВРЕЖДЕНИЯ
КОМПЬЮТЕРА ИЛИ ДРУГОГО УСТРОЙСТВА, ИЛИ ЗА ПОТЕРЮ ДАННЫХ В РЕЗУЛЬТАТЕ ЗАГРУЗКИ ЭТИХ
МАТЕРИАЛОВ.
4. МЫ НЕ ХРАНИМ ВАШИ ФАЙЛЫ НА НАШИХ СЕРВЕРАХ.
Как распознать текст в PDF
ABBYY- Контакты
- Интернет-магазин
- Русский Chinese 中文 Croatian Hrvatski English English French Français German Deutsch Hungarian Magyar Italian Italiano Japanese 日本語 Korean 한국어 Polish Polski
7 инструментов для распознавания текста онлайн и офлайн
1. Office Lens
- Платформы: Android, iOS, Windows.
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.
Цена: Бесплатно
Цена: Бесплатно
Разработчик: Microsoft Corporation
Цена: Бесплатно
2. Adobe Scan
- Платформы: Android, iOS.
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
Разработчик: AdobeЦена: Бесплатно
Цена: Бесплатно
3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2.
FineReader славится высокой точностью распознавания. Увы, бесплатные возможности инструмента ограниченны: после регистрации вам позволят отсканировать всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Подписка стоимостью 129 евро позволяет сканировать до 5 000 страниц в год, а также открывает доступ к десктопному редактору PDF‑файлов.
Перейти на сайт FineReader →
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
Перейти на сайт Online OCR →
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
Перейти на сайт img2txt →
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
Скачать Microsoft OneNote →
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
Скачать Readiris 17 →
Читайте также 💻📎🖌
PDF OCR - Распознать текст - 100% бесплатно
Как распознать текст
Выберите файлы, для которых нужно применить OCR, или перетащите файлы в файловый ящик. Измените настройки и запустите OCR. Через несколько секунд вы сможете загрузить новые файлы PDF с возможностью поиска.
Настройки OCR
Вы можете изменить несколько настроек для управления процессом распознавания текста. Вы можете сохранять как PDF / A, удалять артефакты и шум, выравнивать страницы, устанавливать метаинформацию и присоединяться к одному выходному файлу.
Простота использования
PDF24 максимально упрощает распознавание текста с помощью OCR. Вам не нужно устанавливать какое-либо программное обеспечение и беспокоиться о нем, вам просто нужно выбрать файлы, для которых вы хотите применить OCR.
Поддерживает вашу систему
Для распознавания текста через OCR не требуется никакой специальной системы. Это приложение OCR работает в вашем браузере и, следовательно, работает во всех операционных системах. Просто перетащите файлы и запустите OCR.
Установка не требуется
Вам не нужно загружать или устанавливать какое-либо программное обеспечение.Текст распознается на наших серверах в облаке и поэтому не потребляет никаких ресурсов вашего компьютера.
Безопасность важна для нас
Этот инструмент OCR не хранит ваши файлы на нашем сервере дольше, чем необходимо. Ваши файлы и результаты будут удалены с нашего сервера через короткий промежуток времени. Передача файлов защищена SSL.
.Самый простой способ распознать поля формы PDF

2020-10-28 21:01:40 • Отправлено в: Практическое руководство • Проверенные решения
Если у вас есть PDF-форма, в которой вы не можете выбирать текстовые поля, тогда такой тип файла известен как неинтерактивная PDF-форма. Для такой формы PDF вам необходимо распознать ее, чтобы вы могли сделать поля интерактивными, что позволит вам выделять текстовые поля, копировать тексты и легко сохранять их.Поэтому в этой статье показано, как сделать PDF для распознавания формы с помощью PDFelement.
3 шага для распознавания формы PDF с помощью PDFelement
Следующие шаги помогут вам распознать поля формы PDF.
Шаг 1. Откройте PDF-форму
Начните с загрузки файла формы PDF в PDFelement. Нажмите «Открыть файл», и вы сможете загрузить желаемую PDF-форму. Как вариант, вы можете перетащить PDF-форму, она будет загружена в программу.
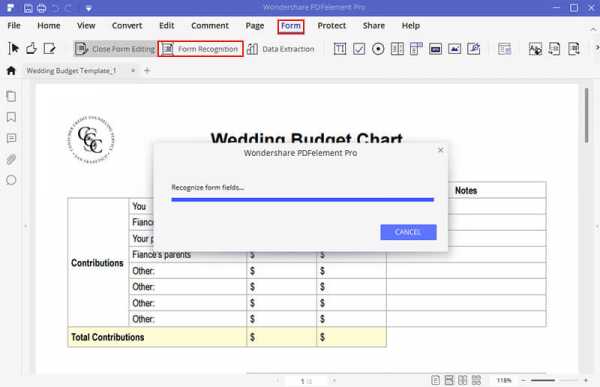
Шаг 2. Распознавание PDF-формы
Когда PDF-форма была загружена в программу, перейдите на панель инструментов и нажмите «Форма», а под ней нажмите «Распознавание форм». Появится всплывающее окно с сообщением «Операция не может быть отменена, вы хотите продолжить?» Щелкните по кнопке «Да». Программа автоматически начнет распознавать тексты полей формы. Поля будут выделены после завершения процесса.
Перейдите в левый верхний угол и нажмите кнопку «Закрыть поле формы».Оттуда вы можете просто навести курсор на любое текстовое поле и заполнить его.
Шаг 3. Сохраните PDF форму
После распознавания и заполнения полей формы в форме PDF не забудьте сохранить ее, чтобы изменения были постоянными. Нажмите «Command + S» или, если вы хотите переименовать его, нажмите кнопку «Файл> Сохранить как». Это все, что вам нужно сделать, чтобы распознать текстовое поле PDF-формы.
Видео о том, как распознать PDF-форму
PDFelement может распознавать формы PDF, чтобы сделать их заполняемыми, извлекать данные из форм PDF, создавать заполняемые формы PDF.Он также может создавать файлы PDF, редактировать файлы PDF, конвертировать PDF-файлы и защищать их паролями.
- Он создает файлы PDF путем объединения файлов PDF или других типов файлов в один файл PDF.
- Это мощный PDF-ридер с режимами прокрутки, возможностью навигации по страницам, режимами чтения и эскизами.
- Это редактор PDF, который редактирует изображения, тексты и объекты без потери форматирования.
- Он организует файлы PDF путем удаления, вставки, переупорядочивания, извлечения и обрезки страниц.
- Он поддерживает пакетное извлечение данных, преобразование, добавление нумерации битов и водяных знаков.
- Он поддерживает такие форматы вывода, как HTML, EBUP, PPT, DOCS, XLS, BMP, PNG, TXT, JPEG и другие.
- Он имеет плагин OCR, который распознает файлы PDF, так что вы можете редактировать, копировать и вставлять файлы.
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
.
c # - Как распознать текст в порядке PDF?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
c # - Как распознать таблицы внутри файла pdf
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Рекламная
Создание PDF-файла с возможностью поиска по тексту
Отправка PDF-файлов с возможностью поиска по тексту
Все PDF-файлы, представленные в суд, должны иметь возможность поиска по тексту. Местный Правило 25.1 (e); Местное правило 25.2 (б) (3).
Как определить, доступен ли PDF для поиска по тексту
После открытия PDF-файла попробуйте найти слово, которое, как известно, документ (желательно слово, которое встречается на нескольких разные страницы), нажав CTRL-F и введя слово в поле Найти .
Если появляется сообщение ниже, документ не с возможностью текстового поиска.
Или же используйте мышь, чтобы выделить слово в тексте.Если невозможно выделить одно слово и вся страница становится синим, чтобы указать, что это изображение, текст не с возможностью поиска.
Как сделать PDF-файл доступным для поиска по тексту
Следующие инструкции относятся к созданию PDF-файлов. с возможностью поиска по тексту в Adobe Acrobat Professional или Standard:
Щелкните Инструменты > Распознавание текста> В этом файле.
Откроется всплывающее окно Распознать текст . Выберите Все страницы , затем щелкните ОК .
Процесс распознавания текста будет выполняться постранично.пожалуйста обратите внимание, что для очень длинного документа процесс может занять несколько минут на выполнение.
Включение возможности поиска по тексту в сразу несколько документов можно выполнить, выбрав Инструменты> Распознавание текста> В нескольких файлах .
Откроется диалоговое окно Распознать текст для добавления файлов или папок документов, которые будут доступны для поиска по тексту.
Когда все файлы или папки добавлены, нажмите OK, чтобы начать процесс распознавания текста. Если выбрано много файлов или папок, обработка распознавания текста может занять довольно много времени.
Когда все страницы во всех документах обработаны, попробуйте тот же поиск, чтобы убедиться, что каждый документ теперь доступен для поиска по тексту.
Последнее изменение: 23.05.2016.
.Как быстро редактировать отсканированные файлы PDF

2020-12-11 22:10:18 • Отправлено в: Практическое руководство • Проверенные решения
Отсканированные PDF-документы - одни из самых сложных для работы типов файлов. Когда вы сканируете документ и сохраняете его непосредственно в формате PDF, весь текст, диаграммы, графика и изображения объединяются в большой файл изображения, который нельзя редактировать.Если вы хотите упростить работу с отсканированным документом, вам нужно будет разбить большое изображение на управляемые элементы в документе. Давайте узнаем, как отредактировать отсканированные файлы PDF с помощью PDFelement.
Как редактировать отсканированный PDF-файл в Windows 10
Технология OCR может показаться пугающей, но ее действительно легко использовать с лучшей программой для редактирования отсканированных файлов PDF в Windows 10.
Шаг 1. Импортируйте PDF в PDFelement
Запустите PDFelement и нажмите кнопку «Открыть файлы» на главной странице.Выберите файл и нажмите «Открыть», чтобы загрузить файл в программу.
Шаг 2. Выполните оптическое распознавание текста отсканированного документа
Появится всплывающее сообщение с напоминанием о необходимости выполнить распознавание текста для отсканированного файла PDF. Нажмите кнопку «Выполнить распознавание текста», и программа попросит вас выбрать языковой источник PDF-файла, чтобы помочь ему распознать текст.
Шаг 3. Редактировать отсканированный файл PDF
После завершения оптического распознавания текста вы сможете соответствующим образом отредактировать файл PDF.Откройте вкладку «Редактировать», чтобы увидеть диапазон изменений, которые вы можете внести в отсканированный файл PDF.
Измените текст в PDF-файле, щелкнув значок «Редактировать» на верхней правой панели инструментов. Щелкните в любом месте документа, чтобы добавить, удалить или изменить существующий текст. Добавьте новый набор текстов, нажав кнопку «Добавить текст».
Щелкните любой объект в файле PDF, чтобы редактировать изображения и диаграммы. Вы можете удалить объект, щелкнув его правой кнопкой мыши и выбрав опцию «Удалить». Вы также можете вырезать или копировать объекты, используя этот шаг.Выберите объект, чтобы переместить его в документ. Чтобы добавить в документ новый файл изображения, нажмите кнопку «Добавить изображение».
Шаг 4. Сохраните отредактированный отсканированный PDF-файл
В процессе редактирования не забывайте нажимать «Ctrl + S», чтобы сохранить свою работу. Если вы довольны своим файлом, перейдите в «Файл» и выберите «Сохранить как». Выберите папку назначения и нажмите кнопку «Сохранить».
Видео о том, как редактировать отсканированный PDF-файл с помощью PDFelement
Вам может быть интересно, как преобразовать отсканированный PDF-файл в редактируемые PDF-файлы.Инструмент для редактирования PDF-файлов с лучшим сканированием может редактировать, конвертировать, создавать, защищать, подписывать и печатать ваши PDF-файлы, а также заполнять PDF-формы без необходимости их распечатывать. Плагин PDFelement OCR - полезная функция. Он отлично справляется с сохранением внешнего вида документа при его преобразовании в читаемый, редактируемый и доступный для поиска файл PDF. Он поддерживает широкий спектр языков (например, английский, корейский, итальянский, индонезийский, французский, немецкий, русский, чешский, турецкий, арабский, португальский и т. Д.)), что означает, что вы можете использовать эту функцию независимо от того, какой язык вы используете.
Другие решения для отсканированных редакторов PDF с OCR
1. Nitro PDF Editor (Nitro Pro)
Nitro PDF Editor - это программа, которая имеет широкие функциональные возможности для редактирования всех типов PDF-документов, включая отсканированные. Вы можете организовать и очистить свои документы, используя функцию присвоения номера страницы. Вы можете добавлять водяные знаки, закладки или логотипы по своему усмотрению.
Плюсы:
- Добавление, редактирование или удаление битов PDF с номером
- Предлагает функцию OCR
- Вставка, поворот или извлечение отдельных страниц
Минусы:
- Цена довольно высокая
- Отсутствует поддержка индексации PDF
- Сбой OCR при работе с большими документами
Поддерживающая ОС: Windows
Цена: 159.99 $
Оценок: Мы оцениваем это на 3 звезды.
2. Adobe ® Acrobat ®
Adobe - это имя, которое довольно популярно в мире PDF из-за большого разнообразия функций. Однако он содержит множество функций, которые никогда не понадобятся обычному пользователю. Он поставляется с автоматическим распознаванием текста, который можно использовать для редактирования отсканированных файлов PDF и файлов PDF на основе изображений. Однако поддержка Adobe ® Acrobat ® XI закончилась в 2017 году. В этом случае вы можете щелкнуть здесь, чтобы узнать о лучших альтернативах Adobe Acrobat.
Плюсы:
- Эффективный и свежий интерфейс
- Доступна облачная служба документов
- Встроенная маршрутизация и подпись PDF
Минусы:
- Невозможно отменить OCR после его выполнения
- Модель подписки сложная и запутанная
- Стоимость очень высокая
Поддерживающая ОС: Windows и Mac
Цена: 14 долларов.99 в месяц
Оценок: Мы оцениваем это на 4 звезды.
3. Apower PDF Editor - бесплатный отсканированный PDF-редактор
Если вам нужен редактор PDF для файлов изображений и отсканированных файлов, редактор Apower PDF имеет полезную поддержку технологии OCR. Он также имеет несколько дополнительных функций, таких как добавление верхнего или нижнего колонтитула, удаление защищенных данных в PDF, а также функции заполнения или создания форм.
Плюсы:
- Преобразование отсканированных документов и документов на основе изображений в редактируемые PDF-файлы
- Управление страницами вашего PDF-файла
Минусы:
- Неинтуитивный интерфейс
- Медленно загружается при работе с большими документами
Поддерживающая ОС: Windows
Цена: Бесплатно
Оценок: Мы оцениваем 3.5.
Полезные советы по редактированию отсканированных PDF-файлов с помощью OCR
- Перед сканированием всей стопки документов протестируйте страницы с различными настройками и примените OCR, чтобы проверить, насколько хорошо оно работает с ними. Используйте настройки, при которых распознавание текста дает наилучший результат.
- Высококачественные отсканированные изображения обеспечивают наилучшие результаты распознавания текста. Как правило, для наилучших результатов распознавания убедитесь, что отсканированный документ имеет разрешение от 300 до 600 dpi.
- Текст, покрывающий слишком яркую или темную графику в исходном документе, не будет распознан OCR, потому что контраст между ними недостаточно высок.Если это проблема, отрегулируйте контрастность, чтобы функция распознавания текста могла прочитать текст.
- Для наилучшего результата используйте настройку черно-белого изображения.
- Убедитесь, что исходный документ лежит ровно на планшете сканера, чтобы избежать искажения текста, что может "сбить с толку" OCR.

Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
.