Что такое степень сжатия файла как ее определить
Как узнать степень сжатия файлов архива пошаговая инструкция
E-mail: [email protected]
Этот сайт использует cookie для хранения данных. Продолжая использовать сайт, Вы даете свое согласие на работу с этими файламиВНИМАНИЕ! При копировании материалов с сайта, активная обратная ссылка на kompmix.ru - обязательна.
kompmix.ru © 2021 Все права защищены.
Показатель степени сжатия файлов — Студопедия.Нет
Реферат на тему: "Программы-архиваторы"
Выполнила: Дмитриева Диана
Содержание
1.Введение
2.Основные виды программ-архиваторов
3.Сжатие файлов при архивации
4. Показатель степени сжатия файлов
5. Оценка функциональности самых популярных архиваторов
5.1 WinZip
5.2 WinRAR
5.3 WinAce
5.4 7-Zip
6.Заключение
7.Список литературы
Введение
Архивация - это сжатие, уплотнение, упаковка информации с целью ее более рационального размещения на внешнем носителе (диске или дискете). Архиваторы - это программы, реализующие процесс архивации, позволяющие создавать и распаковывать архивы.
Необходимость архивации связана с резервным копированием информации на диски и дискеты с целью сохранения программного обеспечения компьютера и защиты его от порчи и уничтожения (умышленного, случайного или под действием компьютерного вируса). Чтобы уменьшить потери информации, следует иметь резервные копии всех программ и файлов.
Программы-упаковщики (архиваторы) позволяют за счет специальных методов сжатия информации создавать копии файлов меньшего размера и объединять копии нескольких файлов в один архивный файл. Это даёт возможность на дисках или дискетах разместить больше информации, то есть повысить плотность хранения информации на единицу объёма носителя (дискеты или диска).
Кроме того, архивные файлы широко используются для передачи информации в Интернете и по электронной почте, причем благодаря сжатию информации повышается скорость её передачи. Это особенно важно, если учесть, что быстродействие модема и канала связи (телефонной линии) намного меньше, чем процессора и жесткого диска.
Работа архиваторов основана на том, что они находят в файлах повторяющиеся участки и пробелы, помечают их в архивном файле и затем при распаковке восстанавливают по этим отметкам исходные файлы.
Программы-упаковщики (или архиваторы) позволяют помещать копии файлов в архив и извлекать файлы из архива, просматривать оглавление архива и тестировать его целостность, удалять файлы, находящиеся в архиве, и обновлять их, устанавливать пароль при извлечении файлов из архива и др. Разные программы архивации отличаются форматом архивных файлов, скоростью работы, степенью сжатия, набором услуг (полнотой меню для пользователя), удобством пользования (интерфейсом), наличием помощи, собственным размером.
Ряд архиваторов позволяют создавать многотомные архивы, самоизвлекающиеся архивы, архивы, содержащие каталоги. Наиболее популярны и широко используются следующие архиваторы: ARJ, PKZIP/PKUNZIP, RAR, ACE, LHA, ICE, PAK, PKARC/PKXARC, ZOO, HYPER, AIN.
Наиболее высокоэффективными являются архиваторы RAR, ACE, AIN, ARJ.
Основные виды программ-архиваторов
Различными разработчиками были созданы специальные программы для архивации файлов. Как правило, программы для архивации файлов позволяют помещать копии файлов на диске в сжатом виде в архивный файл, извлекать файлы из архива, просматривать оглавление архива и т.д. Разные программы отличаются форматом архивных файлов, скоростью работы, степенью сжатия файлов при помещении в архив, удобством использования.
В настоящее время применяется несколько десятков программ - архиваторов, которые отличаются перечнем функций и параметрами работы, однако лучшие из них имеют примерно одинаковые характеристики. Из числа наиболее популярных программ можно выделить:, PKPAK, LHA, ICE, HYPER, ZIP, РАК, ZOO, EXPAND, разработанные за рубежом, а также AIN и RAR, разработанные в России. Обычно упаковка и распаковка файлов выполняются одной и той же программой, но в некоторых случаях это осуществляется разными программами, например, программа РКZIР производит упаковку файлов, a PKUNZIP - распаковку файлов.
Программы-архиваторы позволяют создавать и такие архивы, для извлечения из которых содержащихся в них файлов не требуются какие - либо программы, так как сами архивные файлы могут содержать программу распаковки. Такие архивные файлы называются самораспаковывающимися.
Самораспаковывающийся архивный файл - это загрузочный, исполняемый модуль, который способен к самостоятельной разархивации находящихся в нем файлов без использования программы - архиватора.
Самораспаковывающийся архив получил название SFX - архив (SelF - eXtracting).
архиватор сжатие упаковщик потеря
Сжатие файлов при архивации
Все алгоритмы сжатия оперируют входным потоком информации с целью получения более компактного выходного потока при помощи некоторого преобразования. Основными техническими характеристиками процессов сжатия и результатов их работы являются:
·степень сжатия - отношение объемов исходного и результирующего потоков;
·скорость сжатия - время, затрачиваемое на сжатие некоторого объема информации входного потока, до получения из него эквивалентного выходного потока;
·качество сжатия - величина, показывающая, на сколько сильно упакован выходной поток при применении к нему повторного сжатия по тому же или другому алгоритму.
Алгоритмы, которые устраняют избыточность записи данных, называются алгоритмами сжатия данных, или алгоритмами архивации. В настоящее время существует огромное множество программ для сжатия данных, основанных на нескольких основных способах.
Все алгоритмы сжатия данных делятся на:
) алгоритмы сжатия без потерь, при использовании которых данные на приемной восстанавливаются без малейших изменений;
)алгоритмы сжатия с потерями, которые удаляют из потока данных информацию, незначительно влияющую на суть данных, либо вообще невоспринимаемую человеком.
Существует два основных метода архивации без потерь:
алгоритм Хаффмана (англ. Huffman), ориентированный на сжатие последовательностей байт, не связанных между собой,
алгоритм Лемпеля-Зива (англ. Lempel, Ziv), ориентированный на сжатие любых видов текстов, то есть использующий факт неоднократного повторения "слов" - последовательностей байт.
Практически все популярные программы архивации без потерь (ARJ, RAR, ZIP и т.п.) используют объединение этих двух методов - алгоритм LZH.
Алгоритм Хаффмана.
Алгоритм основан на том факте, что некоторые символы из стандартного 256-символьного набора в произвольном тексте могут встречаться чаще среднего периода повтора, а другие, соответственно, - реже. Следовательно, если $+o записи распространенных символов использовать короткие последовательности бит, длиной меньше 8, а для записи редких символов - длинные, то суммарный объем файла уменьшится.
Алгоритм Лемпеля-Зива. Классический алгоритм Лемпеля-Зива -LZ77, названный так по году своего опубликования, предельно прост. Он формулируется следующим образом: если в прошедшем ранее выходном потоке уже встречалась подобная последовательность байт, причем запись о ее длине и смещении от текущей позиции короче чем сама эта последовательность, то в выходной файл записывается ссылка (смещение, длина), а не сама последовательность.
Показатель степени сжатия файлов
Сжатие информации в архивных файлах производится за счет устранения избыточности различными способами, например за счет упрощения кодов, исключения из них постоянных битов или представления повторяющихся символов или повторяющейся последовательности символов в виде коэффициента повторения и соответствующих символов. Алгоритмы подобного сжатия информации реализованы в специальных программах-архиваторах (наиболее известные из которых arj/arjfolder, pkzip/pkunzip/winzip, rar/winrar) применяются определенные Сжиматься могут как один, так и несколько файлов, которые в сжатом виде помещаются в так называемый архивный файл или архив.
Целью упаковки файлов обычно являются обеспечение более компактного размещения информации на диске, сокращение времени и соответственно стоимости передачи информации по каналам связи в компьютерных сетях. Поэтому основным показателем эффективности той или иной программы-архиватора является степень сжатия файлов.
Степень сжатия файлов характеризуется коэффициентом Кс, определяемым как отношение объема сжатого файла Vc к объему исходного файла Vо, выраженное в процентах (в некоторых источниках используется обратное соотношение):
Кс=(Vc/Vo)*100%
Степень сжатия зависит от используемой программы, метода сжатия и типа исходного файла.
Наиболее хорошо сжимаются файлы графических образов, текстовые файлы и файлы данных, для которых коэффициент сжатия может достигать 5 - 40%, меньше сжимаются файлы исполняемых программ и загрузочных модулей Кс = 60 - 90%. Почти не сжимаются архивные файлы. Это нетрудно объяснить, если знать, что большинство программ-архиваторов используют для сжатия варианты алгоритма LZ77 (Лемпеля-Зива), суть которого заключается в особом кодировании повторяющихся последовательностей байт (читай - символов). Частота встречаемости таких повторов наиболее высока в текстах и точечной графике и практически сведена к нулю в архивах.
Кроме того, программы для архивации все же различаются реализациями алгоритмов сжатия, что соответственно влияет на степень сжатия.
В некоторые программы-архиваторы дополнительно включаются средства, направленные на уменьшение коэффициента сжатия Кс. Так в программе WinRAR реализован механизм непрерывного (solid) архивирования, при использовании которого может быть достигнута на 10 - 50% более высокая степень сжатия, чем дают обычные методы, особенно если упаковывается значительное количество небольших файлов однотипного содержания.
Характеристики архиваторов - обратно зависимые величины. То есть, чем больше скорость сжатия, тем меньше степень сжатия, и наоборот.
На компьютерном рынке предлагается множество архиваторов - у каждого свой набор поддерживаемых форматов, свои плюсы и минусы, свой круг почитателей, свято верящих в то, что используемый ими архиватор самый лучший. Не будем никого и ни в чем разубеждать - просто попытаемся беспристрастно оценить самые популярные архиваторы в плане функциональности и эффективности. К таковым отнесем WinZip, WinRAR, WinAce, 7-Zip - они лидируют по количеству скачиваний на софтовых серверах. Рассматривать остальные архиваторы вряд ли целесообразно, поскольку процент применяющих их пользователей (судя по числу скачиваний) невелик.
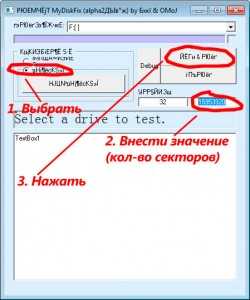
Как посмотреть степень сжатия архива – инструкция
Приветствую!
В этой подробной пошаговой инструкции, с фотографиями, мы покажем вам, как узнать степень сжатия файлов в архиве.
Воспользовавшись этой инструкцией, вы с легкостью справитесь с данной задачей.
Узнаём степень сжатия архива
Для определения степени сжатия на компьютере должен быть установлен архиватор WinRar. Если он у вас не установлен, то вот в этой подобной пошаговой инструкции рассказывается о том, где его бесплатно скачать и как установить.
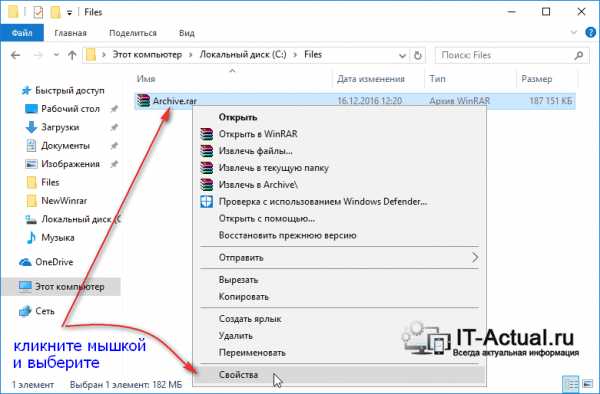 Вызовите контекстное меню, кликнув правой клавишей мышки на интересующем архиве, для которого требуется определить степень сжатия.
Вызовите контекстное меню, кликнув правой клавишей мышки на интересующем архиве, для которого требуется определить степень сжатия.
В нём выберите пункт Свойства.
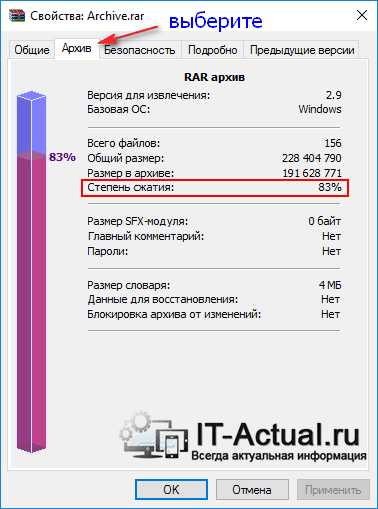 В открывшемся окне перейдите во вкладку Архив. Там в строке Степень сжатия будет указан интересующий нас параметр.
В открывшемся окне перейдите во вкладку Архив. Там в строке Степень сжатия будет указан интересующий нас параметр.
Если у вас остались вопросы, вы можете задать их в комментариях.
Мы рады, что смогли помочь Вам в решении поставленной задачи или проблемы.В свою очередь, Вы тоже можете нам очень помочь.
Просто поделитесь статьей в социальных сетях и мессенджерах с друзьями.
Поделившись результатами труда автора, вы окажете неоценимую помощь как ему самому, так и сайту в целом. Спасибо!
Опрос: помогла ли вам эта статья?(cбор пожертвований осуществляется через сервис «ЮMoney»)
На что пойдут пожертвования \ реквизиты других платёжных систем Привет.Не секрет, что в экономике ныне дела обстоят не лучшим образом, цены растут, а доходы падают. И данный сайт также переживает нелёгкие времена :-(
Если у тебя есть возможность и желание помочь развитию ресурса, то ты можешь перевести любую сумму (даже самую минимальную) через форму пожертвований, или на следующие реквизиты:
Номер банковской карты: 5331 5721 0220 5546
Кошелёк ЮMoney: 410015361853797
Кошелёк WebMoney: P865066858877
PayPal: [email protected]
BitCoin: 1DZUZnSdcN6F4YKhf4BcArfQK8vQaRiA93
Оказавшие помощь:
Сергей И. - 500руб
<аноним> - 468руб
<аноним> - 294руб
Мария М. - 300руб
Валерий С. - 420руб
<аноним> - 600руб
Полина В. - 240руб
Деньги пойдут на оплату хостинга, продление домена, администрирование и развитие ресурса. Спасибо.
С уважением, создатель сайта IT-Actual.ru
От чего зависит степень сжатия файла? Понятие и основные аспекты
Большинство пользователей знает, что иногда для уменьшения размера исходных файлов с целью повышения удобства их хранения или отправки, например, по электронной почте применяется сжатие. Однако почему-то в этом случае ассоциация происходит только с приложениями-архиваторами, а другие методики сжатия данных в расчет не принимаются. Далее будет рассмотрено, от чего зависит степень сжатия файла, на примере нескольких наиболее распространенных ситуаций.
Что подразумевается под степенью сжатия файла?
Начнем с теоретических вопросов. Что же такое степень сжатия файла? Исходя из самых простых трактовок этого термина, под ним подразумевается соотношение размера конечного (сжатого) объекта к начальному объему. Однако такое пояснение в большей степени может относиться исключительно к архивным данным, поскольку совершенно не затрагивает некоторые вопросы, связанные с изменением формата мультимедиа, где сжатие также очень распространено. В общем же, говорить о том, что степень сжатия файла зависит только от какого-то одного признака, нельзя. В данном случае роль играет и тип объекта, и используемые для сжатия данных программы, и скорость проведения процесса сжатия. Далее кратко остановимся на некоторых важных аспектах, которые могут повлиять на конечный результат уменьшения размера исходных данных.
Степень сжатия файла зависит только от типа файла: так ли это на самом деле?
Да, действительно, тип сжимаемых данных оказывает на уменьшение конечного размера файла достаточно большое влияние, и далеко не все форматы можно подвергнуть таким процедурам. Пояснить это можно на примере звуковых файлов формата MP3, которые изначально уже самим по себе являются сжатыми.
При попытке упаковки таких данных в архив существенного уменьшения размера добиться практически невозможно. То же самое касается формата WAV. Однако, если произвести не сжатие, а перекодирование из WAV в MP3, размер можно уменьшить раз в десять и более. Многие пользователи тут же и отталкиваются от того, что степень сжатия файла зависит именно от начального и конечного формата. Это не совсем так, поскольку важную роль играет и применяемый алгоритм перекодирования, о чем будет сказано отдельно. А пока остановимся на использовании архиваторов.
От чего зависит степень сжатия файла при упаковке в архив?
Чтобы изначально понять суть сжатия такого типа, для простоты объяснения в пример приведем самый обычный архиватор WinRAR. Типы упаковываемых данных не трогаем, а основное внимание сосредоточим на инструментах самого приложения.
Для начала следует обратить внимание на конечный формат архива, а также на используемый метод упаковки. Понятно, что в этом случае степень сжатия файла программой архивации зависит от предпочитаемой методики. При скоростном методе сжатие будет минимальным, но при установке максимальной степени сжатия размер будет уменьшен более существенно, а времени потребуется больше.
Если же применительно к архиваторам рассматривать файловые форматы, из самых сжимаемых можно выделить текстовые документы любых форматов.
Относительно неплохо сжимаются некоторые исполняемые файлы EXE-формата (при стандартном методе сжатия можно добиться уменьшения размера больше, чем вполовину). Самыми, как уже говорилось, несжимаемыми являются объекты мультимедиа. И, если картинки уменьшить по размеру хоть как-то можно, с аудио и видео без изменения начального формата такие действия не проходят, и архиваторы тут совершенно ни причем.
Типы сжатия графики, видео и аудио
Применительно к мультимедиа различают два основных типа сжатия: с потерей качества (lossy) и без потерь (lossless). И в данном случае степень сжатия файла зависит как раз от используемой технологии компрессии.
В первом случае сжатие максимальное, во втором оно может варьироваться, на что влияет используемый набор кодеков и конечный формат контейнера. Так, например, один и тот же AVI-файл может представлять собой именно контейнер, содержащий совершенно разные по типу данные и с различной степенью компрессии. Из-за этого, кстати, иногда могут наблюдаться проблемы с воспроизведением видео на бытовых плеерах.
А вообще, если говорить именно о мультимедиа, тут нужно четко понимать, что добиться максимального уменьшения размера исходного файла любого формата без существенной потери качества практически нереально, несмотря даже на технологии удаления избыточного контента (например, для графики или видео это срабатывает только в случае с неизменяемыми сценами). В случае с аудио производится уменьшение битрейта и вырезание определенных частот. Рядовой пользователь разницы, может быть, и не ощутит, а вот профессионал с тонким слухом сразу скажет, чего не хватает.
Самые распространенные программы на все случаи жизни
От чего зависит степень сжатия файла, немного разобрались. Теперь следует сказать несколько слов о применяемых программных продуктах. Среди архиваторов самыми распространенными можно назвать WinRAR, WinZIP и 7-Zip.
Что же касается сжатия мультимедиа, в самом простом случае можно использовать специальные приложения-конвертеры, которые работают по принципу перекодирования исходного материала в другой формат с целью уменьшения размера файла.
Краткие итоги
Подводя своеобразный итог, можно отметить, что степень сжатия файла архиватором зависит от нескольких факторов, а чаще всего от типа данных, подвергаемых компрессии, используемого программного обеспечения и методов сжатия (обычно применяются алгоритмы Хаффмана и Лемпеля-Зива, работающие в паре). В случае с мультимедиа-контентом ситуация практически та же, однако главенствующее положение занимает преобразование формата из одного в другой.
Сжатие информации без потерь. Часть первая / Хабр
Доброго времени суток.Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Третья группа методов – это так называемые методы преобразования блока. Входящие данные разбиваются на блоки, которые затем трансформируются целиком. При этом некоторые методы, особенно основанные на перестановке блоков, могут не приводить к существенному (или вообще какому-либо) уменьшению объема данных. Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики
Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F = {p(si)} неизменно, и вероятности элементов взаимно независимы, то средняя длина кодов может быть рассчитана как
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.
Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.
Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.
Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 <-> B1
a2 <-> B2
…
an <-> Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B'B''. Тогда B' называют началом, или префиксом слова B, а B'' — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Итак, мы разобрались с основными определениями. Так как же происходит само кодирование без памяти?
Оно происходит в три этапа.
- Составляется алфавит Ψ символов исходного сообщения, причем символы алфавита сортируются по убыванию их вероятности появления в сообщении.
- Каждому символу ai из алфавита Ψ ставится в соответствие некое слово Bi из префиксного множества Ω.
- Осуществляется кодирование каждого символа, с последующим объединением кодов в один поток данных, который будет являться результатам сжатия.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
В первую очередь при кодировании алгоритмом Хаффмана, нам нужно построить схему ∑. Делается это следующим образом:
- Все буквы входного алфавита упорядочиваются в порядке убывания вероятностей. Все слова из алфавита выходного потока (то есть то, чем мы будем кодировать) изначально считаются пустыми (напомню, что алфавит выходного потока состоит только из символов {0,1}).
- Два символа aj-1 и aj входного потока, имеющие наименьшие вероятности появления, объединяются в один «псевдосимвол» с вероятностью p равной сумме вероятностей входящих в него символов. Затем мы дописываем 0 в начало слова Bj-1, и 1 в начало слова Bj, которые будут впоследствии являться кодами символов aj-1 и aj соответственно.
- Удаляем эти символы из алфавита исходного сообщения, но добавляем в этот алфавит сформированный псевдосимвол (естественно, он должен быть вставлен в алфавит на нужное место, с учетом его вероятности).
Шаги 2 и 3 повторяются до тех пор, пока в алфавите не останется только 1 псевдосимвол, содержащий все изначальные символы алфавита. При этом, поскольку на каждом шаге и для каждого символа происходит изменение соответствующего ему слова Bi (путем добавление единицы или нуля), то после завершения этой процедуры каждому изначальному символу алфавита ai будет соответствовать некий код Bi.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — { a1, a2, a3, a4}. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:
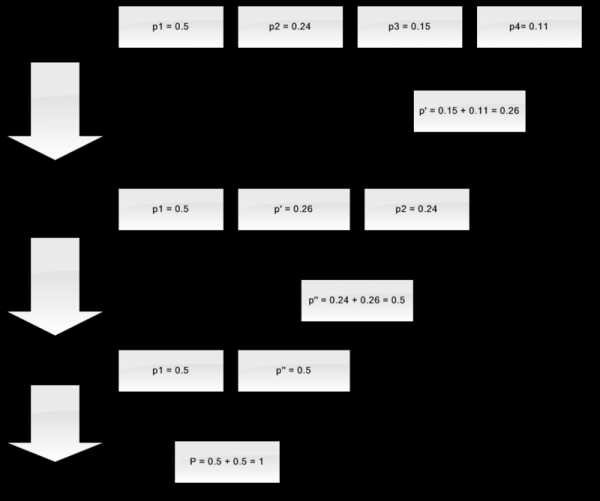
Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
a1 = 0
a2 = 11
a3 = 100
a4 = 101
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Литература
- Ватолин Д., Ратушняк А., Смирнов М. Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео; ISBN 5-86404-170-X; 2003 г.
- Д. Сэломон. Сжатие данных, изображения и звука; ISBN 5-94836-027-Х; 2004г.
- www.wikipedia.org
Степень сжатия данных - Data compression ratio
Степень сжатия данных , также известная как мощность сжатия , является мерой относительного уменьшения размера представления данных, создаваемого алгоритмом сжатия данных. Обычно это выражается как деление несжатого размера на сжатый.
Определение
Степень сжатия данных определяется как соотношение между размером несжатого и сжатого файлов :
- C о м п р е s s я о п р а т я о знак равно U п c о м п р е s s е d S я z е C о м п р е s s е d S я z е {\ displaystyle {\ rm {Compression \; Ratio}} = {\ frac {\ rm {Uncompressed \; Size}} {\ rm {Compressed \; Size}}}}
Таким образом, представление, которое сжимает размер хранилища файла с 10 МБ до 2 МБ, имеет коэффициент сжатия 10/2 = 5, часто обозначаемый как явное соотношение, 5: 1 (читается как «пять» к «одному») или как неявное соотношение 5/1. Эта формулировка в равной степени применима к сжатию, когда размер несжатого файла равен размеру оригинала; и для декомпрессии, где размер без сжатия - это размер воспроизведения.
Иногда вместо этого дается экономия места , которая определяется как уменьшение размера по сравнению с размером без сжатия:
- S п а c е S а v я п г знак равно 1 - C о м п р е s s е d S я z е U п c о м п р е s s е d S я z е {\ displaystyle {\ rm {Пробел \; Сохранение}} = 1 - {\ frac {\ rm {Сжатый \; Размер}} {\ rm {Несжатый \; Размер}}}}
Таким образом, представление, которое сжимает размер хранилища файла с 10 МБ до 2 МБ, дает экономию пространства 1-2/10 = 0,8, часто выраженную в процентах, 80%.
Для сигналов неопределенного размера, таких как потоковое аудио и видео, степень сжатия определяется в терминах скорости несжатых и сжатых данных вместо размеров данных:
- C о м п р е s s я о п р а т я о знак равно U п c о м п р е s s е d D а т а р а т е C о м п р е s s е d D а т а р а т е {\ displaystyle {\ rm {Compression \; Ratio}} = {\ frac {\ rm {Uncompressed \; Data \; Rate}} {\ rm {Compressed \; Data \; Rate}}}}
и вместо экономии места говорят об экономии скорости передачи данных , которая определяется как снижение скорости передачи данных по сравнению со скоростью передачи несжатых данных:
- D а т а р а т е S а v я п г знак равно 1 - C о м п р е s s е d D а т а р а т е U п c о м п р е s s е d D а т а р а т е {\ displaystyle {\ rm {Data \; Rate \; Saving}} = 1 - {\ frac {\ rm {Compressed \; Data \; Rate}} {\ rm {Uncompressed \; Data \; Rate}}}}
Например, несжатые песни в формате CD имеют скорость передачи данных 16 бит / канал x 2 канала x 44,1 кГц ≅ 1,4 Мбит / с, тогда как файлы AAC на iPod обычно сжимаются до 128 кбит / с, что дает коэффициент сжатия 10,9 , для экономии скорости передачи данных 0,91, или 91%.
Когда скорость передачи несжатых данных известна, степень сжатия можно вывести из скорости передачи сжатых данных.
Без потерь против потерь
Сжатие без потерь оцифрованных данных, таких как видео, оцифрованная пленка и звук, сохраняет всю информацию, но обычно не обеспечивает более высокую степень сжатия, чем 2: 1, из-за внутренней энтропии данных. Алгоритмы сжатия, которые обеспечивают более высокие коэффициенты, либо несут очень большие накладные расходы, либо работают только для определенных последовательностей данных (например, сжатие файла в основном с нулями). Напротив, сжатие с потерями (например, JPEG для изображений или MP3 и Opus для аудио) может достичь гораздо более высоких коэффициентов сжатия за счет снижения качества, например, потоковая передача звука через Bluetooth, поскольку визуальные или звуковые артефакты сжатия из-за потери важной информации представлены. Для преобразования видео 1080i в транспортный поток MPEG со скоростью 20 Мбит / с требуется коэффициент сжатия не менее 50: 1 .
Использует
Степень сжатия данных может служить мерой сложности набора данных или сигнала. В частности, он используется для аппроксимации алгоритмической сложности . Он также используется, чтобы увидеть, какую часть файла можно сжать без увеличения его исходного размера.
Рекомендации
внешние ссылки
<img src="https://en.wikipedia.org/wiki/Special:CentralAutoLogin/start?type=1x1" alt="" title="">Все, что вы когда-либо хотели знать о степени сжатия
Мы здесь, чтобы ответить на несколько вопросов - что такое коэффициенты сжатия, как они влияют на создание цифровых фильмов и какое отношение они имеют к кодекам?
В этой статье мы разоблачим загадочную степень сжатия, разберем, как вы можете извлечь из нее полезный смысл, а затем покажем вам несколько приемов оценки кодеков, чтобы определить лучший вариант для вашей продукции.
Основы сжатия данных

Изображение предоставлено Avid.
Мы уже рассказывали об основах компрессии, так что здесь мы быстро их рассмотрим.
Все виды сжатия подразделяются на два типа: сжатие с потерями (которое отбрасывает информацию ради размера файла или скорости передачи данных) или сжатие без потерь (которое временно сжимает данные во время процесса кодирования, чтобы обеспечить полное или почти полное воссоздание несжатый набор данных при декодировании). Кадры, записанные без использования какого-либо алгоритма сжатия, считаются несжатыми.
Теперь нам нужно немного рассказать о компьютерных науках 101, прежде чем углубляться в степени сжатия. (Обещаю, это будет быстро.)
Фундаментальная частица информационного мира называется «бит» и обозначается строчной буквой «b». (Да, дело важное). На этом уровне информация представлена в самой простой двоичной форме - 1 или 0.
8 бит составляют «Байт» (произносится как «укус»), представленный заглавной буквой «В». На этом и на каждом последующем уровне представляемые данные становятся более сложными.
Килобайт составляет 1000 байт. Его не следует путать с «килобитом» («Кбайт»), который составляет 1000 байт. Поскольку байты являются 8-битными единицами, килобайт фактически равен 1024 битам.
Одна тысяча килобайт составляет мегабайт или МБ. (Опять же, не путать с «Мегабит» - «Мб.»)
Эта тенденция продолжается - тысяча мегабайт дает гигабайт и так далее, но это все, что нам нужно для этой статьи. Если вы хотите узнать больше, WhatsAByte.com - отличный ресурс.
А теперь давайте перейдем к степени сжатия.
Степень сжатия
Коэффициенты сжатия - это простое числовое представление «мощности сжатия» конкретных кодеков или методов сжатия. Они являются бесценным сокращением, потому что предлагают значительно упрощенное описание качества полученных данных, видеоматериалов или аудио, которые вы собираетесь сжать.
Так что это такое?
Изображение предоставлено Blackmagic.
Два числа в степени сжатия относятся к сжатому и сжатому сжатию.несжатый размер данных. Первое число представляет мощность сжатия, а второе (обычно просто «1») относится к общему размеру несжатых данных.
Если вы когда-нибудь захотите узнать степень сжатия для любых данных, которые вы сжимаете, вот формула: Степень сжатия = Размер без сжатия / размер со сжатием
Если вам нужно знать экономию места на диске, предоставляемую данным кодеком, две простые корректировки формулы, и вы устанавливаете: Экономия места = 1 - (сжатый размер / несжатый размер)
Таким образом, файл размером 10 МБ сжимается до 2 МБ с использованием кодека X, что дает нам степень сжатия 5: 1 .Чтобы найти экономию, мы просто вводим наши значения в формулу.
Экономия места = 1 - (2/10) -> = 1 - (.2) -> = .08 -> .08 * 100 = 80
Итак, кодек X предлагает нам экономию памяти на 80 процентов по сравнению с несжатыми данными. Довольно изящно.
И что теперь?
Выбор кодека
Изображение предоставлено Apple.
Теперь, когда у нас есть основы, как вы решаете, какой кодек лучше всего подходит для вашего проекта? Давайте посмотрим на параметры, которые инженеры используют при разработке алгоритмов сжатия, но давайте подойдем к ним как к стрелкам и редакторам.
Вопросы о себе о проекте:
- Скорость: каковы сроки реализации проекта?
- Степень сжатия: вам нужны файлы более высокого качества или меньшего размера?
- Сложность: будут ли дополнительные кодеки создавать ненужную сложность?
- Space: Можете ли вы эффективно записывать, создавать резервные копии и архивировать то, что вам нужно?
- Задержка: вы собираетесь воспроизводить в реальном времени?
- Взаимодействие: Потребуется ли перекодирование кодека для вашей системы редактирования?
Теперь, когда мы получили представление о конкретных потребностях нашего производства, что еще нам нужно сделать перед выбором кодека?
Помимо оценки мощности сжатия кодека, мы можем использовать все, что мы узнали до сих пор, чтобы делать прогнозы хранилища для данных, которые мы будем сжимать для всей съемки.Это дает множество преимуществ - от выбора между двумя кодеками одного класса до знания того, сколько жестких дисков вам понадобится для резервного копирования и архивирования.
Допустим, мы оценили потребности нашего производства и склоняемся к записи видео с использованием ProRes 422 HQ или DNxHD 145 для нашего проекта 1920 × 1080, 29,97 кадров в секунду. При таком разрешении и частоте кадров ProRes 422 имеет скорость передачи данных 220 Мбит / с (мегабит в секунду), а у Avid DNxHD - 145 Мбит / с.
Итак, используя простую математику, мы можем предсказать, насколько большой будет наш 1-часовой видеоролик для интервью, прежде чем мы когда-либо начнем прокатиться.
Для ProRes:
220 Мбит / с = 220 000 000 бит в (/) секунду
220 000 000 бит / секунду * 60 = 13 200 000 бит / минуту
13 200 000 бит / минуту * 60 = 792 000 000 000 бит / час.
792 000 000 000 бит / час / 8 = 99 000 000 000 байтов / час
99 000 000 000 байтов / 1 000 = 99 000 000 мегабайт / час
99 000 000 мегабайт / 1 000 = 99 гигабайт / час
Для DNxHD:
145 Мбит / с = 145 000 000 бит в секунду
145 000 000 бит в секунду * 60 = 8 700 000 000 бит в минуту
87 000 бит в минуту * 60 = 522 000 000 000 бит в час.
522000000000 бит / час / 8 = 65 250 000 000 байтов / час
65 250 000 000 байтов / 1000 = 65 250 000 мегабайт / час
65 250 000 мегабайт / 1000 = 65,25 гигабайт / час
Итак, наше часовое интервью приведет к получению файла размером примерно 99 гигабайт с ProRes 422 HQ и около 65 гигабайт для DNxHD 145.
Теперь наш выбор прост. Мы просто возвращаемся к вопросам, которые мы задали себе недавно о нашем конкретном производстве, чтобы решить, является ли экономия ~ 35 ГБ / час DNxHD более или менее важной, чем дает нам приблизительное увеличение скорости передачи данных 422 HQ на 50%.
Является ли наше часовое интервью для 30-секундной веб-рекламы? Если это так, DNxHD должен предлагать качество изображения почти такое же, как 422 HQ, но после завершения он займет на 40 процентов меньше памяти, что делает его явным победителем в этом случае.
Что, если интервью - лишь одно из нескольких десятков полнометражных документальных фильмов, которые вы планируете продавать на фестивале? В этом случае вы должны сделать ставку на максимальное качество изображения по сравнению с хранилищем (в рамках заданных параметров), и более высокая скорость передачи данных ProRes 422 HQ на 50 процентов полностью соответствует вашим потребностям.
Обладая лишь небольшими базовыми знаниями в области науки, лежащей в основе методов сжатия, используемых в современных кодеках, мы можем оценить потребности нашей продукции, проверить кодеки на соответствие производственным потребностям, а затем принять обоснованное решение в зависимости от объема проекта. Довольно удобный материал, если вы спросите меня.
Изображение на обложке с kayan_photo.
Ищете дополнительную информацию о данных и цифровом кинопроизводстве? Ознакомьтесь с этими статьями.
.Как работает сжатие файлов | HowStuffWorks
В нашем предыдущем примере мы выбрали все повторяющиеся слова и поместили их в словарь. Для нас это наиболее очевидный способ составления словаря. Но программа сжатия видит это совершенно иначе: в ней нет концепции отдельных слов - она только ищет шаблоны. А чтобы максимально уменьшить размер файла, он тщательно выбирает, какие шаблоны включить в словарь.
Если подойти к фразе с этой точки зрения, мы получим совершенно другой словарь.
Объявление
Если бы программа сжатия просканировала фразу Кеннеди, первая повторяемость, с которой она столкнется, будет состоять всего из пары букв. В словах «не спрашивайте, что у вас» есть повторяющийся узор из буквы «т», за которой следует пробел - в «не» и «что». Если программа сжатия записала это в словарь, она могла бы записывать «1» каждый раз, когда за буквой «t» следовало пробел. Но в этой короткой фразе этого шаблона недостаточно, чтобы его можно было использовать, поэтому программа в конечном итоге его перезапишет.
Следующее, что может заметить программа, - это «ou», которое встречается как в «your», так и в «country». Если бы это был более длинный документ, запись этого шаблона в словарь могла бы сэкономить много места - «ou» - довольно распространенная комбинация в английском языке. Но по мере того, как программа сжатия прорабатывала это предложение, она быстро обнаружила лучший выбор для словарной статьи: не только повторяется «ou», но и повторяются целые слова «your» и «country», и они фактически повторяются. вместе, как словосочетание «ваша страна.«В этом случае программа заменит словарную статью для« ou »записью« ваша страна ».
Фраза «может сделать для» также повторяется, один раз за ней следует «ваш» и один раз за ней следует «вы», что дает нам повторяющийся образец «могу сделать для вас». Это позволяет нам записывать 15 символов (включая пробелы) с одним числовым значением, в то время как «ваша страна» позволяет нам записывать только 13 символов (с пробелами) с одним числовым значением, поэтому программа перезаписывает запись «ваша страна» как просто «r страна, а затем напишите отдельную запись для "может сделать для вас.«Программа действует таким образом, собирая все повторяющиеся биты информации и затем вычисляя, какие шаблоны следует записать в словарь. Эта способность переписывать словарь является« адаптивной »частью алгоритма LZ на основе адаптивного словаря . То, как программа действительно это делает, довольно сложно, как вы можете видеть из обсуждений на Data-Compression.com.
Независимо от того, какой конкретный метод вы используете, эта система глубокого поиска позволяет сжимать файл намного эффективнее, чем если бы вы просто выбирали слова.Используя шаблоны, которые мы выбрали выше, и добавив «__» для пробелов, мы получили более крупный словарь:
- спросите__
- what__
- you
- r__country
- __can__do__for__you
И это меньшее предложение: «1not__2345 __ - __ 12354»
Предложение теперь занимает 18 единиц памяти, а наш словарь занимает 41 единицу.Таким образом, мы уменьшили общий размер файла с 79 до 59 единиц! Это всего лишь один способ сжатия фразы, и не обязательно самый эффективный. (Посмотрим, сможете ли вы найти лучший способ!)
Так насколько хороша эта система? Коэффициент уменьшения файла зависит от ряда факторов, включая тип файла, размер файла и схему сжатия.
В большинстве языков мира определенные буквы и слова часто встречаются вместе в одном шаблоне.Из-за такой высокой степени избыточности текстовые файлы , очень хорошо сжимаются. Уменьшение на 50 процентов и более типично для текстового файла хорошего размера. Большинство языков программирования также очень избыточны, потому что они используют относительно небольшой набор команд, которые часто идут вместе в заданном шаблоне. Файлы, содержащие много уникальной информации, например графику или файлы MP3, не могут быть сильно сжаты с помощью этой системы, потому что они не повторяют многие шаблоны (подробнее об этом в следующем разделе).
Если в файле много повторяющихся шаблонов, скорость уменьшения обычно увеличивается с размером файла. Вы можете убедиться в этом, просто взглянув на наш пример - если бы у нас было больше речи Кеннеди, мы могли бы чаще обращаться к шаблонам в нашем словаре и таким образом получать больше от файлового пространства каждой записи. Кроме того, в ходе более продолжительной работы могут появиться более распространенные шаблоны, что позволит нам создать более эффективный словарь.
Эта эффективность также зависит от конкретного алгоритма, используемого программой сжатия.Некоторые программы особенно подходят для улавливания шаблонов в файлах определенных типов и поэтому могут сжимать их более лаконично. У других есть словари в словарях, которые могут эффективно сжимать файлы большего размера, но не файлы меньшего размера. Хотя все программы сжатия подобного типа работают с одной и той же основной идеей, на самом деле существует множество вариантов их выполнения. Программисты всегда пытаются построить лучшую систему.
.Сжатие данных | Что, как и почему
KS3 Ресурсы сжатия (14-16 лет)
- Редактируемая презентация урока в PowerPoint
- Редактируемые раздаточные материалы для исправлений
- Глоссарий, охватывающий ключевые термины модуля
- Тематические интеллектуальные карты для визуализации ключевых концепций
- Карточки для печати, помогающие учащимся активнее вспоминать и повторять на основе уверенности Викторина с сопровождающим ключом для проверки знаний и понимания модуля
A-Level Типы данных, структуры данных и алгоритмы (16-18 лет)
- Редактируемая презентация урока в PowerPoint
- Редактируемые раздаточные материалы для исправлений
- Глоссарий, охватывающий ключевые термины модуля
- Тематические интеллектуальные карты для визуализации ключевых понятий
- Печатные карточки, помогающие учащимся активнее вспоминать и повторять на основе уверенности
- Викторина с сопровождающим ключом для проверки знаний и понимания модуля
Что такое сжатие данных?
Сжатие данных используется везде.Многие типы файлов используют сжатые данные. Без сжатия данных 3-минутная песня была бы размером более 100 МБ, а 10-минутное видео было бы размером более 1 ГБ. Сжатие данных сжимает большие файлы в гораздо меньшие. Это достигается путем избавления от ненужных данных при сохранении информации в файле.
Сжатие данных можно выразить как уменьшение количества битов, необходимых для иллюстрации данных. Сжатие данных может сохранить емкость хранилища, ускорить передачу файлов и минимизировать затраты на аппаратное хранилище и емкость сети.
Как работает сжатие?
Сжатие выполняется программой, которая использует процедуру для определения того, как уменьшить размер данных.
Сжатие текста может быть выполнено путем удаления ненужных символов, встраивания повторяющегося символа для указания повторяющихся символов и замены часто встречающейся битовой строки на меньшую битовую строку. Сжатие данных может сократить текстовый файл до 50% или до процента, еще меньшего от его исходного размера.
Для передачи данных сжатие может выполняться в содержимом данных или в блоке передачи в целом.Когда данные необходимо передать через Интернет, файлы большего размера можно отправлять в формате ZIP, GZIP или другом сжатом формате.
Какова цель сжатия?
Цель сжатия - уменьшить размер файла, сообщения или любого другого фрагмента данных. Сжатие данных может значительно уменьшить объем дискового пространства, занимаемого файлом. Если бы у нас был файл размером 10 МБ и мы могли бы уменьшить его до 5 МБ, мы бы сжали его со степенью сжатия 2, так как это половина размера исходного файла.Если бы мы сжали файл размером 10 МБ до 1 МБ, у него был бы коэффициент сжатия 10, потому что новый файл в 10 раз меньше оригинала. Чем выше степень сжатия, тем лучше сжатие. Благодаря сжатию администраторы экономят деньги и время, которые в противном случае были бы потрачены на хранение.
Сжатие улучшает работу хранилища резервных копий, а также влияет на сокращение объема данных основного хранилища. Сжатие продолжит играть важную роль в сокращении объема данных, поскольку объем данных продолжает свой экспоненциальный рост.
Практически любой тип файла можно сжать, но обязательно следовать передовым методам при выборе файлов для сжатия. Например, некоторые файлы уже сжаты, поэтому их сжатие не окажет существенного влияния.
Методы сжатия данных
Есть два вида сжатия: без потерь и с потерями.
Сжатие с потерями теряет данные, в то время как сжатие без потерь сохраняет все данные. Благодаря сжатию без потерь мы не избавляемся от данных.Вместо этого метод основан на поиске более разумных способов кодирования данных. С помощью сжатия с потерями мы избавляемся от данных, поэтому нам нужно отличать данные от информации.
Сжатие без потерь позволяет восстановить исходный размер файла без потери единственного бита данных, когда файл не сжат. Сжатие без потерь - это обычный подход, применяемый к исполняемым файлам, а также к текстовым файлам и файлам электронных таблиц, где потеря слов или чисел может изменить информацию.Сжатие без потерь может сжимать данные при наличии избыточности. Следовательно, сжатие без потерь использует преимущества избыточности данных.
Сжатие с потерями безвозвратно удаляет лишние, незначительные или незаметные биты данных. Сжатие с потерями подходит для графики, аудио, видео и изображений, где удаление некоторых битов данных практически не влияет на иллюстрацию контента. При сжатии с потерями сообщения становятся более эффективными за счет избавления от нежелательных данных.Сжатие с потерями уменьшает размер данных, сохраняя при этом больше информации.
Сжатие графического изображения может быть с потерями или без потерь. Форматы файлов графических изображений обычно разрабатываются для сжатия информации, поскольку файлы обычно имеют большой размер. JPEG - это формат файла изображения, который способствует сжатию изображений с потерями. Такие форматы, как GIF и PNG, используют сжатие без потерь.
.zip - Как определить степень сжатия DEFLATE?
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
Сжатие данных / оценка эффективности сжатия - Викиучебники, открытые книги для открытого мира
Из Wikibooks, открытые книги для открытого мира
Перейти к навигации Перейти к поиску| Найдите Сжатие данных / оценка эффективности сжатия в одном из родственных проектов Викиучебника: Викиучебник не имеет страницы с таким точным названием. Другие причины, по которым это сообщение может отображаться:
|
Что такое степень сжатия? (с изображениями)
Степень сжатия относится к объему или количеству топливовоздушной смеси, которое камера сгорания в двигателе внутреннего сгорания может удерживать, когда она пуста и имеет самый большой размер по сравнению с объемом, который она удерживает, когда смесь сжимается до минимально возможного размера. Это соотношение применяется как к двигателям внутреннего сгорания, которые используются в современных автомобилях, так и к редко используемым двигателям внешнего сгорания. Как дизельные, так и газовые двигатели имеют одинаковую степень сжатия, хотя конструкция дизельного двигателя способствует более высокой степени сжатия.Двигатели с более высокой степенью сжатия обычно считаются лучшими, поскольку они создают большую мощность, сохраняя при этом эффективность.
Дизельные двигатели более эффективны, чем бензиновые, отчасти потому, что они используют высокую степень сжатия для воспламенения топлива.Чтобы рассчитать степень сжатия двигателя, инженер сначала вычислит объем, который цилиндр двигателя может удерживать, когда поршень находится в нижней части цилиндра. За один ход двигателя поршень движется снизу вверх и сжимает топливовоздушную смесь. После определения объема цилиндра, когда поршень опущен и, следовательно, еще не сжат, инженеру необходимо будет вычислить объем, когда поршень поднят и топливовоздушная смесь сжата.Например, такое соотношение, как 13: 1, означает, что двигатель удерживает в 13 раз больший объем, когда поршень опущен, чем когда он сжат. Количество топливовоздушной смеси не меняется, а просто вдавливается в значительно меньшее пространство, чтобы создать большой взрыв.
Степень сжатия применяется к обоим двигателям внутреннего сгорания, например, к двигателям современных автомобилей.Дизельные двигатели используют сжатие для создания температуры, при которой дизельное топливо воспламеняет топливно-воздушную смесь, которая создает необходимую мощность для движения автомобиля вперед. Высокая степень сжатия в газовых двигателях часто вызывает проблему, известную как детонация.С другой стороны, дизельные двигатели для нормальной работы рассчитаны на высокую степень сжатия. Передаточное число 13: 1 считается высоким для газового двигателя, в то время как дизельный двигатель может варьироваться от 14: 1 до 23: 1 в зависимости от типа.
Высокая степень сжатия приводит к увеличению мощности за счет сжатия воздуха и топлива даже сильнее, чем в среднем, и, таким образом, вызывает более мощный взрыв.Плотная упаковка топливовоздушной смеси способствует лучшему смешиванию воздуха и топлива, а при взрыве большая часть смеси испаряется. Более сильное испарение является признаком более высокого теплового КПД, что означает, что двигатель работает лучше, не используя слишком много дополнительной энергии для получения этой мощности.
Недостатком более высокой степени сжатия в газовом двигателе является возможность детонации или звона в двигателе.Это происходит, когда происходит более сильный взрыв, чем требуется, и поршень слишком быстро перемещается вверх или вниз. В результате возникает громкий стук, и, если его не устранить, продолжительный стук двигателя может привести к необратимому повреждению двигателя. Автомобили, использующие бензин с более высоким октановым числом или датчиком детонации, могут использовать более высокую степень сжатия, но все же не могут соответствовать высокой степени дизельного двигателя.
.